

Einführung in Map Join in Hive
Map Join ist eine Funktion, die in Hive-Abfragen verwendet wird, um die Effizienz in Bezug auf die Geschwindigkeit zu erhöhen. Join ist eine Bedingung, die zum Kombinieren der Daten aus 2 Tabellen verwendet wird. Wenn wir also einen normalen Join ausführen, wird der Job an eine Map-Reduce-Aufgabe gesendet, die die Hauptaufgabe in zwei Phasen aufteilt - "Map Stage" und "Reduce Stage". Die Map-Stufe interpretiert die Eingabedaten und gibt die Ausgabe in Form von Schlüssel-Wert-Paaren an die Reduktionsstufe zurück. Dies geht als nächstes durch die Mischphase, wo sie sortiert und kombiniert werden. Der Reduzierer nimmt diesen sortierten Wert und schließt den Verknüpfungsjob ab.
Eine Tabelle kann vollständig in einem Mapper und ohne Verwendung des Map / Reducer-Prozesses in den Speicher geladen werden. Es liest die Daten aus der kleineren Tabelle, speichert sie in einer speicherinternen Hash-Tabelle und serialisiert sie dann in eine Hash-Speicherdatei, wodurch die Zeit erheblich verkürzt wird. Es ist auch als Map Side Join in Hive bekannt. Grundsätzlich müssen Verknüpfungen zwischen zwei Tabellen ausgeführt werden, indem nur die Kartenphase verwendet und die Reduzierungsphase übersprungen wird. Eine zeitliche Verringerung der Berechnung Ihrer Abfragen kann beobachtet werden, wenn sie regelmäßig kleine Tabellenverknüpfungen verwenden.
Syntax für Map Join in Hive
Wenn wir eine Join-Abfrage mit Map-Join durchführen möchten, müssen wir in der folgenden Anweisung ein Schlüsselwort "/ * + MAPJOIN (b) * /" angeben:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
In diesem Beispiel müssen zwei Tabellen mit den Namen Tabellenname1 und Tabellenname2 mit zwei Spalten erstellt werden: emp_id und emp_name. Eine sollte eine größere und eine kleinere Datei sein.
Bevor wir die Abfrage ausführen, müssen wir die folgende Eigenschaft auf true setzen:
hive.auto.convert.join=true
Die Verknüpfungsabfrage für die Kartenverknüpfung ist wie oben geschrieben und das Ergebnis ist:
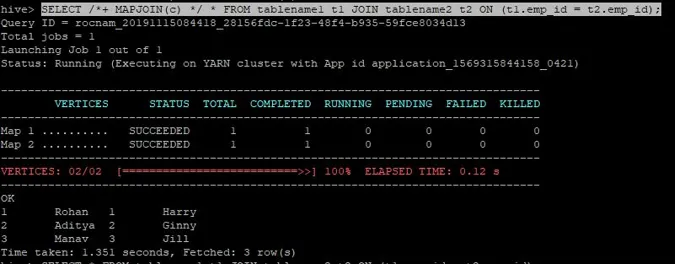
Die Abfrage wurde in 1.351 Sekunden abgeschlossen.
Beispiele für Map Join in Hive
Hier sind die folgenden Beispiele zu nennen
1. Map Join Beispiel
In diesem Beispiel erstellen wir zwei Tabellen mit den Namen table1 und table2 mit 100 bzw. 200 Datensätzen. Sie können den folgenden Befehl und die folgenden Screenshots zur Ausführung verwenden:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

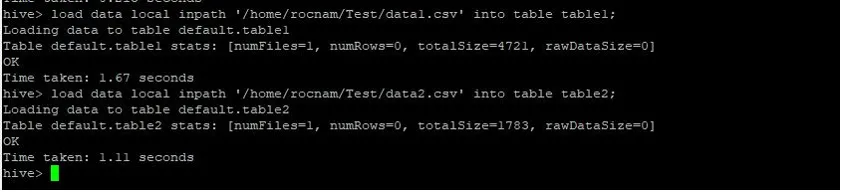
Jetzt laden wir die Datensätze mit den folgenden Befehlen in beide Tabellen:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Lassen Sie uns eine normale Map-Join-Abfrage für ihre IDs durchführen, wie unten gezeigt, und die dafür benötigte Zeit überprüfen:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
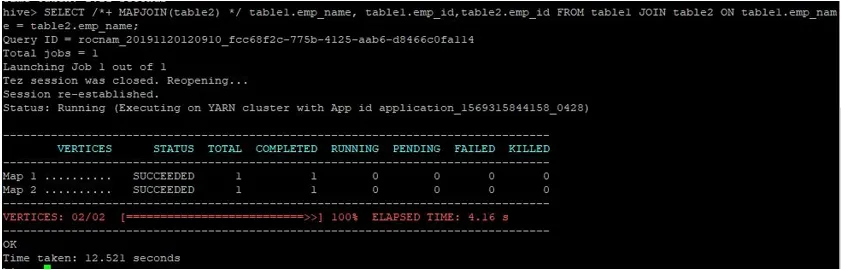
Wie wir sehen können, dauerte eine normale Map-Join-Abfrage 12.521 Sekunden.
