

Einführung in Apache Flume
Apache Flume ist das Data Ingestion Framework, das ereignisbasierte Daten in das Hadoop Distributed File System schreibt. Es ist bekannt, dass Hadoop Big Data verarbeitet. Es stellt sich die Frage, wie die von verschiedenen Webservern generierten Daten an Hadoop File System übertragen werden. Die Antwort ist Apache Flume. Flume wurde für die Aufnahme großer Datenmengen in Hadoop von ereignisbasierten Daten entwickelt.
Stellen Sie sich ein Szenario vor, in dem die Anzahl der Webserver Protokolldateien generiert und diese Protokolldateien an das Hadoop-Dateisystem übertragen werden müssen. Flume sammelt diese Dateien als Ereignisse und nimmt sie in Hadoop auf. Obwohl Flume zur Übertragung an Hadoop verwendet wird, gibt es keine strenge Regel, dass das Ziel Hadoop sein muss. Flume kann in andere Frameworks wie Hbase oder Solr schreiben.
Gerinne Architektur
Im Allgemeinen besteht die Apache Flume-Architektur aus den folgenden Komponenten:
- Gerinne Quelle
- Abwasserkanal
- Gerinne Waschbecken
- Flume Agent
- Gerinne Ereignis
Lassen Sie uns einen kurzen Blick auf die einzelnen Komponenten von Flume werfen
1. Geruchsquelle
Auf Datengeneratoren wie Facebook oder Twitter ist eine Wasserquelle vorhanden. Source sammelt Daten vom Generator und überträgt diese Daten in Form von Flume Events an Flume Channel. Flume unterstützt verschiedene Arten von Quellen wie Avro Flume Source: Verbindet sich mit dem Avro-Port und empfängt Ereignisse vom externen Avro-Client, Thrift Flume Source: Verbindet sich mit dem Thrift-Port und empfängt Ereignisse von externen Thrift-Client-Streams, Spooling Directory Source und Kafka Flume Source.
2. Abwasserkanal
Ein Zwischenspeicher, der die von Flume Source gesendeten Ereignisse puffert, bis sie von Sink verbraucht werden, wird als Flume Channel bezeichnet. Kanal fungiert als Zwischenbrücke zwischen Quelle und Senke. Abflusskanäle sind transaktionaler Natur.
Flume bietet Unterstützung für den Dateikanal und den Speicherkanal. Der Dateikanal ist dauerhaft, dh, sobald die Daten in den Kanal geschrieben wurden, gehen sie nicht verloren, auch wenn der Agent neu gestartet wird. Im Speicher werden Kanalereignisse im Speicher gespeichert, daher ist es nicht dauerhaft, aber von Natur aus sehr schnell.
3. Gerinne Waschbecken
In Datenrepositorys wie HDFS, HBase ist ein Abfluss vorhanden. Die Abflussrinne verbraucht Ereignisse aus dem Kanal und speichert sie in Zielspeichern wie HDFS. Es gibt keine Regel, nach der die Senke Ereignisse an Store übermitteln soll. Stattdessen können wir sie so konfigurieren, dass eine Senke Ereignisse an einen anderen Agenten übermitteln kann. Flume unterstützt verschiedene Spülen wie HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
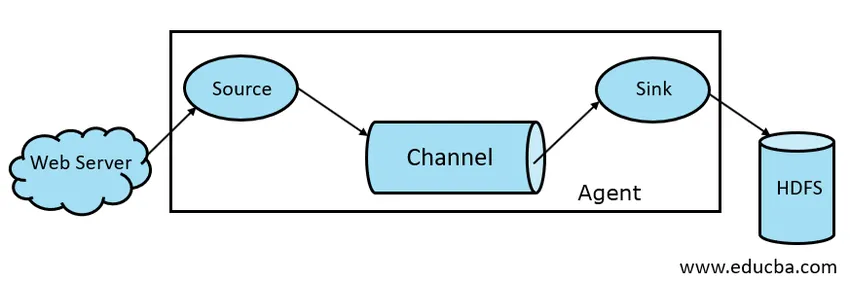
Abb. 1.1 Grundlegende Kanalarchitektur
4. Flume Agent
Ein Flume-Agent ist ein lang laufender Java-Prozess, der mit der Kombination von Quelle, Kanal und Senke ausgeführt wird. Gerinne können mehr als ein Mittel haben. Wir können Flume als eine Sammlung verbundener Flume-Agenten betrachten, die in der Natur verteilt sind.
