

Deep Learning Interview Fragen und Antworten
Heute wird Deep Learning als eine der am schnellsten wachsenden Technologien angesehen, die in der Lage ist, eine Anwendung zu entwickeln, die vor einiger Zeit als schwierig galt. Spracherkennung, Bilderkennung, Auffinden von Mustern in einem Datensatz, Objektklassifizierung in Fotografien, Generierung von Zeichentexten, selbstfahrende Autos und vieles mehr sind nur einige Beispiele, bei denen Deep Learning seine Bedeutung gezeigt hat.
Sie haben also endlich Ihren Traumjob in Deep Learning gefunden, fragen sich aber, wie Sie das Deep Learning-Interview knacken können und welche Fragen das Deep Learning-Interview möglicherweise aufwirft. Jedes Interview ist anders und der Umfang eines Jobs ist auch anders. In Anbetracht dessen haben wir die häufigsten Fragen und Antworten zu Deep Learning-Vorstellungsgesprächen zusammengestellt, um Ihnen den Erfolg Ihres Vorstellungsgesprächs zu erleichtern.
Im Folgenden finden Sie einige Fragen zu Deep Learning-Vorstellungsgesprächen, die im Interview häufig gestellt werden und auch beim Testen Ihrer Sprachkenntnisse hilfreich sind:
Teil 1 - Fragen zum Deep Learning-Vorstellungsgespräch (Grundkenntnisse)
In diesem ersten Teil werden grundlegende Fragen und Antworten zu Deep Learning-Vorstellungsgesprächen behandelt
1. Was ist tiefes Lernen?
Antworten:
Der Bereich des maschinellen Lernens, der sich auf tiefe künstliche neuronale Netze konzentriert, die lose vom Gehirn inspiriert sind. Alexey Grigorevich Ivakhnenko hat den ersten General über das Arbeiten im Deep Learning-Netzwerk veröffentlicht. Heute findet es Anwendung in verschiedenen Bereichen wie Computer Vision, Spracherkennung und Verarbeitung natürlicher Sprache.
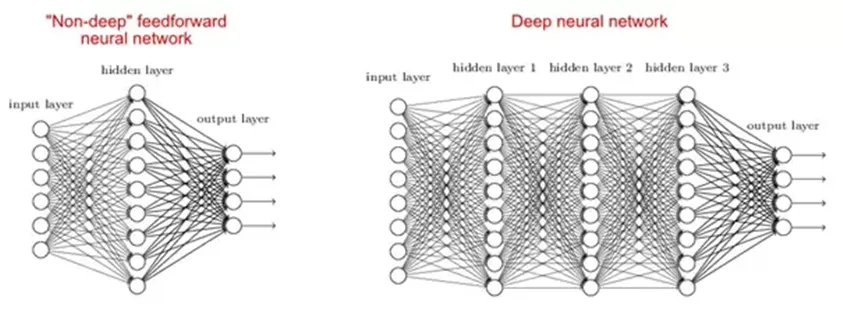
2. Warum sind tiefe Netzwerke besser als flache?
Antworten:
Es gibt Studien, die besagen, dass sowohl flache als auch tiefe Netzwerke für jede Funktion geeignet sind. Da tiefe Netzwerke jedoch mehrere verborgene Schichten aufweisen, die häufig unterschiedliche Typen aufweisen, können sie bessere Features erstellen oder extrahieren als flache Modelle mit weniger Parametern.
3. Was ist die Kostenfunktion?
Antworten:
Eine Kostenfunktion ist ein Maß für die Genauigkeit des neuronalen Netzes in Bezug auf die gegebene Trainingsstichprobe und die erwartete Ausgabe. Es handelt sich um einen einzelnen Wert, nicht um einen Vektor, da er die Leistung des neuronalen Netzwerks als Ganzes angibt. Sie kann wie folgt berechnet werden:
MSE = 1n∑i = 0n (Y i – Yi) 2
Wobei Y und der gewünschte Wert Y das sind, was wir minimieren wollen.
