

Was ist Data Mining?
Bevor wir uns mit den Data Mining-Konzepten und -Techniken vertraut machen, werden wir uns zunächst mit Data Mining befassen. Data Mining ist ein Merkmal der Konvertierung von Daten in einige sachkundige Informationen. Dies bezieht sich auf den Prozess des Abrufs neuer Informationen, indem eine große Menge verfügbarer Daten untersucht wird. Mit verschiedenen Techniken und Werkzeugen kann man die Informationen, die aus den Daten benötigt werden, nur vorhersagen, wenn das befolgte Verfahren korrekt ist. Dies ist in verschiedenen Branchen hilfreich, um einige erforderliche Informationen für zukünftige Analysen zu extrahieren, indem einige Muster in den vorhandenen Daten in Datenbanken, Data Warehouses usw. erkannt werden.
Datentypen in Data Mining
Im Folgenden sind die Datentypen aufgeführt, für die Data Mining ausgeführt werden kann:
- Relationale Datenbanken
- Data Warehouse
- Erweiterte Datenbank- und Informationsrepositorys
- Objektorientierte und objektrelationale Datenbanken
- Transaktions- und Geodatenbanken
- Heterogene und alte Datenbanken
- Multimedia- und Streaming-Datenbank
- Textdatenbanken
- Text Mining und Web Mining
Data Mining-Prozess
Nachfolgend sind die Punkte für den Data Mining-Prozess aufgeführt:
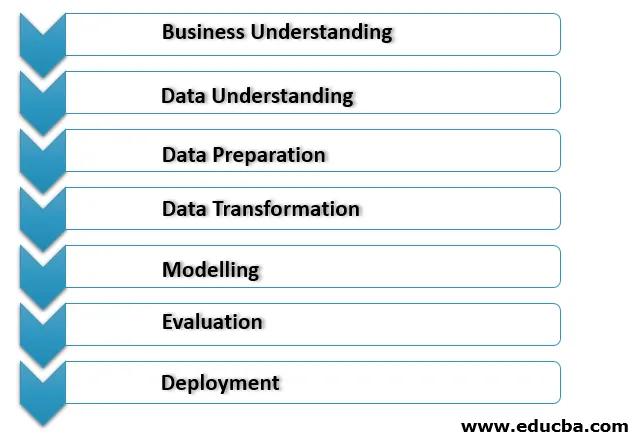
1. Geschäftsverständnis
Dies ist die erste Phase des Data Mining-Implementierungsprozesses, in der alle Anforderungen und das Geschäftsziel des Kunden klar verstanden werden. Die richtigen Data Mining-Ziele werden unter Berücksichtigung des aktuellen Szenarios im Unternehmen und anderer Faktoren wie Ressourcen, Annahmen und Einschränkungen festgelegt. Ein ordnungsgemäßer Data Mining-Plan sollte detailliert sein und unsere Geschäfts- und Data Mining-Ziele erfüllen.
2. Datenverständnis
In dieser Phase werden die Daten, die aus verschiedenen Ressourcen für Data Mining-Prozesse gesammelt wurden, auf ihre Richtigkeit überprüft. Zunächst werden alle Daten aus den verschiedenen Quellen in Bezug auf das Geschäftsszenario der Organisation gesammelt, das sich in den verschiedenen Datenbanken, Einfachdateien usw. Befinden kann Die gesammelten Daten werden auf korrekte Übereinstimmung überprüft, da sie nicht miteinander in Beziehung stehen können.
Manchmal müssen auch Metadaten überprüft werden, um die Fehler in den Data Mining-Prozessen zu reduzieren. Verschiedene Data Mining-Abfragen werden zur Analyse korrekter Daten verwendet und auf der Grundlage der Ergebnisse kann die Datenqualität überprüft werden. Es hilft auch zu analysieren, ob Daten fehlen oder nicht.
3. Datenaufbereitung
Dieser Vorgang beansprucht die maximale Zeit des Projekts. Dieses Gesicht enthält einen Prozess, der als Datenbereinigung bezeichnet wird, um die Daten zu bereinigen, die während des Datenverständnisprozesses gesammelt wurden. Der Datenbereinigungsprozess wird verwendet, um die Daten zu bereinigen, um unkorrekte verrauschte Daten für die Daten mit fehlenden Werten auszuschließen.
4. Datenumwandlung
Im nächsten Zustand werden Datentransformationsoperationen ausgeführt, mit denen die Daten geändert werden, um sie für den Data Mining-Implementierungsprozess nützlich zu machen. Hier werden Transformationen wie Aggregation, Generalisierung, Normalisierung oder Attributkonstruktion durchgeführt, um die Daten für den Datenmodellierungsprozess vorzubereiten.
