

Einführung in Decision Tree in Data Mining
In der heutigen Welt von „Big Data“ bedeutet der Begriff „Data Mining“, dass wir große Datenmengen untersuchen und mit den Daten „Mining“ durchführen müssen, um den wichtigen Saft oder das Wesentliche dessen herauszuholen, was die Daten aussagen möchten. Eine sehr analoge Situation ist die des Kohlebergbaus, wo verschiedene Werkzeuge benötigt werden, um die tief im Boden vergrabene Kohle abzubauen. Eines der Tools im Data Mining ist „Decision Tree“. Daher ist Data Mining an sich ein weites Feld, in dem wir uns in den nächsten Absätzen eingehend mit dem Entscheidungsbaum-Tool in Data Mining befassen.
Algorithmus des Entscheidungsbaums im Data Mining
Ein Entscheidungsbaum ist ein beaufsichtigter Lernansatz, bei dem wir die vorhandenen Daten trainieren, indem wir bereits wissen, was die Zielvariable tatsächlich ist. Wie der Name schon sagt, hat dieser Algorithmus eine Baumstruktur. Betrachten wir zuerst den theoretischen Aspekt des Entscheidungsbaums und dann diesen in einem grafischen Ansatz. Im Entscheidungsbaum teilt der Algorithmus den Datensatz auf der Grundlage des wichtigsten oder bedeutendsten Attributs in Teilmengen auf. Das höchstwertige Attribut wird im Wurzelknoten angegeben, und hier findet die Aufteilung des gesamten im Wurzelknoten vorhandenen Datensatzes statt. Diese Aufteilung wird als Entscheidungsknoten bezeichnet. Falls keine Aufteilung mehr möglich ist, wird dieser Knoten als Blattknoten bezeichnet.
Um den Algorithmus anzuhalten, um ein überwältigendes Stadium zu erreichen, wird ein Stoppkriterium verwendet. Eines der Stoppkriterien ist die Mindestanzahl von Beobachtungen im Knoten, bevor die Aufteilung erfolgt. Beim Anwenden des Entscheidungsbaums beim Aufteilen des Datasets muss darauf geachtet werden, dass viele Knoten möglicherweise nur verrauschte Daten enthalten. Um auf Ausreißer oder verrauschte Datenprobleme zu reagieren, verwenden wir Techniken, die als Datenbereinigung bekannt sind. Das Bereinigen von Daten ist nichts anderes als ein Algorithmus zum Klassifizieren von Daten aus der Teilmenge, der es schwierig macht, aus einem bestimmten Modell zu lernen.
Der Decision Tree-Algorithmus wurde vom Maschinenforscher J. Ross Quinlan als ID3 (Iterative Dichotomiser) veröffentlicht. Später wurde C4.5 als Nachfolger von ID3 veröffentlicht. Sowohl ID3 als auch C4.5 sind ein gieriger Ansatz. Betrachten wir nun ein Flussdiagramm des Entscheidungsbaum-Algorithmus.
Für unser Pseudocode-Verständnis würden wir "n" Datenpunkte mit jeweils "k" Attributen nehmen. Das folgende Flussdiagramm wird unter Berücksichtigung von "Informationsgewinn" als Bedingung für eine Aufteilung erstellt.
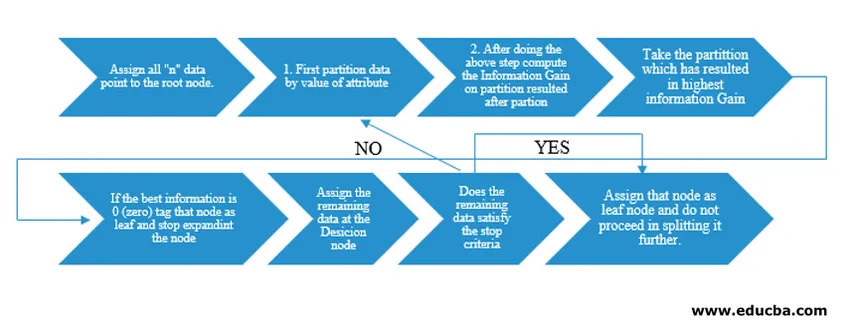
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Anstelle von Information Gain (IG) können wir auch den Gini-Index als Kriterium für einen Split verwenden. Um den Unterschied zwischen diesen beiden Kriterien in Laienbegriffen zu verstehen, können wir uns diesen Informationsgewinn als Entropiedifferenz vor und nach der Aufteilung vorstellen (Aufteilung auf der Grundlage aller verfügbaren Merkmale).
Entropie ist wie Zufall und wir würden einen Punkt nach der Teilung erreichen, um den geringsten Zufallszustand zu haben. Daher muss der Informationsgewinn für die Funktion, die wir aufteilen möchten, am größten sein. Wenn wir uns für eine Unterteilung auf der Basis des Gini-Index entscheiden möchten, ermitteln wir den Gini-Index für verschiedene Attribute und ermitteln anhand desselben den gewichteten Gini-Index für verschiedene Teilungen und verwenden den mit dem höheren Gini-Index, um den Datensatz zu teilen.
