
Einführung in die Hive Group von
Gruppieren nach Wie der Name schon sagt, wird der Datensatz gruppiert, der bestimmte Kriterien erfüllt. In diesem Artikel werden wir uns die Gruppe von HIVE ansehen. In älteren RDBMS wie MySQL, SQL usw. ist group by eine der ältesten Klauseln, die verwendet werden. Jetzt hat es auf ähnliche Weise seinen Platz in der dateibasierten Datenspeicherung gefunden, die bekannt ist als HIVE.
Wir wissen, dass der Hive viele alte RDBMS bei der Verarbeitung großer Datenmengen übertroffen hat, ohne dass ein Cent für die Wartung der Datenbanken und Server für Anbieter ausgegeben wurde. Wir müssen nur HDFS konfigurieren, um mit Hive umzugehen. Im Allgemeinen wechseln wir zu Tabellen, da der Endbenutzer anhand seiner Struktur interpretieren und nachfragen kann, da Dateien für sie ungeschickt sind. Dafür mussten wir jedoch die Lieferanten dafür bezahlen, dass sie Server bereitstellten und unsere Daten in Tabellenform pflegten. Daher bietet Hive den kostengünstigen Mechanismus, bei dem dateibasierte Systeme (die Art und Weise, wie der Hive seine Daten speichert) sowie Tabellen (Tabellenstruktur, nach der die Endbenutzer abfragen können) genutzt werden.
Gruppiere nach
Gruppieren nach verwendet die definierten Spalten aus der Hive-Tabelle, um die Daten zu gruppieren. Angenommen, Sie haben eine Tabelle mit den Volkszählungsdaten aus jeder Stadt aller Bundesstaaten, in der der Name der Stadt und der Name des Bundesstaates eine der Spalten ist. Wenn wir nun in der Abfrage nach Bundesstaaten gruppieren, werden alle Daten aus verschiedenen Städten eines bestimmten Bundesstaates zusammengefasst, und Sie können die Daten jetzt besser visualisieren, bevor die Art und Weise der Gruppierung nach angewendet wurde.
Syntax von Hive Group By
Die allgemeine Syntax der group by-Klausel lautet wie folgt:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
oder für einfachere Abfragen
from Group By
Select department, count(*) from the university.college Group By department;
Hier bezieht sich die Abteilung auf eine der Spalten der Hochschultabelle, die in der Universitätsdatenbank vorhanden ist, und ihr Wert ist in Abteilungen wie Kunst, Mathematik, Ingenieurwesen usw. unterschiedlich.
Ich habe eine Beispieltabelle deck_of_cards erstellt, um die Gruppe zu demonstrieren. Die Anweisung create table lautet wie folgt:
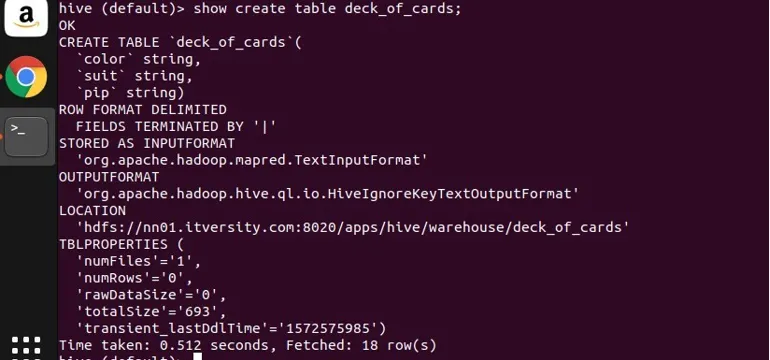
Sie können von oben sehen, dass es drei String-Spalten Farbe, Anzug und Pip hat. Lassen Sie mich eine Abfrage schreiben, um die Daten nach ihrer Farbe zu gruppieren und ihre Anzahl zu ermitteln.
select color, count(*) from deck_of_cards group by color;
Hive verwendet im Grunde genommen die obige Abfrage, um sie in das Programm zur Kartenreduzierung zu konvertieren, indem der entsprechende Java-Code und die entsprechende JAR-Datei generiert und dann ausgeführt werden. Dieser Vorgang kann etwas Zeit in Anspruch nehmen, kann jedoch im Vergleich zu herkömmlichen RDBMS-Systemen die großen Datenmengen definitiv verarbeiten. In der folgenden Abbildung sehen Sie das detaillierte Protokoll zur Ausführung der obigen Abfrage.