5. Modellierung
In dieser Phase des Data Mining werden die Datenmuster mit der richtigen Technik ermittelt. Die verschiedenen Szenarien müssen erstellt werden, um die Qualität und Gültigkeit dieses Modells zu überprüfen und um festzustellen, ob die im Geschäftsverständnisprozess festgelegten Ziele nach der Implementierung dieser Techniken erreicht werden. Das in diesem Prozess gefundene Muster wird weiter ausgewertet und zur Bereitstellung an das Business Operations-Team gesendet, damit die Geschäftspolitik des Unternehmens verbessert werden kann.
6. Auswertung
In dieser Phase wird die ordnungsgemäße Auswertung der Data Mining-Entdeckungen vorgenommen, um die Implementierung in den Geschäftsprozessen zu ermöglichen. Es wird ein ordnungsgemäßer Vergleich mit den Entdeckungen durchgeführt, und der vorhandene Geschäftsbetriebsplan muss zum aktuellen Geschäftsbetrieb hinzugefügt werden, um die Änderung der gefundenen Informationen ordnungsgemäß zu bewerten.
7. Bereitstellung
In dieser Phase werden die Informationen, die mithilfe von Data Mining-Prozessen ermittelt wurden, in eine für nichttechnische Stakeholder verständliche Form umgewandelt. Für diesen Prozess wird ein geeigneter Bereitstellungsplan erstellt, der Versand, Wartung und Überwachung der gefundenen Informationen umfasst. Auf diese Weise wird ein geeigneter Projektbericht zusammen mit den Erfahrungen und Erkenntnissen während des Prozesses erstellt, um unsere Data-Mining-Entdeckungen an das Business-Operations-Team zu übergeben.
Daher trägt dieser Prozess zur Verbesserung der Geschäftspolitik einer Organisation bei.
Data Mining-Techniken
Die folgenden Techniken und Technologien können dabei helfen, die Data Mining-Funktion auf effizienteste Weise anzuwenden:
1. Verfolgen Sie die Muster
Das Erkennen der Muster in Ihrem Dataset ist eine der grundlegenden Techniken beim Data Mining. Die Daten werden in regelmäßigen Abständen zum Erkennen einer Aberration beobachtet. Beispielsweise kann festgestellt werden, dass eine bestimmte Person, die in verschiedenen Ländern unterwegs ist, regelmäßig Tickets buchen muss, sodass eine spezielle Kreditkarte angeboten werden kann.
2. Klassifizierung
Es ist eine der komplexen Techniken für das Data Mining, bei der verschiedene erkennbare Kategorien unter Verwendung verschiedener Attribute in den vorhandenen Daten erstellt werden müssen. Diese Kategorien helfen, verschiedene Schlussfolgerungen für unsere zukünftige Verwendung zu ziehen. Während beispielsweise die Daten für den Verkehr in der Stadt analysiert werden, kann der Verkehr in der Region in niedrig, mittel und schwer klassifiziert werden. Dies wird den Reisenden helfen, den Verkehr vorzeitig vorherzusagen.
3. Verein
Diese Technik ähnelt der Pattern-Tracking-Technik, bezieht sich jedoch hier auf die abhängig verknüpften Variablen. Das heißt, es wird das Muster für die zugehörigen Daten gefunden, das mit den vorhandenen Daten verknüpft ist. Das Ereignis, das sich auf das andere Ereignis bezieht, wird nachverfolgt und die bestimmten Muster werden in diesen Daten gefunden. Beispielsweise können mit Dateiverfolgungsdaten für den Verkehr in einer bestimmten Stadt auch die am häufigsten besuchten Orte in einer Stadt verfolgt werden. Dies kann auch dazu beitragen, berühmte Orte in der Stadt aufzuspüren.
4. Ausreißererkennung
Diese Technik bezieht sich auf die Extraktion von Anomalien im Datenmuster. Zum Beispiel macht der Verkauf eines Einkaufszentrums in den elf Monaten des Jahres einen guten Gewinn, aber im letzten Monat sind die Verkäufe so stark gesunken, dass es zu Verlusten kommt. In diesen Fällen müssen wir herausfinden, was den Umsatzrückgang verursacht hat, damit wir ihn beim nächsten Mal vermeiden können. Die Technik, eine solche Ablenkung im regelmäßigen Muster zu finden, ist Teil der Outlier-Detektionstechnik.
5. Clustering
Diese Technik ähnelt der Klassifizierung. Der einzige Unterschied besteht darin, dass die Datengruppe ausgewählt wird, die einige Ähnlichkeiten aufweist, die in einer einzelnen Gruppe zusammengefasst sind. Zum Beispiel, wenn verschiedene Zuschauer eines Kinos anhand der Häufigkeit gruppiert werden, wie oft sie zu Shows kommen, zu welchem Zeitpunkt sie am häufigsten kommen und für welches Filmgenre sie kommen.
