
Einführung in die Hive-Architektur
Die Hive-Architektur basiert auf dem Hadoop-Ökosystem. Hive hat häufig Interaktionen mit dem Hadoop. Apache Hive kann sowohl mit dem SQL-Datenbanksystem der Domäne als auch mit Map-Reduce umgehen. Hive-Anwendungen können in verschiedenen Sprachen wie Java, Python geschrieben werden. Die Hive-Architektur zeigt, wie eine Hive-Abfragesprache geschrieben wird und wie die Interaktionen zwischen den Programmierern über die Befehlszeilenschnittstelle ausgeführt werden. Die Hive-Abfragesprache übernimmt die Konvertierung aller Hadoop-Cluster-Tasks durch Kartenreduzierung. Wie wir alle wussten, verarbeitet Hadoop Big Data in einer verteilten Umgebung und bildet ein Open-Source-Framework. Mit hive ist es flexibel, die Abfrage zu verwalten und auszuführen, und es ist ein guter Unterstützer, um Funktionen wie Kapselung und Ad-hoc-Abfragen auszuführen. Dieser Artikel enthält eine kurze Einführung in die Hive-Architektur, die sich auf der Hadoop-Ebene befindet, um eine Zusammenfassung in Big Data durchzuführen.
Hive Architecture mit seinen Komponenten
Hive spielt eine wichtige Rolle bei der Datenanalyse und Business Intelligence-Integration und unterstützt Dateiformate wie Textdateien und RC-Dateien. Hive verwendet ein verteiltes System zum Verarbeiten und Ausführen von Abfragen, und der Speicher wird schließlich auf der Festplatte ausgeführt und schließlich unter Verwendung eines Map-Reduction-Frameworks verarbeitet. Es behebt das Optimierungsproblem, das bei Kartenreduzierungs- und Hive-Batch-Jobs auftritt, die im Workflow klar erläutert werden. Hier speichert ein Metaspeicher Schemainformationen. Ein Framework namens Apache Tez wurde für die Leistung von Echtzeit-Abfragen entwickelt.
Die Hauptkomponenten des Bienenstocks sind nachstehend aufgeführt:
- Hive Kunden
- Hive Services
- Hive-Speicher (Meta-Speicher)
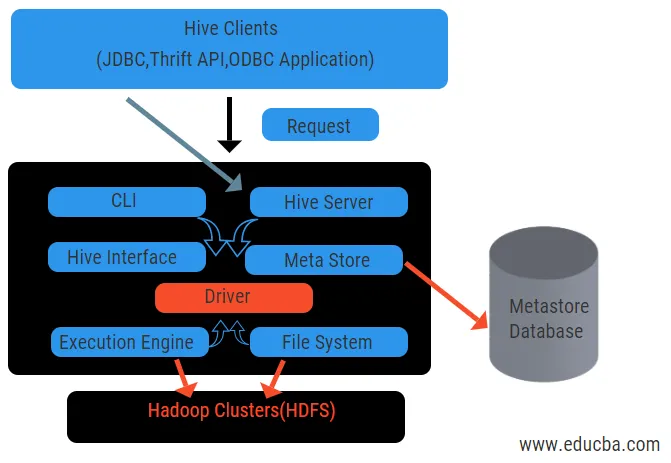
Das obige Diagramm zeigt die Architektur des Hive und seiner Komponentenelemente.
Hive-Kunden:
Dazu gehört eine Thrift-Anwendung zum Ausführen einfacher Hive-Befehle, die für Python, Ruby, C ++ und Treiber verfügbar sind. Diese Vorteile der Clientanwendung gelten für die Ausführung von Abfragen in der Struktur. Hive verfügt über drei Arten der Client-Kategorisierung: Thrift-Clients, JDBC- und ODBC-Clients.
Hive Services:
Um alle Anfragen zu bearbeiten, verfügt hive über verschiedene Services. Alle Funktionen können vom Benutzer im Hive einfach definiert werden. Sehen wir uns alle diese Services kurz an:
- Befehlszeilenschnittstelle (User Interface): Ermöglicht die Interaktion zwischen dem Benutzer und dem Hive, einer Standard-Shell. Es bietet eine grafische Benutzeroberfläche zum Ausführen von Hive Command Line und Hive Insight. Wir können auch Webinterfaces (HWI) verwenden, um die Abfragen und Interaktionen mit einem Webbrowser zu übermitteln.
- Hive-Treiber: Er empfängt Abfragen von verschiedenen Quellen und Clients wie Thrift-Servern und speichert und ruft ODBC- und JDBC-Treiber ab, die automatisch mit dem Hive verbunden werden. Diese Komponente führt eine semantische Analyse durch, um die Tabellen aus dem Metastore zu sehen, der eine Abfrage analysiert. Der Treiber verwendet die Hilfe des Compilers und führt Funktionen wie Parser, Planer, Ausführung von MapReduce-Jobs und Optimierer aus.
- Compiler: Das Parsen und der semantische Prozess der Abfrage werden vom Compiler durchgeführt. Es konvertiert die Abfrage in einen abstrakten Syntaxbaum und aus Kompatibilitätsgründen wieder zurück in die DAG. Das Optimierungsprogramm teilt die verfügbaren Aufgaben auf. Die Aufgabe des Executors besteht darin, die Tasks auszuführen und den Pipeline-Zeitplan der Tasks zu überwachen.