2. Beispiel für einen Bucket-Map-Join
Verwenden wir jetzt den Bucket-Map-Join, um dasselbe auszuführen. Es gibt einige Einschränkungen, die beim Bucketing beachtet werden müssen:
- Die Buckets können nur dann miteinander verbunden werden, wenn die Gesamtzahl der Buckets einer Tabelle ein Vielfaches der Anzahl der Buckets in der anderen Tabelle beträgt.
- Es müssen Buckettabellen vorhanden sein, um das Buckett auszuführen. Lasst uns also dasselbe erschaffen.
Im Folgenden sind die Befehle zum Erstellen von Buckettabellen table1 und table2 aufgeführt:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Wir werden die gleichen Datensätze von table1 auch in diese mit Buckets versehenen Tabellen einfügen:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
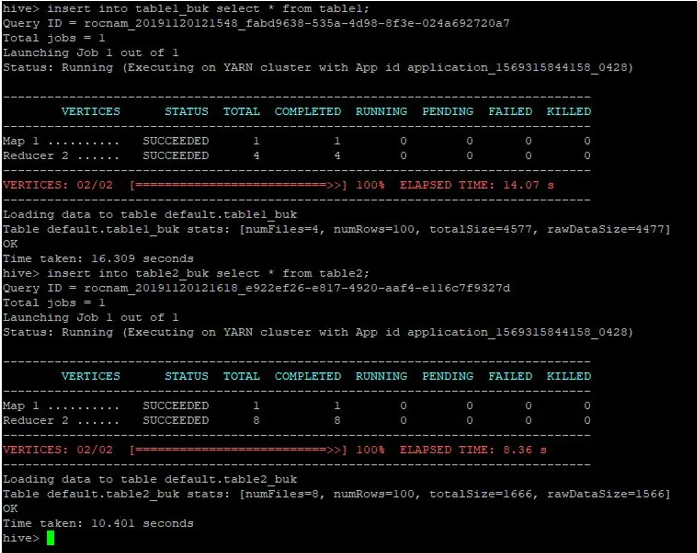
Nachdem wir nun unsere 2 Bucketed-Tabellen haben, lassen Sie uns einen Bucket-Map-Join für diese durchführen. Die erste Tabelle enthält 4 Buckets, während in der zweiten Tabelle 8 Buckets in derselben Spalte erstellt wurden.
Damit die Bucket-Map-Join-Abfrage funktioniert, sollten wir die Eigenschaft below im Hive auf true setzen:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
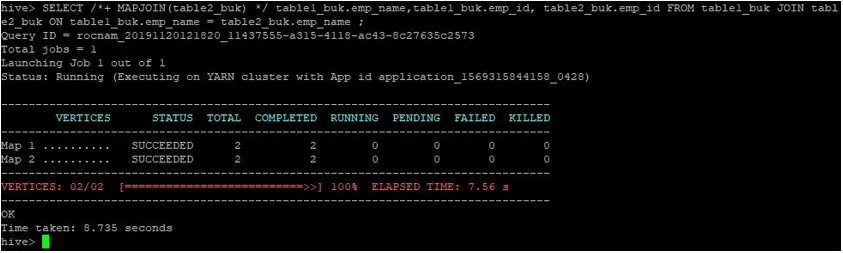
Wie wir sehen können, wurde die Abfrage in 8.735 Sekunden abgeschlossen, was schneller ist als ein normaler Karten-Join.
3. Sortiere Merge Bucket Map Join Beispiel (SMB)
SMB kann für mit Buckets versehene Tabellen mit der gleichen Anzahl von Buckets ausgeführt werden und wenn die Tabellen nach Join-Spalten sortiert und mit Buckets versehen werden müssen. Die Mapper-Ebene verbindet diese Buckets entsprechend.
Wie beim Bucket-Map-Join gibt es 4 Buckets für Tabelle1 und 8 Buckets für Tabelle2. In diesem Beispiel erstellen wir eine weitere Tabelle mit 4 Buckets.
