

Einführung in das Interview mit Data Engineer Fragen und Antworten
Data Engineering ist ein Begriff, dessen sich jeder bewusst ist und der im Bereich Big Data sehr beliebt ist. Data Engineering bezieht sich auf Dateninfrastruktur oder Datenarchitektur. Rohdaten, die aus verschiedenen Quellen wie Social Media, Mobiltelefonen oder dem Internet stammen, müssen für geschäftliche Anforderungen transformiert, bereinigt, profiliert und aggregiert werden. Diese Rohdaten werden auch als Dunkeldaten bezeichnet. Die Praxis des Entwerfens, Architektens und Implementierens des Datenverarbeitungssystems hilft beim Umwandeln der Daten in geeignete Informationen oder Datensätze, wobei solche Informationen oder Datensätze als Data Engineering bezeichnet werden.
Nachstehend finden Sie eine Liste der wichtigsten Fragen und Antworten zum Data Engineer-Interview für 2019:
Wenn Sie nach einem Job suchen, der mit Data Engineer zusammenhängt, müssen Sie sich auf die Fragen des Data Engineer-Vorstellungsgesprächs 2019 vorbereiten. Obwohl alle Fragen zu Data Engineer-Vorstellungsgesprächen unterschiedlich sind und der Umfang eines Jobs auch unterschiedlich ist, können wir Ihnen bei den wichtigsten Fragen zu Data Engineer-Vorstellungsgesprächen mit Antworten behilflich sein, die Ihnen helfen, den Sprung zu wagen und Ihren Erfolg in Ihrem Data Engineer-Vorstellungsgespräch zu erzielen.
1. Was ist Data Engineering?
Antworten:
Data Engineering ist ein Begriff, der im Bereich Big Data sehr verbreitet ist und sich hauptsächlich auf Dateninfrastruktur oder Datenarchitektur bezieht.
Die von vielen Quellen wie Social Media, Mobiltelefonen, www (Internet) generierten Daten sind Rohdaten. Es muss für geschäftliche Anforderungen transformiert, bereinigt, profiliert und aggregiert werden. Wir können diese Rohdaten als Dunkeldaten bezeichnen, die beleuchtet werden, um diese Dunkeldaten nützlich zu machen. Das Entwerfen, Entwickeln und Implementieren des Datenverarbeitungssystems, mit dessen Hilfe die Daten in nützliche Informationen umgewandelt werden, wird als Data Engineering bezeichnet.
2. Erläutern Sie die tägliche Arbeit eines Dateningenieurs?
Antworten:
Der tägliche Job als Dateningenieur besteht aus:
ein. Umgang mit Datenverantwortung innerhalb der Organisation
b. Umgang mit und Pflege von Quellsystemen von Daten und Staging-Bereichen
c. ETL oder ELT durchführen und Daten transformieren
d. Vereinfachung der Datenbereinigung und Verbesserung der Datendeduplizierung und -erstellung
e. Erstellen und Extrahieren von Ad-hoc-Datenabfragen
Die folgende Visualisierung informiert über die Dinge, an denen ein Dateningenieur arbeitet: 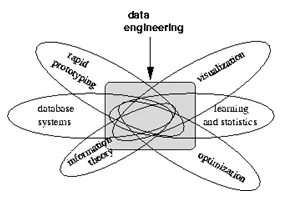
3. Haben Sie Erfahrung mit Datenmodellierung?
Antworten:
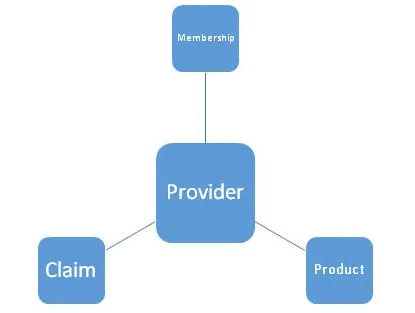
Man kann sagen, dass er / sie an einem Projekt für einen Finanz- / Krankenversicherungskunden gearbeitet hat, bei dem ETL-Tools wie Informatica / Talend / Pentaho usw. verwendet wurden, um die aus einer MySQL / RDS / SQL-Datenbank abgerufenen und gesendeten Daten zu transformieren und zu verarbeiten verteilen diese Informationen an Anbieter, die zur Steigerung ihrer Einnahmen beitragen können. Man kann unten die Architektur des Datenmodells auf hoher Ebene zeigen. Es besteht aus einem Primärschlüssel, einer Entität, Attributen, einer Beziehung, Einschränkungen usw.
