
Unterschied zwischen HBase und Cassandra
HBase ist eine Datenbank, die das verteilte Hadoop-Dateisystem zur Speicherung verwendet. HBase ist ein wichtiger Bestandteil von HDFS und läuft auf dem Hadoop-Cluster. HBase ist keine traditionelle relationale Datenbank, sondern erfordert einen anderen Datenmodellierungsansatz. Cassandra arbeitet mit dem Datenreplikationsmodell, sodass bei Nichtverfügbarkeit eines Knotens kein Datenverlust auftritt. Cassandra ist eine verteilte Datenbank, mit der ein Client von jedem Cluster und von jedem Knoten aus auf Daten zugreifen kann
1.1) Cassandra:
Es wurde von Facebook gestartet, da es immer auf der Bewerbungsanforderung basiert. Cassandra wurde 2005 gestartet und 2008 der Öffentlichkeit zugänglich gemacht. Cassandra wurde für permanente Anwendungen wie soziale Netzwerke wie Facebook und Twitter entwickelt.
Cassandra arbeitet mit einer "Always-On" -Architektur und verfügt über ein Aktiv-Aktiv-Knotenmodell, sodass es kein SPoF (Single Point of Failure) gibt. CQL (Cassandra Query Language) ist die Abfragesprache von Cassandra, hat jedoch die gleiche Syntax wie SQL. Es unterstützt alle gängigen Betriebssysteme wie Linux, Unix, OSX und Windows.
Immer auf:
Cassandra ist eine Datenbank mit einem Verteilungsmodell, und alle Knoten im Cluster sind gleich. Die Daten werden auf konfigurierbaren Knoten repliziert. von Knoten führt nicht zum Verlust der Daten.
(Immer am Modell)
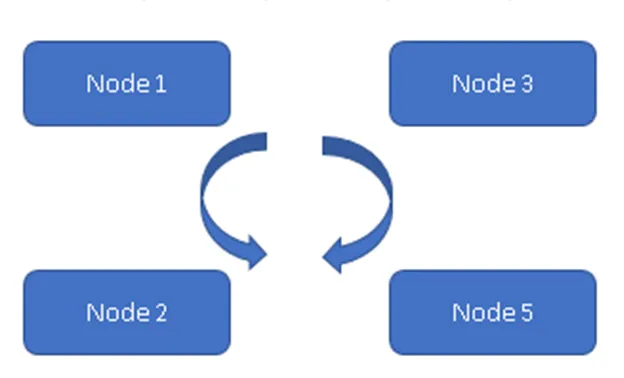
In Abbildung 1 sind alle vier Knoten miteinander synchronisiert und replizieren die Daten innerhalb des Clusters. Alle arbeiten am Aktiv-Aktiv-Modell, sodass bei einem Knotenausfall keine Daten verloren gehen. Ein Client kann die Daten von den übrigen verfügbaren Knoten / Knoten lesen.
1.2) HBase:
HBase ist eine NoSQL-basierte Datenbank, die für die Verarbeitung von Abfragen in großen Tabellen mit Milliarden von Zeilen und Millionen von Spalten entwickelt wurde und auf einem Cluster von Standardhardware / normaler Hardware ausgeführt wird. Es bietet Ihnen Echtzeit-Abfragemöglichkeiten mit der Geschwindigkeit eines „ Schlüssel- / Wertespeichers “ .
HBase basiert / arbeitet auf einem vierdimensionalen Datenmodell.
- Zeilen-ID / Zeilenschlüssel
- Spaltenfamilie.
- Schlüssel-Wert-Paare.
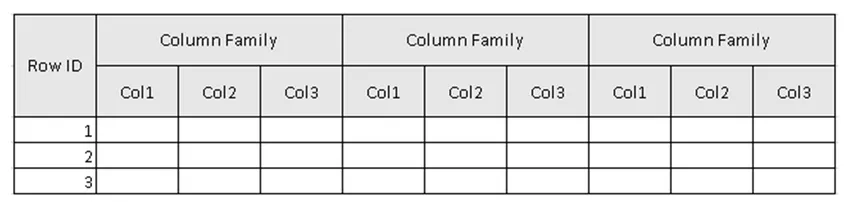
(Abbildung 2, Beispielschema der Tabelle in HBase.)
In Abbildung 2 ist Tabelle die Auflistung der Spaltenfamilie und Spaltenfamilie die Auflistung der Spalten. Spalten sind die Sammlung von Schlüssel-Wert-Paaren
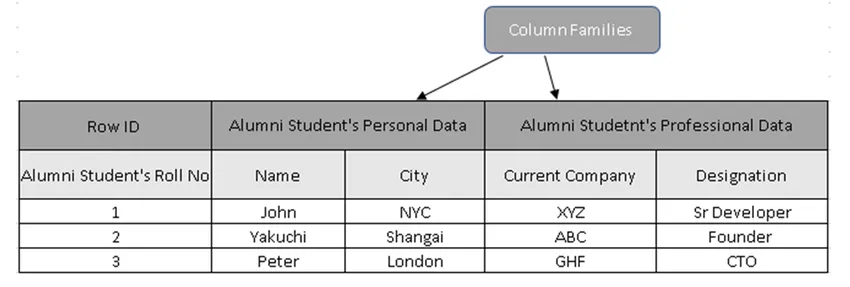
(Abbildung 3, Probentabelle in HBase)
In Abbildung 3 sind Spaltenfamilien die Sammlung der Daten von Alumni-Schülern, und Zeilen-IDs (Zeilenschlüssel) enthalten die Schülerrolle Nr.
