
Einführung in die Data Warehouse-Architektur
- Ein Data Warehouse ist ein Speicherort, der Sammlungen verschiedener Arten von Daten enthält, die aus verschiedenen Arten von Quellen stammen.
- Der gesamte Prozess, in dem externe Datenquellen erfasst, verarbeitet, gespeichert und zu verwendbaren Informationen analysiert werden, findet in einer Reihe von Systemen statt, die durch ein einziges Schema, die so genannte Data Warehouse-Architektur, vereinheitlicht werden.
Data Warehouse-Architektur

Die Data Warehouse-Architektur besteht im Allgemeinen aus drei Ebenen.
- Spitzengruppe
- Middle Tier
- Bottom Tier
Spitzengruppe
- Die oberste Ebene besteht aus dem clientseitigen Front-End der Architektur.
- Die transformierten und logisch angewendeten Informationen, die im Data Warehouse gespeichert sind, werden in dieser Schicht für Geschäftszwecke verwendet und erfasst.
- Für die Generierung der gewünschten Informationen stehen verschiedene Tools zur Berichterstellung und -analyse zur Verfügung.
- Hier wird Data Mining durchgeführt, das heutzutage zu einem großen Trend geworden ist.
- Alle Dokumente, Kosten und Funktionen der Anforderungsanalyse, die einen gewinnorientierten Geschäftsabschluss bestimmen, basieren auf diesen Tools, die die Data Warehouse-Informationen verwenden.
Middle Tier
- Die mittlere Schicht besteht aus den OLAP-Servern
- OLAP ist ein Online Analytical Processing Server
- OLAP wird verwendet, um Geschäftsanalysten und Managern Informationen bereitzustellen
- Da es sich in der mittleren Ebene befindet, interagiert es zu Recht mit den Informationen in der unteren Ebene und gibt die Erkenntnisse an die Tools der oberen Ebene weiter, die die verfügbaren Informationen verarbeiten.
- In der Data Warehouse-Architektur wird meist relationales oder mehrdimensionales OLAP verwendet.
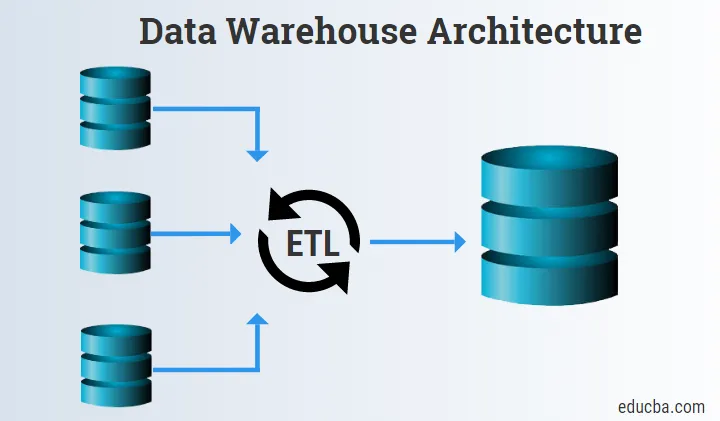
Bottom Tier
Die unterste Ebene besteht hauptsächlich aus den Datenquellen, dem ETL-Tool und dem Data Warehouse.
1. Datenquellen
Die Datenquellen bestehen aus den Quelldaten, die erfasst und den Staging- und ETL-Tools zur weiteren Verarbeitung bereitgestellt werden.
2. ETL-Tools
- ETL-Tools sind sehr wichtig, da sie bei der Kombination von Logik, Rohdaten und Schema helfen und die Informationen in das Data Warehouse oder die Data Marts laden.
- Manchmal lädt ETL die Daten in die Data Marts und speichert sie dann in Data Warehouse. Dieser Ansatz wird als Bottom-Up-Ansatz bezeichnet.
- Der Ansatz, bei dem ETL Informationen direkt in das Data Warehouse lädt, wird als Top-Down-Ansatz bezeichnet.