Fahren wir mit den nächsten Deep Learning Interview-Fragen fort.
4. Was ist Gradientenabstieg?
Antworten:
Gradient Descent ist im Grunde ein Optimierungsalgorithmus, mit dem der Wert von Parametern ermittelt wird, mit denen die Kostenfunktion minimiert wird. Es ist ein iterativer Algorithmus, der sich in Richtung des steilsten Abfalls bewegt, wie durch das Negativ des Gradienten definiert. Wir berechnen den Gradientenabfall der Kostenfunktion für einen gegebenen Parameter und aktualisieren den Parameter durch die folgende Formel:
Θ: = Θ – αd∂ΘJ (Θ)
Wobei Θ - der Parametervektor ist, α - Lernrate, J (Θ) - eine Kostenfunktion ist.
5. Was ist Backpropagation?
Antworten:
Backpropagation ist ein Trainingsalgorithmus, der für ein mehrschichtiges neuronales Netzwerk verwendet wird. Bei dieser Methode verschieben wir den Fehler von einem Ende des Netzwerks auf alle Gewichte innerhalb des Netzwerks und ermöglichen so eine effiziente Berechnung des Gradienten. Es kann wie folgt in mehrere Schritte unterteilt werden:
Zur Weitergabe von Trainingsdaten, um eine Ausgabe zu generieren.
Dann kann unter Verwendung von Sollwert und Ausgangswert eine Fehlerableitung in Bezug auf die Ausgangsaktivierung berechnet werden.
Dann setzen wir die Berechnung der Ableitung des Fehlers in Bezug auf die Ausgabeaktivierung für die vorherige zurück und setzen diese für alle ausgeblendeten Ebenen fort.
Verwenden Sie zuvor berechnete Ableitungen für die Ausgabe und alle ausgeblendeten Ebenen, um Fehlerableitungen in Bezug auf die Gewichte zu berechnen.
Und dann aktualisieren wir die Gewichte.
6. Erklären Sie die folgenden drei Varianten des Gefälleverlaufs: Batch, Stochastic und Mini-Batch?
Antworten:
Stochastic Gradient Descent : Hier verwenden wir nur ein einziges Trainingsbeispiel für die Berechnung von Gradienten- und Aktualisierungsparametern.
Batch Gradient Descent : Hier berechnen wir den Gradienten für den gesamten Datensatz und führen die Aktualisierung bei jeder Iteration durch.
Mini-Batch Gradient Descent : Dies ist einer der beliebtesten Optimierungsalgorithmen. Es handelt sich um eine Variante des stochastischen Gradientenabfalls, und hier wird anstelle eines einzelnen Trainingsbeispiels eine kleine Menge von Proben verwendet.
Teil 2 - Deep Learning Interview-Fragen (Fortgeschrittene)
Lassen Sie uns nun einen Blick auf die fortgeschrittenen Deep Learning Interview-Fragen werfen.
7. Was sind die Vorteile eines Minibatch-Gefälle-Abstiegs?
Antworten:
Nachfolgend finden Sie die Vorteile des Minibatch-Gefälleabstiegs
• Dies ist effizienter als der stochastische Gradientenabstieg.
• Die Verallgemeinerung durch Auffinden der flachen Minima.
• Mithilfe von Minibatches können Sie den Gradienten des gesamten Trainingssatzes approximieren, um lokale Minima zu vermeiden.
8. Was ist Datennormalisierung und warum benötigen wir sie?
Antworten:
Die Datennormalisierung wird während der Rückübertragung verwendet. Das Hauptmotiv der Datennormalisierung besteht darin, die Datenredundanz zu verringern oder zu beseitigen. Hier skalieren wir die Werte so, dass sie in einen bestimmten Bereich passen, um eine bessere Konvergenz zu erreichen.
Fahren wir mit den nächsten Deep Learning Interview-Fragen fort.