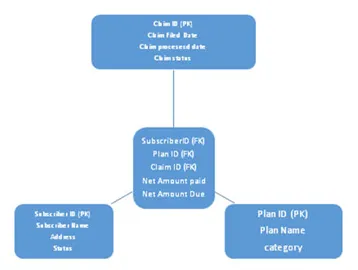
4. Was sind verschiedene Arten von Entwurfsschemata in der Datenmodellierung? Mit einem Beispiel erklären?
Antworten:
Bei der Datenmodellierung gibt es zwei Arten von Schemata:
ein. Sternschema
Dieses Schema ist in zwei unterteilt: eine Faktentabelle und eine Dimensionstabelle, in der alle Dimensionstabellen mit einer Faktentabelle verbunden sind. Die Fremdschlüssel-Faktentabelle bezieht sich auf Primärschlüssel, die in Dimensionstabellen vorhanden sind. Siehe unten Architektur des Sternschemas:
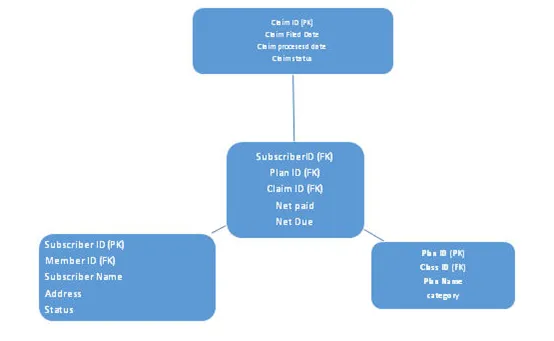
b. Schneeflocke Schema
In diesem Schema wird der Normalisierungsgrad erhöht, hier bleibt die Faktentabelle gleich wie im Sternschema, hier werden Dimensionstabellen normalisiert. Aufgrund vieler Ebenen von Maßtabellen sieht es aus wie eine Schneeflocke, daher der Name Schneeflockenschema. Siehe unten architektur: -
5. Welches ETL-Tool verwenden Sie und wie lässt es sich am besten mit anderen vergleichen?
Antworten:
Man kann sagen, dass er / sie Informatica aufgrund vieler Punkte als ETL-Tool verwendet hat. Zuallererst ist dies, dass Informatica gemäß Gartner Magic Quadrant für Datenintegrations-Tools das zehnte Jahr in Folge führend ist. Es ist einfach zu bedienen und zu erlernen und verfügt über Funktionen zum Verbinden mit einer Vielzahl von Quelldaten und Datentypen, wiederverwendbaren Komponenten und Funktionen, die es bei ETL-Entwicklern am beliebtesten machen. Es hat auch einen eigenen Scheduler, was ein weiterer Vorteil ist, wenn andere ETL-Tools einen externen Scheduler verwenden müssen, um die Jobs zu planen.
6. Welche Technologien / Programmiersprache sollte man haben / lernen, ein Dateningenieur zu sein?
Antworten:
Mathematik (lineare Algebra und Wahrscheinlichkeit)
Statistik (zusammenfassende Statistik)
Techniken des maschinellen Lernens
R- und SAS-Sprachen
SQL-Datenbanken, Hive QL
Python (meistens verwendet)
Abgesehen von diesen sollte man problemlösende, analytische und architektonische Kenntnisse der Datenbank haben.
