
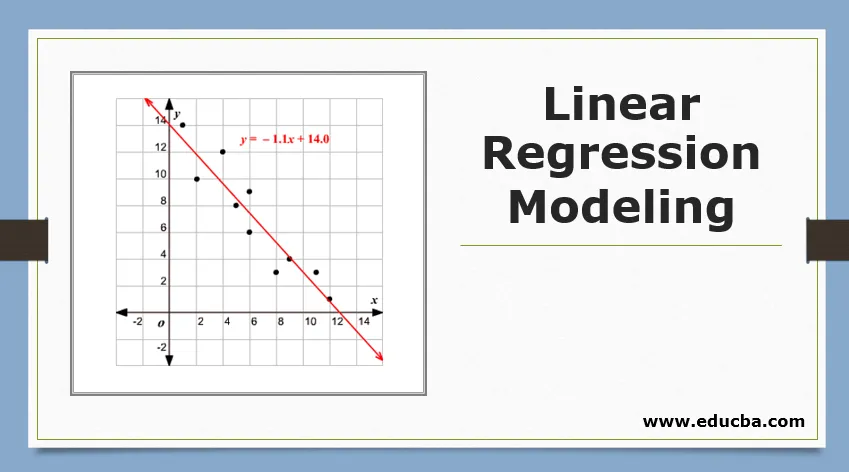
Überblick über die lineare Regressionsmodellierung
Wenn Sie mit dem Erlernen von Algorithmen für maschinelles Lernen beginnen, lernen Sie verschiedene Methoden für ML-Algorithmen kennen, z. In diesem Artikel beschäftigen wir uns mit überwachtem Lernen und einem der grundlegenden, aber leistungsstarken Algorithmen: der linearen Regression.

Betreutes Lernen ist daher das Lernen, bei dem wir die Maschine darin trainieren, die Beziehung zwischen den im Trainingsdatensatz bereitgestellten Eingabe- und Ausgabewerten zu verstehen und dann anhand desselben Modells die Ausgabewerte für den Testdatensatz vorherzusagen. Wenn wir also die Ausgabe oder Beschriftung bereits in unserem Trainingsdatensatz haben und sicher sind, dass die gelieferte Ausgabe entsprechend der Eingabe sinnvoll ist, verwenden wir Supervised Learning. Überwachte Lernalgorithmen werden in Regression und Klassifikation eingeteilt.
Regressionsalgorithmen werden verwendet, wenn Sie feststellen, dass die Ausgabe eine kontinuierliche Variable ist, während Klassifizierungsalgorithmen verwendet werden, wenn die Ausgabe in Abschnitte wie Pass / Fail, Good / Average / Bad usw. unterteilt ist. Für die Durchführung der Regression oder Klassifizierung stehen verschiedene Algorithmen zur Verfügung Aktionen mit linearem Regressionsalgorithmus sind der grundlegende Algorithmus in der Regression.
Bevor ich auf diese Regression eingehe, möchte ich die Basis für Sie festlegen. In der Schule hoffe ich, dass Sie sich an das Konzept der Liniengleichung erinnern. Lassen Sie mich kurz darauf eingehen. Sie haben zwei Punkte auf der XY-Ebene erhalten, dh (x1, y1) und (x2, y2), wobei y1 die Ausgabe von x1 ist und y2 die Ausgabe von x2 ist. Dann lautet die durch die Punkte verlaufende Geradengleichung (y- y1) = m (x-x1) wobei m die Steigung der Linie ist. Wenn Sie nun nach dem Finden der Geradengleichung einen Punkt sagen (x3, y3), können Sie leicht vorhersagen, ob der Punkt auf der Geraden liegt oder wie weit der Punkt von der Geraden entfernt ist. Dies war die grundlegende Regression, die ich in der Schule gemacht hatte, ohne überhaupt zu merken, dass dies im maschinellen Lernen eine so große Bedeutung haben würde. In der Regel versuchen wir, die Gleichungslinie oder -kurve zu identifizieren, die für die Eingabe und Ausgabe des Zugdatensatzes geeignet ist, und verwenden dann dieselbe Gleichung, um den Ausgabewert des Testdatensatzes vorherzusagen. Dies würde zu einem kontinuierlichen Sollwert führen.
Definition der linearen Regression
Die lineare Regression gibt es eigentlich schon sehr lange (etwa 200 Jahre). Es ist ein lineares Modell, dh es wird eine lineare Beziehung zwischen den Eingangsvariablen (x) und einer einzelnen Ausgangsvariablen (y) angenommen. Das y wird hier durch die Linearkombination der Eingangsgrößen berechnet.
Wir haben zwei Arten der linearen Regression
Einfache lineare Regression
Wenn es eine einzelne Eingangsvariable gibt, dh die Liniengleichung ist c
Betrachtet man y = mx + c, so ist dies die einfache lineare Regression.
Multiple lineare Regression
Wenn es mehrere Eingangsvariablen gibt, dh wenn die Liniengleichung als y = ax 1 + bx 2 +… nx n betrachtet wird, dann ist es die multiple lineare Regression. Verschiedene Techniken werden verwendet, um die Regressionsgleichung aus Daten zu erstellen oder zu trainieren, und die häufigste unter ihnen wird als gewöhnliche kleinste Quadrate bezeichnet. Das mit der genannten Methode erstellte Modell wird als gewöhnliche lineare Regression der kleinsten Quadrate oder nur als Regression der kleinsten Quadrate bezeichnet. Modell wird verwendet, wenn die zu bestimmenden Eingabewerte und Ausgabewerte numerische Werte sind. Wenn es nur eine Eingabe und eine Ausgabe gibt, dann ist die gebildete Gleichung eine Liniengleichung, d.h.
y = B0x+B1
wobei die Koeffizienten der Linie mit statistischen Methoden bestimmt werden sollen.