Um eine SMB-Abfrage auszuführen, müssen die folgenden Struktur-Eigenschaften wie folgt festgelegt werden:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Um einen SMB-Join durchzuführen, müssen die Daten nach den Join-Spalten sortiert werden. Daher überschreiben wir die Daten in Tabelle 1 wie folgt:
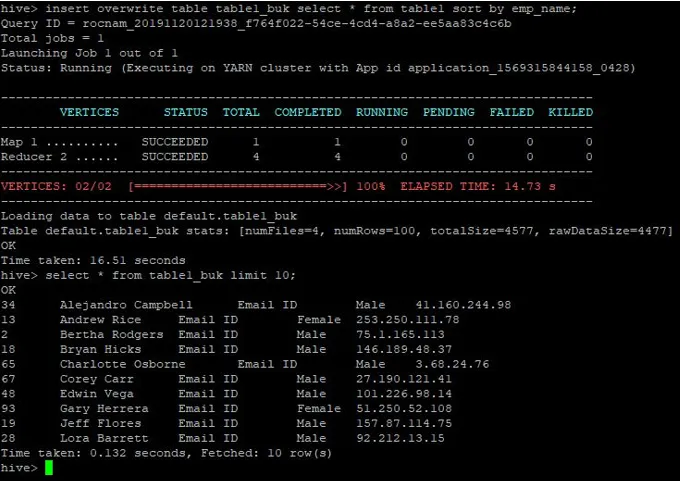
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Die Daten sind jetzt sortiert, was im folgenden Screenshot zu sehen ist:
Wir werden auch Daten in Tabelle 2 wie folgt überschreiben:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Lassen Sie uns den Join für die obigen 2 Tabellen wie folgt durchführen:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
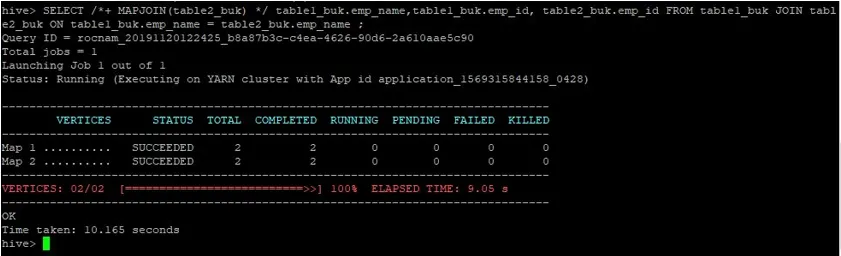
Wir können sehen, dass die Abfrage 10, 165 Sekunden dauerte, was wiederum besser ist als ein normaler Karten-Join.
Erstellen wir nun eine weitere Tabelle für table2 mit 4 Buckets und den gleichen Daten, sortiert nach emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
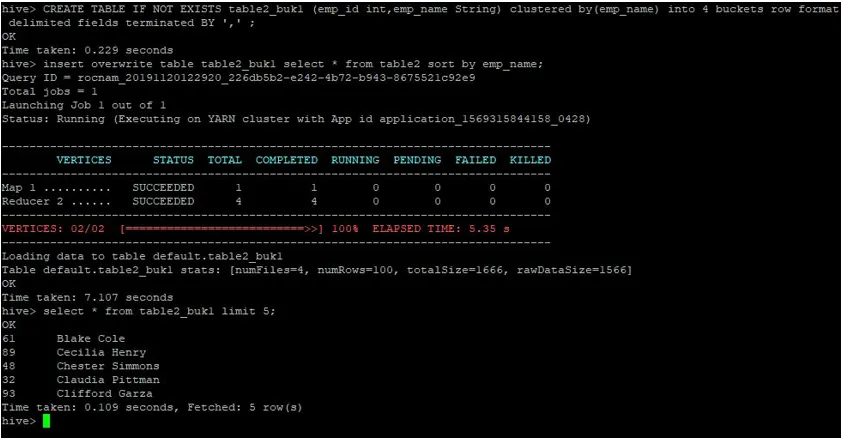
Angesichts der Tatsache, dass wir nun beide Tabellen mit 4 Buckets haben, lassen Sie uns erneut eine Join-Abfrage durchführen.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Die Abfrage dauerte erneut 8, 851 Sekunden schneller als die normale Map-Join-Abfrage.
Vorteile
- Map Join reduziert die Zeit, die für das Sortieren und Zusammenführen von Prozessen im Shuffle benötigt wird, und reduziert die Anzahl der Phasen, wodurch auch die Kosten minimiert werden.
- Es erhöht die Leistungseffizienz der Aufgabe.
Einschränkungen
- Dieselbe Tabelle / derselbe Alias darf nicht zum Verknüpfen verschiedener Spalten in derselben Abfrage verwendet werden.
- Map Join-Abfrage kann Full Outer Joins nicht in Map Side Joins konvertieren.
- Map-Join kann nur ausgeführt werden, wenn eine der Tabellen klein genug ist, um in den Speicher eingepasst zu werden. Daher kann es nicht ausgeführt werden, wenn die Tabellendaten sehr groß sind.
- Ein linker Join kann nur dann mit einem Map-Join durchgeführt werden, wenn die rechte Tabelle klein ist.
- Eine rechte Verknüpfung zu einer Map-Verknüpfung ist nur möglich, wenn die linke Tabellengröße klein ist.
Fazit
Wir haben versucht, die bestmöglichen Punkte von Map Join in Hive aufzunehmen. Wie wir oben gesehen haben, funktioniert der Map-Side-Join am besten, wenn eine Tabelle weniger Daten enthält, sodass der Job schnell abgeschlossen wird. Die für die hier gezeigten Abfragen benötigte Zeit hängt von der Größe des Datensatzes ab, daher dient die hier gezeigte Zeit nur zur Analyse. Map Join kann einfach in Echtzeitanwendungen implementiert werden, da wir über große Datenmengen verfügen und so den E / A-Verkehr im Netzwerk reduzieren.
Empfohlene Artikel
Dies ist eine Anleitung zur Map Join in Hive. Hier werden die Beispiele für Map Join in Hive sowie die Vor- und Nachteile erläutert. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- Schließt sich Hive an
- Integrierte Funktionen
- Was ist ein Bienenstock?
- Hive-Befehle