5. Gerinneignis
Ein Ereignis ist die in Flume transportierte Dateneinheit . Die allgemeine Darstellung von Datenobjekten in Flume wird als Ereignis bezeichnet. Das Ereignis besteht aus einer Nutzlast eines Byte-Arrays mit optionalen Headern.
Arbeiten von Flume
Ein Flume-Agent ist ein Java-Prozess, der aus Source-Channel-Sink in seiner einfachsten Form besteht. Quelle sammelt Daten vom Datengenerator in Form von Ereignissen und liefert sie an Channel. Eine Quelle kann je nach Anforderung an mehrere Kanäle liefern. Fan-Out ist der Prozess, bei dem eine einzelne Quelle auf mehrere Kanäle schreibt, damit diese auf mehrere Senken übertragen werden können.
Ein Ereignis ist die grundlegende Dateneinheit, die in Flume übertragen wird. Channel puffert die Daten, bis sie von Sink aufgenommen werden. Sink sammelt die Daten von Channel und liefert sie an einen zentralen Datenspeicher wie HDFS, oder Sink kann diese Ereignisse je nach Anforderung an einen anderen Flume-Agenten weiterleiten.
Flume unterstützt Transaktionen. Um Zuverlässigkeit zu erreichen, verwendet Flume getrennte Transaktionen von Quelle zu Kanal und von Kanal zu Senke. Wenn Ereignisse nicht zugestellt werden, wird die Transaktion zurückgesetzt und später erneut zugestellt.
Um die Funktionsweise von Flume zu verstehen, nehmen wir ein Beispiel für die Konfiguration von Flume, bei der source das Spool-Verzeichnis und sink Hdfs ist. In diesem Beispiel hat der Flume-Agent die einfachste Form, dh eine Topologie aus einer Quelle, einem Kanal und einer Senke, die mithilfe einer Java-Eigenschaftendatei konfiguriert wird.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
Im obigen Konfigurationsbeispiel ist Agent die Basis, auf der wir andere Eigenschaften definieren. source1 und sink1 und channel1 sind die Namen von source, sink und channel und ihre Typen und Positionen werden ebenfalls entsprechend erwähnt.
Vorteile von Apache Flume
- Gerinne sind skalierbar, zuverlässig und fehlertolerant. Diese Eigenschaften werden nachstehend ausführlich erläutert
- Skalierbar - Flume ist horizontal skalierbar, dh wir können neue Knoten gemäß unseren Anforderungen hinzufügen
- Zuverlässig - Apache Flume unterstützt Transaktionen und stellt sicher, dass bei der Datenübertragung keine Daten verloren gehen. Es gibt unterschiedliche Transaktionen von Quelle zu Kanal und von Kanal zu Quelle.
- Flume ist anpassbar und bietet Unterstützung für verschiedene Quellen und Senken wie Kafka, Avro, Spooling Directory, Thrift etc
- In Flume kann eine einzelne Quelle Daten an mehrere Kanäle übertragen, und diese Kanäle übertragen die Daten wiederum an mehrere Senken. Auf diese Weise kann eine einzelne Quelle Daten an mehrere Senken übertragen. Dieser Mechanismus heißt Fan out. Flume unterstützt auch Fan out.
- Flume sorgt für einen stetigen Datenübertragungsfluss, dh wenn die Datenlesegeschwindigkeit zunimmt und dann auch die Datenschreibgeschwindigkeit zunimmt.
- Obwohl Flume im Allgemeinen Daten in einen zentralen Speicher wie HDFS oder Hbase schreibt, können wir Flume gemäß unseren Anforderungen so konfigurieren, dass Sink Daten in einen anderen Agenten schreiben kann. Dies zeigt die Flexibilität von Flume
- Apache Flume ist Open Source in der Natur.
Fazit
In diesem Flume-Artikel werden Komponenten von Flume und die Funktionsweise von Flume ausführlich behandelt. Flume ist eine flexible, zuverlässige und skalierbare Plattform, um Daten an einen zentralen Speicher wie HDFS zu übertragen. Seine Fähigkeit, sich in verschiedene Anwendungen wie Kafka, HDFS und Thrift zu integrieren, macht es zu einer praktikablen Option für die Datenaufnahme.
Empfohlene Artikel
Dies war ein Leitfaden für Apache Flume. Hier diskutieren wir Architektur, Arbeitsweise und Vorteile von Apache Flume. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Was ist Apache Flink?
- Unterschied zwischen Apache Kafka und Flume
- Big Data-Architektur
- Hadoop Tools
- Erfahren Sie die verschiedenen JavaScript-Ereignisse