Unterschied zwischen Top-Down-Ansatz und Bottom-Up-Ansatz
| Top-Down-Ansatz | Bottom-Up-Ansatz |
| Bietet eine eindeutige und konsistente Ansicht von Informationen, da Informationen aus dem Data Warehouse zum Erstellen von Data Marts verwendet werden | Berichte können einfach erstellt werden, da zuerst Data Marts erstellt werden und die Interaktion mit Data Marts relativ einfach ist. |
| Starkes Modell und daher von großen Unternehmen bevorzugt | Nicht so stark, aber Data Warehouse kann erweitert und die Anzahl der Data Marts kann erstellt werden |
| Zeit, Kosten und Wartung sind hoch | Zeit, Kosten und Wartung sind gering. |
Data Marts
- Data Mart ist auch eine Speicherkomponente, die zum Speichern von Daten einer bestimmten Funktion oder eines Teils verwendet wird, die bzw. der von einer einzelnen Behörde mit einem Unternehmen in Zusammenhang steht.
- Data Mart sammelt die Informationen aus Data Warehouse, und daher kann man sagen, dass Data Mart die Teilmenge der Informationen in Data Warehouse speichert.
- Data Marts sind flexibel und klein.
3. Data Warehouse
- Data Warehouse ist die zentrale Komponente der gesamten Data Warehouse-Architektur.
- Es fungiert als Repository zum Speichern von Informationen.
- Große Datenmengen werden im Data Warehouse gespeichert.
- Diese Informationen werden von mehreren Technologien wie Big Data verwendet, bei denen große Teilmengen von Informationen analysiert werden müssen.
- Data Mart ist auch ein Modell von Data Warehouse.
Verschiedene Schichten der Data Warehouse-Architektur
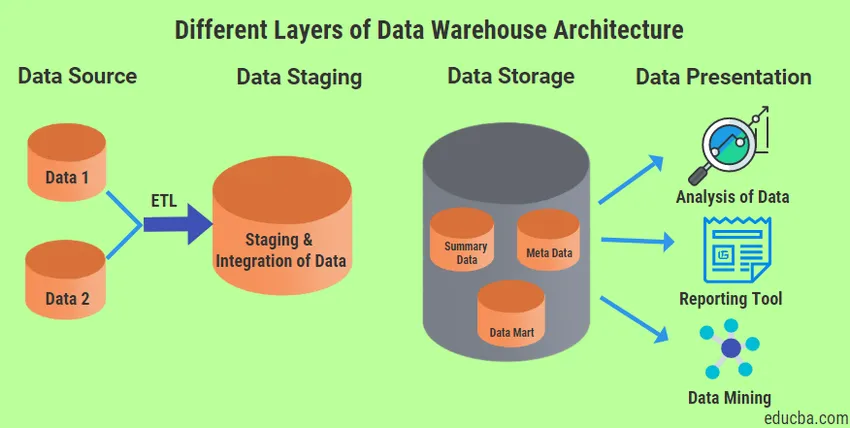
Es gibt vier verschiedene Arten von Layern, die in der Data Warehouse-Architektur immer vorhanden sind.
1. Datenquellenebene
- Die Datenquellenebene ist die Ebene, auf der die Daten der Quelle angetroffen und anschließend für die gewünschten Vorgänge an die anderen Ebenen gesendet werden.
- Die Daten können von beliebiger Art sein.
- Die Quelldaten können Datenbanken, Tabellenkalkulationen oder andere Arten von Textdateien sein.
- Die Quelldaten können ein beliebiges Format haben. Wir können nicht erwarten, Daten mit demselben Format zu erhalten, da die Quellen sehr unterschiedlich sind.
- Im wirklichen Leben können einige Beispiele für Quelldaten sein
- Protokolldateien für jede spezifische Anwendung oder jeden Job oder Eintrag von Arbeitgebern in einem Unternehmen.
- Umfragedaten, Börsendaten usw.
- Webbrowser-Daten und vieles mehr.
2. Data Staging-Schicht
Die folgenden Schritte finden in Data Staging Layer statt.
1. Datenextraktion
Die von der Quellschicht empfangenen Daten werden in die Staging-Schicht eingespeist, wo der erste Prozess, der mit den erfassten Daten stattfindet, die Extraktion ist.