7. Was sind einige häufige Probleme, mit denen Dateningenieure konfrontiert sind?
Antworten:
1. Echtzeitintegration / kontinuierliche Integration
2. Das Speichern großer Datenmengen ist ein Problem, die Informationen aus diesen Daten sind ein weiteres Problem.
3. Welche Tools können verwendet werden, um die beste Leistung, Speicherung, Effizienz und Ergebnisse zu erzielen?
4. Ist der Speicher skaliert? Angenommen, Sie wissen, wie lange die Verarbeitung des gesamten Datensatzes dauern wird.
5. Berücksichtigen Sie die Prozessoren und die RAM-Konfiguration
6. Wie gehe ich mit Ausfällen um? Gibt es Fehlertoleranz?
8. Inwiefern unterscheidet sich Data Architect von Data Engineer?
Antworten:
Datenarchitekt ist die Person für die Verwaltung der Daten, insbesondere wenn es sich um unterschiedliche Anzahlen einer Vielzahl von Datenquellen handelt. Man sollte gründliche Kenntnisse darüber haben, wie eine Datenbank funktioniert, wie sich Daten auf geschäftliche Probleme beziehen und wie die Änderungen die Datennutzung des Unternehmens stören, und dann wird der Datenarchitekt die Datenarchitektur entsprechend manipulieren / transformieren.
Die Hauptverantwortung von Data Architect liegt in den Bereichen Data Warehousing, Entwicklung der Datenarchitektur oder Enterprise Data Hub / Warehouse.
Während ein Data Engineer bei der Installation von Data Warehouse-Lösungen, der Datenmodellierung, der Entwicklung und dem Testen der Datenbankarchitektur hilft.
9. Beschreiben Sie einen Zeitpunkt, zu dem Sie einen neuen Anwendungsfall für eine vorhandene Datenbank gefunden haben, der sich positiv auf das Geschäft ausgewirkt hat.
Antworten:
Während in der Ära von Big Data mit SQL werden folgende Funktionen fehlen:
ein. RDBMS sind schemaorientierte DBs, daher sind strukturierte Daten besser als halbstrukturierte oder unstrukturierte Daten.
b. Unvorhersehbare und unstrukturierte Daten können nicht verarbeitet werden.
c. Es ist nicht horizontal skalierbar, dh parallele Ausführung und Speicherung sind in SQL nicht möglich.
d. Sobald sich die Anzahl der Benutzer erhöht, tritt ein Leistungsproblem auf.
e. Es wird hauptsächlich für die Online-Transaktionsverarbeitung verwendet.
Um diese Nachteile zu überwinden, können wir NoSQL DB verwenden, also nicht nur SQL.
Daher kann man im Projekt verschiedene NoSQL-DB-Typen wie Cassandra, Mongo DB, Graph DB, HBase usw. verwenden.
10. Haben Sie Erfahrung in einer Cloud-Computing-Umgebung? Welche Vorteile sehen Sie in einer Arbeit?
Antworten:
Man kann sagen, dass die Cloud-Computing-Umgebung bereit ist, die Umgebung für Produktion, Entwicklung und Tests zu verschieben, ohne daran zu denken, viele Instanzen / Linux / Windows-Server zusammen zu integrieren. Es gibt verschiedene Cloud-Computing-Dienste in einem Markt wie AWS (Amazon Web Services), Azure (Microsoft) und GCP (Google Cloud Platform). Der Cloud-Computing-Dienst bietet die folgenden Funktionen: Flexibilität, dh die Umgebung wird nach Bedarf skaliert, Notfallwiederherstellung durch Erstellen von Sicherungen und Snapshots, Arbeiten mit VPNs von jedem Ort aus, Sichere Umgebung und Umweltfreundlichkeit, da er auf Standardhardware, dh Mehrzweckcomputern, funktioniert sind kostengünstig.
Fazit
Im obigen Blog haben wir die am häufigsten gestellten Fragen zum Thema Data Engineer zusammengestellt. Wie kann man dies mit Feature-Punkten beantworten?
Empfohlener Artikel:
Dies ist ein umfassender Leitfaden für die Fragen und Antworten zum Vorstellungsgespräch für Dateningenieure, damit der Kandidat diese Fragen zum Vorstellungsgespräch für Dateningenieure problemlos durchgreifen kann. Dieser Artikel enthält alle wichtigen Fragen und Antworten zum Vorstellungsgespräch für Data Engineer. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Wichtigste Azure Paas vs Iaas
- Big Data Interview Fragen
- Die 5 wichtigsten Fragen zum Elasticsearch-Interview
- PIG Interview Fragen und Antworten
- Die Top 5 der wertvollsten Fragen im Zusammenhang mit Data Science-Vorstellungsgesprächen