6. Regression
Diese Technik hilft, die Beziehung zwischen den beiden Variablen zu zeichnen, von denen eine Analyse abhängen könnte. Hier versuchen wir, das Änderungsmuster in der Variablen herauszufinden, indem wir die anderen abhängigen Variablen festlegen. Wenn wir beispielsweise das Verkaufsmuster eines Produkts in einem Einkaufszentrum in Abhängigkeit von Verfügbarkeit, Saison, Nachfrage usw. ermitteln müssen, kann dies den Eigentümer veranlassen, den Verkaufspreis festzulegen.
7. Vorhersage
Das wichtigste Merkmal von Data Mining besteht darin, zukünftige Risiken zu reduzieren und den Gewinn des Unternehmens zu steigern, indem die vorhandenen und historischen Muster für Umsatz- und Kreditrisiken untersucht werden. Hier hilft uns diese Art von Technologie, zukünftige Entscheidungen in Abhängigkeit von dem in historischen und gegenwärtigen Daten gefundenen Muster zu treffen und Marktveränderungen und Risiken im Auge zu behalten. Diese Technik ist für das Data Mining am hilfreichsten.
Data Mining-Tools
Man braucht nicht die neuesten Technologien, um Data Mining durchzuführen. Dies kann auch mit den neuesten Datenbanksystemen und einfachen Tools erfolgen, die in jeder Organisation leicht verfügbar sind. Man kann auch ein eigenes Werkzeug erstellen, wenn das entsprechende Werkzeug fehlt. Das beliebteste Werkzeug, das in der Branche weit verbreitet ist, ist unten aufgeführt:
1. R-Sprache
Dies ist ein Open-Source-Tool, das für statistische Berechnungen und Grafiken verwendet wird. Dieses Tool unterstützt Sie bei der effektiven Datenverarbeitung und -speicherung und bietet die folgenden Funktionen:
- Statistisch
- Klassische statistische Tests
- Zeitreihenanalyse
- Einstufung
- Grafische Techniken
2. Oracle Data Mining
Dieses Tool ist im Volksmund als ODM bekannt und Teil der Oracle Advanced Analytics-Datenbank. Dieses Tool hilft bei der Analyse von Daten in Data Warehouses und generiert detaillierte Erkenntnisse, die weitere Vorhersagen ermöglichen. Diese Dinge helfen bei der Untersuchung des Kundenverhaltens, die Nachfrage nach Produkten und die Steigerung der Verkaufschancen.
Herausforderungen bei der Implementierung von Data Mine:
- Für komplexe Data-Mining-Abfragen werden erfahrene Experten benötigt.
- Derzeitige Modelle passen möglicherweise nicht in die Datenbanken des zukünftigen Status. Möglicherweise passen sie nicht in zukünftige Status.
- Schwierigkeiten bei der Verwaltung großer Datenbanken.
- Möglicherweise muss die Geschäftspraxis geändert werden, um aufgedeckte Informationen zu verwenden.
- Globale heterogene Datenbanken und Informationen können zu komplexen integrierten Informationen führen.
- Data Mining setzt voraus, dass die Daten unterschiedlicher Art sind, da sonst die Ergebnisse möglicherweise ungenau sind.
Schlussfolgerung - Data Mining-Konzepte und -Techniken
- Mit Data Mining können Sie vergangene Daten nachverfolgen und anhand dieser Daten zukünftige Analysen durchführen.
- Dies entspricht dem Extrahieren der für die Analyse erforderlichen Informationen aus den Assets des letzten Datums, die bereits in den Datenbanken vorhanden sind.
- Data Mining kann auf verschiedenen Arten von Datenbanken wie Geodatenbasis, RDBMS, Data Warehouses, Mehrfach- und Altdatenbanken usw. durchgeführt werden.
- Der gesamte Mining-Prozess umfasst Geschäftsverständnis, Datenverständnis, Datenvorbereitung, Modellierung, Evolution und Bereitstellung.
- Es stehen verschiedene Data Mining-Techniken zur Verfügung, mit denen Data Mining auf effiziente Weise ausgeführt werden kann, z. B. Klassifizierung, Regressionszuordnung usw. Die Verwendung hängt vom jeweiligen Szenario ab.
- Die effektivsten Data Mining-Tools sind R-Language und Oracle Data.
- Der Hauptnachteil von Data Mining ist die Schwierigkeit, Experten für den Betrieb dieser Analysesoftware zu schulen.
- Es gibt verschiedene Branchen, die Data Mining für ihre Analysezwecke verwenden, z. B. das Bankwesen, das verarbeitende Gewerbe, Supermärkte, Einzelhandelsdienstleister usw.
Empfohlene Artikel
Dies ist eine Anleitung zu Data Mining-Konzepten und -Techniken. Hier diskutieren wir den Data Mining-Prozess, Techniken und Tools in Data Mining. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren.
- Vorteile von Data Mining
- Was ist Data Mining?
- Data Mining-Prozess
- Data Science-Techniken
- Clustering im maschinellen Lernen
- Wie generiere ich Testdaten?
- Leitfaden zu Modellen in Data Mining