2. Landing Database
- Die extrahierten Daten werden vorübergehend in einer Landedatenbank gespeichert.
- Es ruft die Daten ab, sobald die Daten extrahiert sind.
3. Bereitstellungsbereich
- Die Daten in der Landedatenbank werden erfasst, und im Bereitstellungsbereich werden mehrere Qualitätsprüfungen und Bereitstellungsvorgänge durchgeführt.
- Die Struktur und das Schema werden ebenfalls identifiziert und Anpassungen an Daten vorgenommen, die ungeordnet sind, wodurch versucht wird, eine Gemeinsamkeit zwischen den erfassten Daten herzustellen.
- Ein Ort oder eine Einrichtung für die Daten unmittelbar vor der Transformation und den Änderungen ist ein zusätzlicher Vorteil, der den Staging-Prozess sehr wichtig macht.
- Es erleichtert die Datenverarbeitung.
4. ETL
- Es ist eine Extraktion, Transformation und Last.
- ETL-Tools werden für die Integration und Verarbeitung von Daten verwendet, bei denen Logik auf eher rohe, aber etwas geordnete Daten angewendet wird.
- Diese Daten werden entsprechend der erforderlichen Analyse extrahiert und in Daten umgewandelt, die für die Speicherung im Data Warehouse als geeignet erachtet werden.
- Nach der Transformation werden die Daten bzw. Informationen endgültig in das Data Warehouse geladen.
- Einige Beispiele für ETL-Tools sind Informatica, SSIS usw.
3. Datenspeicherschicht
- Die verarbeiteten Daten werden im Data Warehouse gespeichert.
- Diese Daten werden mit einer bestimmten Struktur bereinigt, transformiert und aufbereitet und bieten somit den Arbeitgebern die Möglichkeit, die vom Unternehmen geforderten Daten zu verwenden.
- Abhängig von der Herangehensweise der Architektur werden die Daten sowohl in Data Warehouse als auch in Data Marts gespeichert. Data Marts werden in den späteren Phasen besprochen.
- Einige enthalten auch einen Betriebsdatenspeicher.
4. Datenpräsentationsschicht
- Diese Ebene, auf der die Benutzer mit den im Data Warehouse gespeicherten Daten interagieren können.
- Abfragen und verschiedene Tools werden verwendet, um verschiedene Arten von Informationen basierend auf den Daten zu erhalten.
- Die Informationen erreichen den Benutzer über die grafische Darstellung von Daten.
- Reporting-Tools werden zum Abrufen von Geschäftsdaten verwendet. Geschäftslogik wird auch zum Sammeln verschiedener Arten von Informationen verwendet.
- In dieser Ebene werden auch Metadateninformationen sowie Systemvorgänge und -leistung verwaltet und angezeigt.
Fazit
Ein wichtiger Punkt bei Data Warehouse ist die Effizienz. Um ein effizientes Data Warehouse zu erstellen, erstellen wir ein Framework, das als Business Analysis Framework bezeichnet wird. Es gibt vier Arten von Ansichten in Bezug auf den Entwurf eines Data Warehouse.
1. Top-Down-Ansicht: In dieser Ansicht können nur bestimmte Informationen ausgewählt werden, die für ein Data Warehouse erforderlich sind.
2. Datenquellenansicht: In dieser Ansicht werden alle Informationen von der Datenquelle bis zur Transformation und Speicherung angezeigt.
3. Data Warehouse-Ansicht: In dieser Ansicht werden die im Data Warehouse vorhandenen Informationen in Form von Faktentabellen und Dimensionstabellen angezeigt.
4. Business Query View: Dies ist eine Ansicht, in der die Daten aus Sicht des Benutzers angezeigt werden.
Empfohlene Artikel
Dies war ein Leitfaden für die Data Warehouse-Architektur. Hier haben wir die verschiedenen Arten von Ansichten, Ebenen und Ebenen der Data Warehouse-Architektur besprochen. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Karriere im Bereich Data Warehousing
- Wie funktioniert JavaScript?
- Fragen im Vorstellungsgespräch bei Data Warehouse
- Was ist Pandas?