- Ausführungsmodul: Alle Abfragen werden von einem Ausführungsmodul verarbeitet. Ein DAG-Phasenplan wird von der Engine ausgeführt und hilft beim Verwalten der Abhängigkeiten zwischen den verfügbaren Phasen und beim Ausführen dieser Pläne für eine richtige Komponente.
- Metastore: Es fungiert als zentrales Repository zum Speichern aller strukturierten Informationen von Metadaten. Es ist auch ein wichtiger Aspekt für den Hive, da es Informationen wie Tabellen und Partitionierungsdetails sowie die Speicherung von HDFS-Dateien enthält. Mit anderen Worten, wir werden sagen, dass Metastore als Namespace für Tabellen fungiert. Metastore wird als separate Datenbank betrachtet, die auch von anderen Komponenten gemeinsam genutzt wird. Metastore hat zwei Teile, die als Service- und Backlog-Speicher bezeichnet werden.
Das Hive-Datenmodell ist in Partitionen, Buckets und Tabellen unterteilt. Alle diese können gefiltert werden, Partitionsschlüssel haben und die Abfrage auswerten. Die Hive-Abfrage funktioniert mit dem Hadoop-Framework und nicht mit der herkömmlichen Datenbank. Der Hive-Server ist eine Schnittstelle zwischen Remote-Client-Abfragen an den Hive. Die Ausführungs-Engine ist vollständig in einen Hive-Server eingebettet. Sie könnten eine Vielzahl von Anwendungen im Bereich maschinelles Lernen und Business Intelligence im Erkennungsprozess finden.
Arbeitsablauf von Hive:
Hive arbeitet in zwei Arten von Modi: im interaktiven und im nicht interaktiven Modus. Im früheren Modus können alle Hive-Befehle direkt auf die Hive-Shell zugreifen, während der spätere Typ Code im Konsolenmodus ausführt. Daten werden in Partitionen unterteilt, die sich weiter in Gruppen aufteilen. Ausführungspläne basieren auf Aggregation und Datenversatz. Ein zusätzlicher Vorteil der Verwendung von Hive ist die einfache Verarbeitung umfangreicher Informationen und die Verwendung von mehr Benutzeroberflächen.
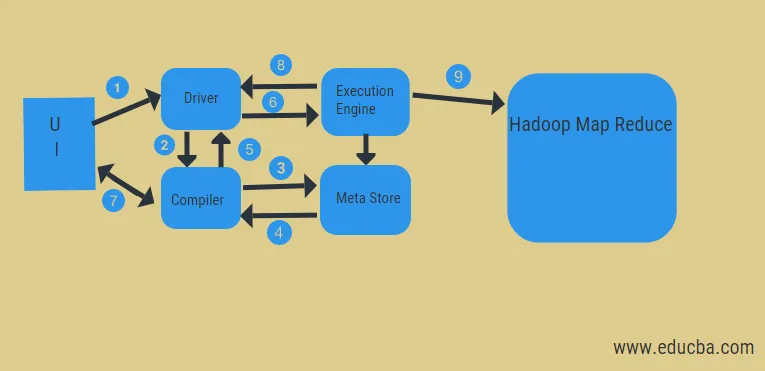
Aus dem obigen Diagramm können wir einen Blick auf den Datenfluss im Hive mit dem Hadoop-System werfen.
Die Schritte umfassen:
- Führen Sie die Abfrage über die Benutzeroberfläche aus
- Holen Sie sich einen Plan aus den Fahreraufgaben der DAG
- Metadatenanforderung aus dem Metastore abrufen
- Senden Sie Metadaten vom Compiler
- Senden Sie den Plan zurück an den Fahrer
- Plan in der Execution Engine ausführen
- Abrufen von Ergebnissen für die entsprechende Benutzerabfrage
- Ergebnisse bidirektional senden
- Execution Engine-Verarbeitung in HDFS mit Map-Reduce- und Fetch-Ergebnissen von den vom Job-Tracker erstellten Datenknoten. Es fungiert als Verbindung zwischen Hive und Hadoop.
Die Aufgabe der Ausführungsmaschine besteht darin, mit den Knoten zu kommunizieren, um die in der Tabelle gespeicherten Informationen abzurufen. Hier werden SQL-Operationen wie create, drop, alter ausgeführt, um auf die Tabelle zuzugreifen.
Fazit:
Wir haben die Hive-Architektur und deren Arbeitsabläufe durchlaufen. Hive führt im Grunde genommen eine Datenmenge von Petabyte durch und ist daher ein Data-Warehouse-Paket auf der Hadoop-Plattform. Da Hive eine gute Wahl für den Umgang mit hohem Datenvolumen ist, hilft es bei der Datenvorbereitung mit der Anleitung der SQL-Schnittstelle, die MapReduce-Probleme zu lösen. Apache Hive ist ein ETL-Tool zur Verarbeitung strukturierter Daten. Wenn Sie die Funktionsweise der Hive-Architektur kennen, können Unternehmen die Funktionsweise des Hive nachvollziehen und haben einen guten Einstieg in die Hive-Programmierung.
Empfohlene Artikel:
Dies war ein Leitfaden für Hive Architecture. Hier diskutieren wir die Hive-Architektur, verschiedene Komponenten und den Workflow des Hives. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren.
- Hadoop-Architektur
- Verwendung von Rubin
- Was ist C ++?
- Was ist MySQL-Datenbank?
- Hive Order By