

Einführung in Data Science-Techniken
In der heutigen Welt, in der Daten das neue Gold sind, stehen für ein Unternehmen verschiedene Arten von Analysen zur Verfügung. Das Ergebnis eines datenwissenschaftlichen Projekts hängt stark von der Art der verfügbaren Daten ab, und daher ist auch die Auswirkung variabel. Da es viele verschiedene Arten von Analysen gibt, ist es unerlässlich zu verstehen, welche Baseline-Techniken ausgewählt werden müssen. Das wesentliche Ziel datenwissenschaftlicher Techniken ist nicht nur die Suche nach relevanten Informationen, sondern auch die Erkennung von Schwachstellen, die dazu führen, dass das Modell eine schlechte Leistung erbringt.
Was ist Data Science?
Die Datenwissenschaft ist ein Bereich, der sich über mehrere Disziplinen erstreckt. Es beinhaltet wissenschaftliche Methoden, Prozesse, Algorithmen und Systeme, um Wissen zu sammeln und daran zu arbeiten. Dieses Feld umfasst eine Vielzahl von Genres und ist eine gemeinsame Plattform für die Vereinheitlichung der Konzepte von Statistik, Datenanalyse und maschinellem Lernen. Dabei werden die theoretischen Kenntnisse der Statistik sowie Echtzeitdaten und -techniken des maschinellen Lernens zusammengeführt, um fruchtbare Ergebnisse für das Unternehmen abzuleiten. Mit verschiedenen Techniken der Datenwissenschaft können wir in der heutigen Welt bessere Entscheidungen treffen, die dem menschlichen Auge und Verstand sonst entgehen könnten. Denken Sie daran, die Maschine vergisst nie! Um in einer datengetriebenen Welt den Profit zu maximieren, ist die Magie von Data Science ein notwendiges Werkzeug.
Verschiedene Arten von Data Science-Techniken
In den folgenden Abschnitten werden wir uns mit den in allen anderen Projekten verwendeten allgemeinen datenwissenschaftlichen Techniken befassen. Obwohl die Data-Science-Technik manchmal geschäftsproblemspezifisch sein kann und möglicherweise nicht in die folgenden Kategorien fällt, ist es völlig in Ordnung, sie als verschiedene Typen zu bezeichnen. Auf hoher Ebene unterteilen wir die Techniken in Überwacht (wir kennen die Zielauswirkung) und Unüberwacht (wir kennen die Zielvariable, die wir erreichen wollen, nicht). In der nächsten Ebene können die Techniken in Bezug auf unterteilt werden
- Die Ausgabe, die wir erhalten würden, oder was die Absicht des Geschäftsproblems ist
- Art der verwendeten Daten.
Betrachten wir zunächst die Trennung auf der Grundlage von Absichten.
1. Unüberwachtes Lernen
- Anomalieerkennung
Bei dieser Art von Technik identifizieren wir alle unerwarteten Vorkommnisse im gesamten Datensatz. Da sich das Verhalten vom tatsächlichen Auftreten von Daten unterscheidet, werden folgende Annahmen zugrunde gelegt:
- Das Auftreten dieser Instanzen ist in der Anzahl sehr gering.
- Der Unterschied im Verhalten ist signifikant.
Es werden Anomalie-Algorithmen erläutert, z. B. der Isolation Forest, der eine Bewertung für jeden Datensatz in einem Datensatz bereitstellt. Dieser Algorithmus ist ein baumbasiertes Modell. Mit dieser Art von Erkennungstechnik und ihrer Beliebtheit werden sie in verschiedenen Geschäftsfällen verwendet, z. B. Webseitenansichten, Abwanderungsrate, Umsatz pro Klick usw. In der folgenden Grafik können wir erläutern, wie Anomalien aussehen.
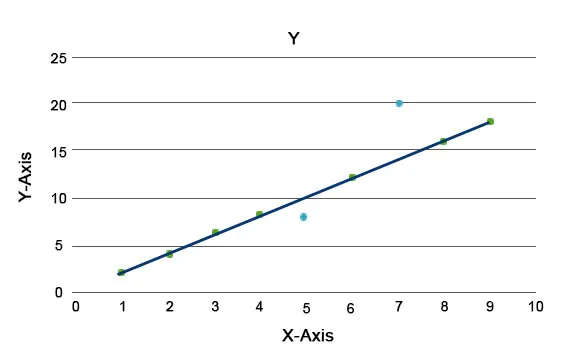
Hier stellen diejenigen in Blau eine Anomalie im Datensatz dar. Sie weichen von der regulären Trendlinie ab und treten seltener auf.
- Clusteranalyse
Bei dieser Analyse besteht die Hauptaufgabe darin, den gesamten Datensatz in Gruppen zu unterteilen, sodass der Trend oder die Merkmale in den Datenpunkten einer Gruppe einander sehr ähnlich sind. In der datentechnischen Terminologie werden diese als Cluster bezeichnet. Im Einzelhandelsgeschäft gibt es beispielsweise einen Plan zur Skalierung des Geschäfts, und es muss unbedingt bekannt sein, wie sich die neuen Kunden in einer neuen Region basierend auf den uns vorliegenden Vergangenheitsdaten verhalten würden. Es wird unmöglich, eine Strategie für jedes Individuum in einer Population zu entwickeln, aber es wird nützlich sein, die Population in Cluster einzuteilen, so dass die Strategie in einer Gruppe effektiv und skalierbar ist.