Wichtige Begriffe des Entscheidungsbaums im Data Mining
Nachfolgend sind einige wichtige Begriffe eines Entscheidungsbaums im Data Mining aufgeführt:
- Wurzelknoten: Dies ist der erste Knoten, an dem die Aufteilung stattfindet.
- Blattknoten: Dies ist der Knoten, nach dem keine Verzweigung mehr erfolgt.
- Entscheidungsknoten: Der nach dem Aufteilen von Daten von einem vorherigen Knoten gebildete Knoten wird als Entscheidungsknoten bezeichnet.
- Zweig: Unterabschnitt eines Baums, der Informationen über die Folgen der Teilung am Entscheidungsknoten enthält.
- Bereinigung: Wenn Unterknoten eines Entscheidungsknotens entfernt werden, um auf Ausreißer oder verrauschte Daten zu reagieren, spricht man von Bereinigung. Es wird auch das Gegenteil von Spaltung angenommen.
Anwendung des Entscheidungsbaums im Data Mining
Decision Tree verfügt über eine Flowchart-Architektur, die mit dem Typ des Algorithmus integriert ist. Es hat im Wesentlichen ein Muster der Art "Wenn X, dann Y, sonst Z", während die Aufteilung erfolgt. Diese Art von Muster wird zum Verständnis der menschlichen Intuition im programmatischen Bereich verwendet. Daher kann man dies ausgiebig bei verschiedenen Kategorisierungsproblemen verwenden.
- Dieser Algorithmus kann in dem Bereich weit verbreitet sein, in dem die Zielfunktion in Bezug auf die durchgeführte Analyse in Beziehung steht.
- Wann gibt es zahlreiche Handlungsoptionen zur Verfügung.
- Ausreißeranalyse.
- Verständnis der umfangreichen Funktionen für das gesamte Dataset und "Minen" der wenigen Funktionen aus einer Liste mit Hunderten von Funktionen in Big Data.
- Auswahl des besten Fluges, um zu einem Ziel zu gelangen.
- Entscheidungsprozess basierend auf verschiedenen Umstandssituationen.
- Abwanderungsanalyse.
- Stimmungsanalyse.
Vorteile von Decision Tree
Im Folgenden werden einige Vorteile des Entscheidungsbaums erläutert:
- Verständlichkeit: Die Art und Weise, wie der Entscheidungsbaum in grafischer Form dargestellt wird, macht es für Personen mit nicht-analytischem Hintergrund leicht verständlich. Gerade für Führungskräfte, die sich ansehen wollen, welche Merkmale wichtig sind, kann schon ein Blick auf den Entscheidungsbaum ihre Hypothese aufstellen.
- Datenexploration: Wie bereits erwähnt, ist das Erhalten von signifikanten Variablen eine Kernfunktionalität des Entscheidungsbaums. Wenn Sie diese verwenden, können Sie während der Datenexploration herausfinden, welche Variable im Verlauf der Data Mining- und Modellierungsphase besondere Aufmerksamkeit erfordern würde.
- Während der Datenvorbereitungsphase wird nur sehr wenig von Menschen eingegriffen, und aufgrund des Zeitaufwands während der Datenvorbereitung wird die Bereinigung verringert.
- Decision Tree ist in der Lage, sowohl kategoriale als auch numerische Variablen zu verarbeiten und auch Klassifizierungsprobleme mehrerer Klassen zu lösen.
- Als Teil der Annahme haben Entscheidungsbäume keine Annahme von einer räumlichen Verteilungs- und Klassifikatorstruktur.
Fazit
Schließlich bringen Entscheidungsbäume eine ganz andere Klasse von Nichtlinearität mit sich und sorgen für die Lösung von Problemen in Bezug auf Nichtlinearität. Dieser Algorithmus ist die beste Wahl, um ein Denken auf Entscheidungsebene des Menschen nachzuahmen und es in einer mathematisch-grafischen Form darzustellen. Bei der Ermittlung der Ergebnisse aus neuen unsichtbaren Daten wird ein Top-Down-Ansatz verfolgt, der dem Prinzip der Teilung und Eroberung folgt.
Empfohlene Artikel
Dies ist eine Anleitung zum Entscheidungsbaum in Data Mining. Hier diskutieren wir den Algorithmus, die Wichtigkeit und die Anwendung des Entscheidungsbaums beim Data Mining sowie seine Vorteile. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Data Science Maschinelles Lernen
- Arten von Datenanalysetechniken
- Entscheidungsbaum in R
- Was ist Data Mining?
- Leitfaden zu verschiedenen Methoden der Datenanalyse