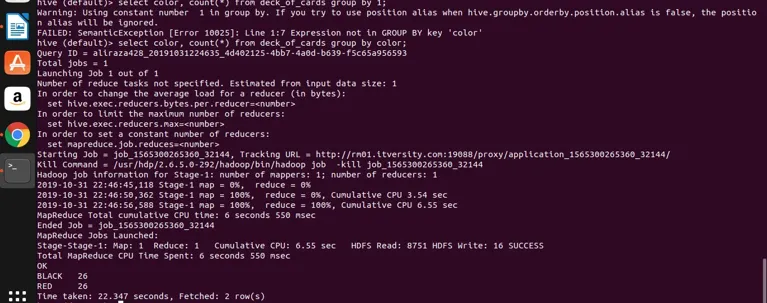
Sie können sehen, dass SCHWARZ 26 und ROT 26 ist.
Wenden wir nun die Gruppierung auf zwei Spalten an (Farbe und Farbe und Ermitteln der Gruppenzahl) und sehen uns das Ergebnis unten an.
Select color, suit, count(*) from deck_of_cards group by color, suit
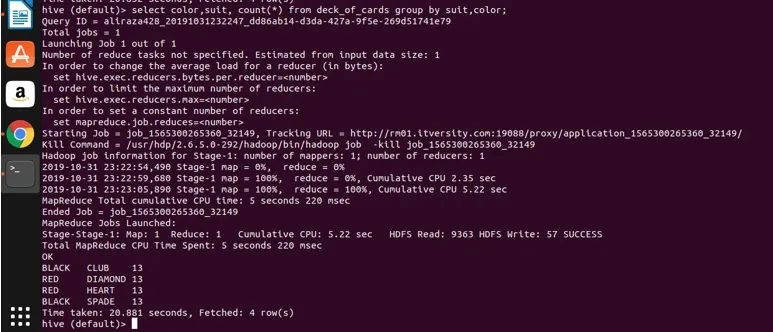
Grundsätzlich gibt es vier verschiedene Gruppen über Club, Spade mit der Farbe Schwarz und Diamond und Heart mit der Farbe Rot.
Speichern des Ergebnisses von Group by Cause in einer anderen Tabelle
Hive bietet auch wie jedes andere RDBMS die Möglichkeit, die Daten mit create table-Anweisungen einzufügen. Betrachten wir das Speichern des Ergebnisses eines ausgewählten Ausdrucks mithilfe einer Gruppierung nach in einer anderen Tabelle. Lassen Sie mich die obige Abfrage selbst verwenden, wo ich zwei Spalten in Gruppe von verwendet habe.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
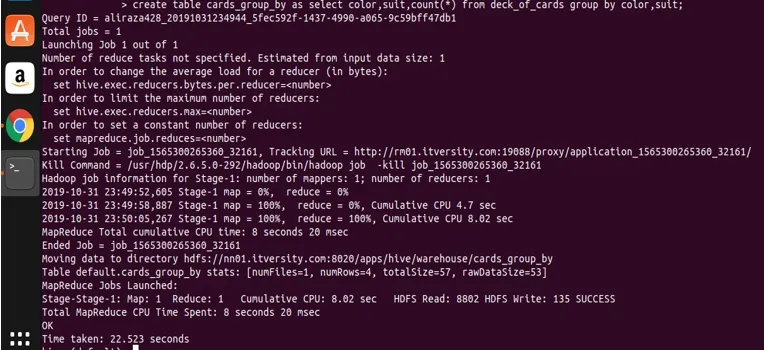
Lassen Sie uns nun die erstellte Tabelle abfragen, um die Daten anzuzeigen und zu validieren.