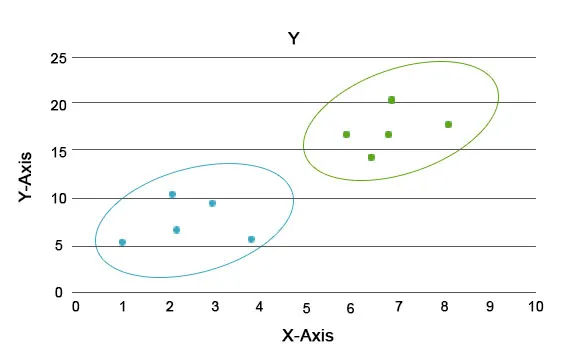
Hier sind die Farben Blau und Orange verschiedene Cluster mit einzigartigen Merkmalen in sich.
- Assoziationsanalyse
Diese Analyse hilft uns dabei, interessante Beziehungen zwischen Elementen in einem Datensatz aufzubauen. Diese Analyse deckt verborgene Beziehungen auf und hilft bei der Darstellung von Datenmengenelementen in Form von Zuordnungsregeln oder Mengen häufiger Elemente. Die Assoziationsregel ist in zwei Schritte unterteilt:
- Häufige Itemset-Generierung: Hier wird ein Set generiert, in dem häufig vorkommende Items zusammen angelegt werden.
- Regelerstellung: Die oben erstellte Menge wird durch verschiedene Ebenen der Regelerstellung geleitet, um eine verborgene Beziehung zwischen ihnen aufzubauen. Beispielsweise kann der Satz in konzeptionelle oder Implementierungsprobleme oder Anwendungsprobleme fallen. Diese werden dann in entsprechenden Bäumen verzweigt, um die Zuordnungsregeln zu erstellen.
Beispielsweise ist APRIORI ein Assoziationsregel-Erstellungsalgorithmus.
2. Betreutes Lernen
- Regressionsanalyse
In der Regressionsanalyse definieren wir die abhängige Variable / Zielvariable und die verbleibenden Variablen als unabhängige Variablen und stellen schließlich die Hypothese auf, wie eine / mehrere unabhängige Variablen die Zielvariable beeinflussen. Die Regression mit einer unabhängigen Variablen wird als univariat und mit mehr als einer als multivariat bezeichnet. Lassen Sie uns verstehen, wie man univariate und dann multivariate skaliert.
Zum Beispiel ist y die Zielvariable und x 1 ist die unabhängige Variable. Aus der Kenntnis der Geraden können wir also die Gleichung als y = mx 1 + c schreiben. Hier bestimmt „m“, wie stark y von x 1 beeinflusst wird. Wenn „m“ sehr nahe bei Null liegt, bedeutet dies, dass bei einer Änderung von x 1 y nicht stark beeinflusst wird. Bei einer Zahl größer als 1 wird der Einfluss stärker und eine kleine Änderung von x 1 führt zu einer großen Änderung von y. Ähnlich wie bei Univariate kann bei Multivariate geschrieben werden als y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………. Hier wird die Auswirkung jeder unabhängigen Variablen durch ihr entsprechendes „m“ bestimmt.
- Klassifikationsanalyse
Ähnlich wie bei der Clusteranalyse werden Klassifizierungsalgorithmen mit der Zielvariablen in Form von Klassen erstellt. Der Unterschied zwischen Clustering und Klassifikation besteht darin, dass wir beim Clustering nicht wissen, zu welcher Gruppe die Datenpunkte gehören, während wir bei der Klassifikation wissen, zu welcher Gruppe sie gehören. Und es unterscheidet sich von der Regression aus der Perspektive, dass die Anzahl der Gruppen eine feste Zahl sein sollte, im Gegensatz zur Regression, sie ist stetig. In der Klassifizierungsanalyse gibt es eine Reihe von Algorithmen, z. B. Support Vector Machines, Logistic Regression, Decision Trees usw.
Fazit
Zusammenfassend verstehen wir, dass jede Art von Analyse für sich genommen sehr umfangreich ist, aber hier können wir verschiedenen Techniken einen kleinen Vorgeschmack geben. In den nächsten paar Anmerkungen nehmen wir jede für sich und gehen auf Details zu verschiedenen Subtechniken ein, die in den jeweiligen Elterntechniken verwendet werden.
Empfohlener Artikel
Dies ist eine Anleitung zu Data Science-Techniken. Hier diskutieren wir die Einführung und verschiedene Arten von Techniken in der Datenwissenschaft. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Data Science Tools | Top 12 Werkzeuge
- Datenwissenschaftliche Algorithmen mit Typen
- Einführung in die Data Science Karriere
- Data Science vs Datenvisualisierung
- Beispiele für multivariate Regression
- Entscheidungsbaum mit Vorteilen anlegen
- Kurzer Überblick über den Data Science Lifecycle