9. Was ist Gewichtsinitialisierung in neuronalen Netzen?
Antworten:
Die Gewichtsinitialisierung ist einer der wichtigsten Schritte. Eine schlechte Gewichtsinitialisierung kann verhindern, dass ein Netzwerk lernt, aber eine gute Gewichtsinitialisierung hilft dabei, eine schnellere Konvergenz und einen besseren Gesamtfehler zu erzielen. Vorspannungen können im Allgemeinen auf Null initialisiert werden. Die Regel für das Einstellen der Gewichte ist, nahe Null zu sein, ohne zu klein zu sein.
10. Was ist ein Auto-Encoder?
Antworten:
Ein Autoencoder ist ein autonomer Algorithmus für maschinelles Lernen, der das Backpropagation-Prinzip verwendet, bei dem die Zielwerte so festgelegt werden, dass sie den bereitgestellten Eingaben entsprechen. Intern verfügt es über eine verborgene Ebene, die einen Code beschreibt, der zur Darstellung der Eingabe verwendet wird.
Einige wichtige Fakten zum Autoencoder sind:
• Es handelt sich um einen nicht überwachten ML-Algorithmus, der der Hauptkomponentenanalyse ähnelt
• Es minimiert die gleiche Zielfunktion wie die Hauptkomponentenanalyse
• Es ist ein neuronales Netzwerk
• Die Zielausgabe des neuronalen Netzwerks ist seine Eingabe
11. Ist es in Ordnung, eine Verbindung zwischen einem Layer 4-Ausgang und einem Layer 2-Eingang herzustellen?
Antworten:
Ja, dies kann unter Berücksichtigung der Tatsache geschehen, dass die Ausgabe der Schicht 4 aus dem vorherigen Zeitschritt stammt, wie in RNN. Außerdem müssen wir davon ausgehen, dass die vorherige Eingabecharge manchmal mit der aktuellen Charge korreliert.
Fahren wir mit den nächsten Deep Learning Interview-Fragen fort.
12. Was ist die Boltzmann-Maschine?
Antworten:
Mit der Boltzmann-Maschine wird die Lösung eines Problems optimiert. Die Arbeit der Boltzmann-Maschine besteht im Wesentlichen darin, die Gewichte und die Menge für das gegebene Problem zu optimieren.
Einige wichtige Punkte zu Boltzmann Machine -
• Es wird eine wiederkehrende Struktur verwendet.
• Es besteht aus stochastischen Neuronen, die aus einem der beiden möglichen Zustände 1 oder 0 bestehen.
• Die Neuronen sind entweder adaptiv (freier Zustand) oder geklemmt (eingefrorener Zustand).
• Wenn wir ein simuliertes Tempern auf ein diskretes Hopfield-Netzwerk anwenden, wird es zu einer Boltzmann-Maschine.
13. Welche Rolle spielt die Aktivierungsfunktion?
Antworten:
Die Aktivierungsfunktion wird verwendet, um Nichtlinearität in das neuronale Netzwerk einzuführen und es dabei zu unterstützen, komplexere Funktionen zu lernen. Ohne die das neuronale Netz nur die lineare Funktion lernen könnte, die eine lineare Kombination seiner Eingangsdaten ist.
Empfohlene Artikel
Dies war ein Leitfaden für die Liste der Fragen und Antworten zu Deep Learning-Vorstellungsgesprächen, damit der Kandidat diese Deep Learning-Interview-Fragen auf einfache Weise durchgreifen kann. Weitere Informationen finden Sie auch in den folgenden Artikeln
- Erfahren Sie die 10 nützlichsten HBase-Interviewfragen
- Nützliche Fragen und Antworten zu Vorstellungsgesprächen zum maschinellen Lernen
- Die Top 5 der wertvollsten Fragen im Zusammenhang mit Data Science-Vorstellungsgesprächen
- Wichtige Ruby Interview Fragen und Antworten