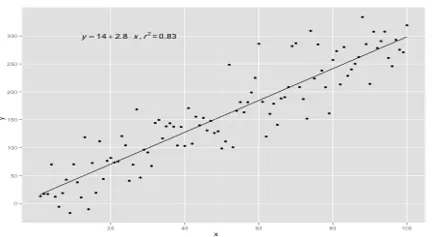
Einfache lineare Regressionsmodelle sind in ML sehr selten, da wir im Allgemeinen verschiedene Eingabefaktoren haben werden, um das Ergebnis zu bestimmen. Wenn es mehrere Eingabewerte und einen Ausgabewert gibt, wird die Gleichung einer Ebene oder Hyperebene gebildet.
y = ax 1 +bx 2 +…nx n
Die Kernidee im Regressionsmodell besteht darin, eine Liniengleichung zu erhalten, die am besten zu den Daten passt. Die Best-Fit-Linie ist diejenige, bei der der gesamte Vorhersagefehler für alle Datenpunkte als so klein wie möglich angesehen wird. Der Fehler ist der Abstand zwischen dem Punkt auf der Ebene und der Regressionsgeraden.
Beispiel
Beginnen wir mit einem Beispiel für die einfache lineare Regression.

Das Verhältnis zwischen Größe und Gewicht einer Person ist direkt proportional. An den Freiwilligen wurde eine Studie durchgeführt, um die Größe und das Idealgewicht der Person zu bestimmen, und die Werte wurden aufgezeichnet. Dies wird als unser Trainingsdatensatz angesehen. Unter Verwendung der Trainingsdaten wird eine Regressionsliniengleichung berechnet, die einen minimalen Fehler ergibt. Diese lineare Gleichung wird dann verwendet, um Vorhersagen für neue Daten zu treffen. Das heißt, wenn wir die Größe der Person angeben, sollte das entsprechende Gewicht durch das von uns entwickelte Modell mit minimalem oder null Fehler vorhergesagt werden.
Y(pred) = b0 + b1*x
Die Werte b0 und b1 müssen so gewählt werden, dass sie den Fehler minimieren. Wenn die Summe der quadratischen Fehler als Metrik zur Bewertung des Modells herangezogen wird, ist das Ziel, eine Linie zu erhalten, die den Fehler am besten reduziert.
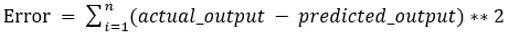
Wir korrigieren den Fehler, damit sich positive und negative Werte nicht gegenseitig aufheben. Für ein Modell mit einem Prädiktor:
Die Berechnung von Intercept (b0) in der Geradengleichung erfolgt durch:
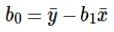
Die Berechnung des Koeffizienten für den Eingabewert x erfolgt durch:
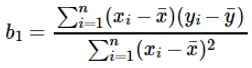
Verständnis des Koeffizienten b 1 :
- Wenn b 1 > 0 ist, sind x (Eingabe) und y (Ausgabe) direkt proportional. Das heißt, eine Erhöhung von x erhöht y, wenn sich die Größe und das Gewicht erhöhen.
- Wenn b 1 <0 ist, sind x (Prädiktor) und y (Ziel) umgekehrt proportional. Das heißt, eine Zunahme von x wird y verringern, wenn die Geschwindigkeit eines Fahrzeugs zunimmt, wobei die benötigte Zeit abnimmt.
Verständnis des Koeffizienten b 0 :
- B 0 nimmt den Restwert für das Modell auf und stellt sicher, dass die Vorhersage nicht verzerrt ist. Wenn wir nicht den Term B 0 haben, wird die Geradengleichung (y = B 1 x) gezwungen, den Ursprung zu durchlaufen, dh die in das Modell eingegebenen Eingangs- und Ausgangswerte ergeben 0. Dies wird jedoch niemals der Fall sein, wenn wir 0 haben bei der Eingabe wird B 0 der Durchschnitt aller vorhergesagten Werte sein, wenn x = 0 ist. Das Setzen aller Prädiktorwerte auf 0 im Fall von x = 0 führt zu Datenverlust und ist häufig unmöglich.
Neben den oben genannten Koeffizienten kann dieses Modell auch unter Verwendung von Normalgleichungen berechnet werden. In meinem nächsten Artikel werde ich die Verwendung normaler Gleichungen und das Entwerfen eines einfachen / mehrlinearen Regressionsmodells weiter diskutieren.
Empfohlene Artikel
Dies ist eine Anleitung zur linearen Regressionsmodellierung. Hier diskutieren wir die Definition, Typen der linearen Regression, die einfache und multiple lineare Regression umfasst, zusammen mit einigen Beispielen. Weitere Informationen finden Sie auch in den folgenden Artikeln.
- Lineare Regression in R
- Lineare Regression in Excel
- Vorausschauende Modellierung
- Wie erstelle ich GLM in R?
- Vergleich von Logistic Regression vs Linear Regression