Tatsächlich enthalten Zeilenschlüssel den eindeutigen Wert für die Daten der Spaltenfamilie. Mit dem Zeilenschlüssel können alle Details extrahiert werden. Gründe dafür sind, dass spaltenorientierte Datenbanken viel schneller sind als herkömmliche Datenbanken.
Apache HBase kann für zufälligen Lese- / Schreibzugriff verwendet werden und bietet Fehlerunterstützung. Es unterstützt auch die Replikation und Bearbeitung des Verteilungsdatenbankmodells.
Head to Head Vergleich von HBase vs Cassandra (Infografik)
Unten sehen Sie den 9 größten Unterschied zwischen HBase und Cassandra
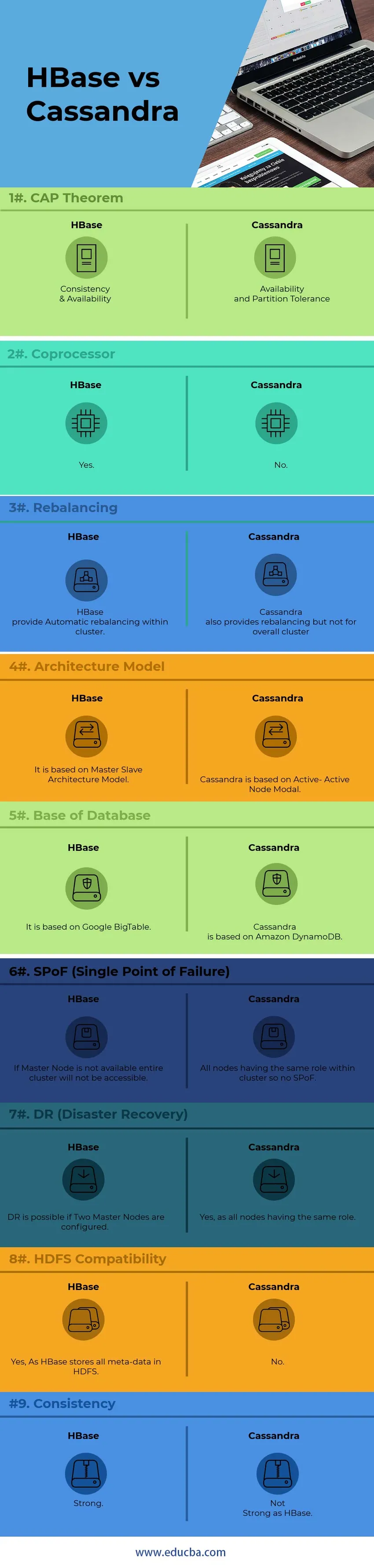 Hauptunterschiede zwischen HBase und Cassandra
Hauptunterschiede zwischen HBase und Cassandra
Nachfolgend sind die Punktelisten aufgeführt, die die wichtigsten Unterschiede zwischen HBase und Cassandra beschreiben:
1) Für die interne Knotenkommunikation verwendet Cassandra das GOSSIP-Protokoll, während HBase auf Zookeeper basiert. Die Dienste des GOSSIP-Protokolls sind in Cassandra integriert. Die andere Seite von Zookeeper ist eine völlig separate Distributionsanwendung.
2) In der Cassandra-Architektur arbeiten alle Knoten als aktive Knoten, während der HBase-Architekt dem Master-Slave-Knoten-Modell folgt. Im Active-Active-Node-Modell gibt es kein SPoF (Single Point of Failure). In HBase ist der Zugriff auf den gesamten Cluster nicht möglich, wenn der Masterknoten ausfällt.
3) HBase-Unterstützung Binärbaum-Suchmodell, während Cassandra das B-Baum-Modell nicht unterstützt Ohne B-Baum können Sie die Spaltenfamilie des Benutzers nicht nach allen Personen mit einem Jahrestag im April durchsuchen, während Sie nach allen Personen suchen können, die in Peking mit einem Jahrestag leben Jubiläum im April.
4) HBase unterstützt C-, C ++ -, Java-, Python- und Scala-Skriptsprachen, während Cassandra auch JavaScript und Ruby unterstützt.
5) HBase hat eine Funktion, die als Coprozessor bezeichnet wird, während Cassandra diese Funktion derzeit nicht hat. Coprozessoren bieten eine Bibliothek und eine Laufzeitumgebung für die Ausführung von Benutzercode innerhalb des HBase-Regionsservers und der Masterprozesse.