Beschränken wir nun das Ergebnis der Gruppe mit der having-Klausel. Wie in der generischen Syntax gezeigt, können wir die Gruppe einschränken, indem wir haben. Hier verwende ich die ordser_items-Tabelle und ihre Struktur ist wie folgt aus der describe-Anweisung.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
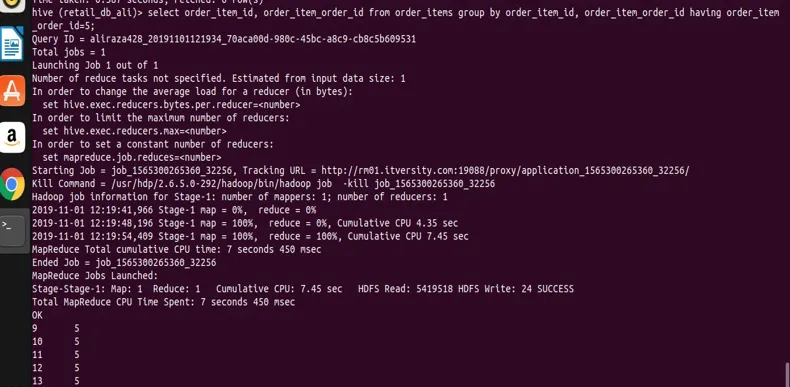
Sie können dem Ergebnis den Screenshot entnehmen, dass wir nur Datensätze mit dem order_item_order_id-Wert 5 haben.
Gruppieren nach Zusammen mit der Fallbeschreibung
Betrachten wir nun etwas komplexe Abfragen, die die CASE-Anweisungen mit der Gruppe by betreffen. Wir werden dies auf die Tabelle order_items anwenden. Wir werden unten sehen, dass wir die nicht aggregierenden Spalten kategorisieren können, auf die wir die group by-Klausel nicht direkt anwenden können.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
Lassen Sie es uns im Bienenstock für Ergebnisse ausführen
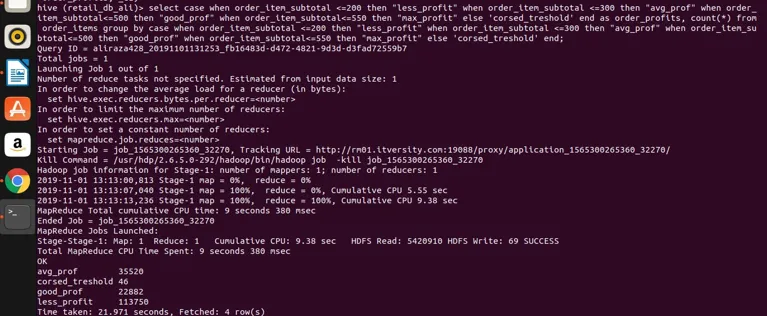
Fazit - Hive Group von
Wir können also sehen, dass wir order_item_subtotal in vier verschiedene Kategorien gruppiert haben (wenn Sie beachten, dass order_item_subtotal eine nicht aggregierende Spalte ist und die direkte Gruppe von nicht darauf angewendet werden kann), und wir haben sie zusammen gruppiert und auch ihre Anzahl für erhalten die Werte, die den im Auswahlausdruck definierten Bereich erfüllen. Hier ist die einfache Regel, wenn die Spalte nicht aggregiert und unser Auswahlausdruck komplex ist, was auch immer im Auswahlausdruck enthalten ist, der auch in dem Ausdruck group by clause vorhanden sein sollte. Wir haben also gesehen, wie eine berühmte Klausel RDBMS clause group by ohne Einschränkungen auch auf den Hive angewendet werden kann. Es kann auf einfache Auswahlausdrücke angewendet werden. Aggregieren und Filtern von Ausdrücken, Verknüpfen von Ausdrücken und komplexen CASE-Ausdrücken.
Empfohlene Artikel
Dies ist eine Anleitung zu Hive Group By. Hier diskutieren wir die Group By, Syntax, Beispiele der Hive Group By mit unterschiedlichen Bedingungen und Implementierungen. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Schließt sich Hive an
- Was ist ein Bienenstock?
- Bienenstock-Architektur
- Hive-Funktion
- Hive Order By
- Hive-Installation
- Top 6 Arten von Joins in MySQL mit Beispielen