6) HBase wurde für die Unterstützung von Data Warehouse entwickelt, während Cassandra perfekt für Anwendungen ist, die zu jeder Zeit ausgeführt werden, z. B. Web- und mobile Anwendungen.
7) HBase-Abfragesprache ist eine benutzerdefinierte Sprache, die gelernt werden muss, während Cassandra ihre eigene entwickelte CQL-Sprache (Cassandra Query Language) verwendet, die SQL-ähnlich ist
8) Cassandra zu verwalten ist viel einfacher als HBase. In Cassandra muss ein einzelner Java-Prozess pro Knoten ausgeführt werden, während für HBase ein voll funktionsfähiges HDFS, mehrere HBase-Prozesse und ein Zookeeper-System erforderlich sind.
9) HBase führt eine End-to-End-Checksumme und eine automatische Neuverteilung durch, während Cassandra die Neuverteilung des Clusters insgesamt nicht unterstützt.
10) Cassandra arbeitet basierend auf dem „ CAP-Theorem“ am AP-Modell, während HBase das CP-Modell ist.
CAP-Satz
Dieser Satz wird für verteilte Systeme verwendet. C steht für Consistency, A bedeutet Availability & P ist Partition Tolerance. Der CAP-Satz wird nachfolgend erläutert:
C (Konsistenz): Konsistenz bedeutet, dass, wenn jemand einen Wert in eine Datenbank geschrieben hat, andere den gleichen Wert sofort lesen können.
A (Verfügbarkeit) : Verfügbarkeit bedeutet, dass wenn einige Knoten in Ihrem Cluster nicht verfügbar sind (Knoten sind aufgrund eines Problems ausgefallen / nicht im Cluster aktiv), dies keine Auswirkungen auf den gesamten Cluster hat und das verteilte System / die verteilte Datenbank für den Zugriff auf die Daten verfügbar ist. Der Cluster wird für alle Arten von Aufgaben zugänglich sein.
P (Partitionstoleranz): Partitionstoleranz bedeutet, dass ein Rechenzentrum immer noch ausfällt, was sich nicht auf die auf den Knoten vorhandenen Daten auswirken sollte, und dass jederzeit auf alle Daten zugegriffen werden kann. Das heißt, die Partitionstoleranz ermöglicht eine bessere Replikation von Daten in andere Rechenzentren sowie in die Clusterumgebung.
HBase vs Cassandra Vergleichstabelle
| Punkte | HBase | Kassandra |
| CAP-Satz | Konsistenz und Verfügbarkeit | Verfügbarkeit und Partitionstoleranz |
| Coprozessor | Ja | Nein |
| Neugewichtung | HBase bietet eine automatische Neuverteilung innerhalb eines Clusters. | Cassandra bietet auch einen Ausgleich, jedoch nicht für den gesamten Cluster |
| Architekturmodell | Es basiert auf dem Master-Slave-Architekturmodell | Cassandra basiert auf Active-Active Node Modal |
| Datenbankbasis | Es basiert auf Google BigTable | Cassandra basiert auf Amazon DynamoDB |
| SPoF (Single Point of Failure) | Wenn der Hauptknoten nicht verfügbar ist, kann nicht auf den gesamten Cluster zugegriffen werden | Alle Knoten haben die gleiche Rolle innerhalb des Clusters, also kein SPoF |
| DR (Notfallwiederherstellung) | DR ist möglich, wenn zwei Master-Knoten konfiguriert sind. | Ja, da alle Knoten dieselbe Rolle haben |
| HDFS-Kompatibilität | Ja, da HBase alle Metadaten in HDFS speichert | Nein |
| Konsistenz | Stark | Nicht so stark wie HBase |
Fazit - HBase vs Cassandra
Facebook und eine andere Social-Networking-Seite würden HBase vorziehen (früher verwendeten beide Cassandra, siehe Facebook-Post), da der Bankensektor auf der anderen Seite nach Sicherheit für jede Finanztransaktion sucht, sodass sie Cassandra vor HBase wählen würden.
Cassandra Die wichtigsten Merkmale sind Hochverfügbarkeit, minimaler Administrationsaufwand und kein SPoF (Single Point of Failure). Die andere Seite von HBase eignet sich zum schnelleren Lesen und Schreiben der Daten mit linearer Skalierbarkeit.
Unternehmen wie Verizon, Bloomberg, Bank of America und viele mehr nutzen HBase und Cassandra wird von wichtigen sozialen Netzwerken wie Twitter, Facebook usw. verwendet.
Wir können nicht schlussfolgern, welches das Beste ist, HBase und Cassandra haben beide ihre eigenen Vor- und Nachteile. Die tatsächliche Leistung von HBase- und Cassandra-Datenbanken wird in der Produktionsumgebung angezeigt.
Empfohlene Artikel:
Dies war ein Leitfaden für HBase vs Cassandra, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Hadoop vs Apache Spark - Interessante Dinge, die Sie wissen müssen
- Wie knackt man das Hadoop-Entwicklerinterview?
- Top 5 Big Data-Trends
- 5 Herausforderungen von Big Data Analytics