

Wie installiere ich NLTK?
Der folgende Artikel NLTK installieren enthält eine Übersicht über die Installation von NLTK. NLTK ist eine Reihe von Bibliotheken für die Verarbeitung natürlicher Sprachen. Es ist eine Plattform zum Erstellen von Python-Programmen zur Verarbeitung natürlicher Sprache. NLTK ist in der Programmiersprache Python geschrieben. Es wurde von Steven Bird und Edward Loper entwickelt. Es unterstützt Forschung und Lehre in NLP oder eng verwandten Bereichen, darunter Kognitionswissenschaft, empirische Linguistik, Informationsbeschaffung, künstliche Intelligenz und maschinelles Lernen. NLTK bietet eine benutzerfreundliche Oberfläche.
NLTK (Natural Language Toolkit)
- Die Verarbeitung natürlicher Sprache (NLP) ist ein Teil der künstlichen Intelligenz, die die vom Menschen gesprochene Sprache verarbeitet. Auf diese Weise können Menschen mit Computern interagieren, auch wenn sie nicht wissen, wie sie damit umgehen sollen. Mit NLP müssen Menschen den Befehl nur Computern diktieren. Durch das maschinelle Lernen wird die Verarbeitung natürlicher Sprachen immer beliebter und einfacher zu implementieren. Es ist im Grunde die Technik, mit Menschen zu interagieren und Aktionen mit Sprachbefehlen auszuführen.
- Auf diese Weise können Geräte auch von Anfängern ohne technologische Kenntnisse verwendet werden. Die Implementierung der Verarbeitung natürlicher Sprache ist jedoch nicht einfach, da eine Sprache, die vom Menschen gesprochen wird, keine definitive Struktur hat. Es ist mehrdeutig und hängt von Kontextwörtern ab, die eine andere Bedeutung haben können.
- NLTK verfügt über mehr als 50 Korpora- und lexikalische Quellen wie WordNet, Problem Report Corpus, Penn Treebank Corpus usw. Es enthält auch einen Leitfaden, in dem die Konzepte der Sprachverarbeitung durch Toolkits und Programmiergrundlagen von Python erläutert werden die keine tiefen Programmierkenntnisse haben. Es verfügt über eine breite Palette von Paketen, die es zu einem der leistungsstarken Toolkits für NLP machen. Tokenization, Lemmatization, Stemming, Parsing, Character Count, Interpunktion, Word Count sind einige dieser Pakete.
Installieren Sie NLTK für Windows
Unten finden Sie die Anweisungen zum Installieren von NLTK in Windows. Diese basieren auf der Annahme, dass Python nicht auf dem System installiert ist. NLTK erfordert Python-Versionen 2.7, 3.5 und höher.
Schritt 1: Laden Sie die neueste Version von Python für Windows über den folgenden Link herunter
https://www.python.org/downloads/

Schritt 2: Klicken Sie auf die heruntergeladene EXE-Datei, um sie auszuführen.

Schritt 3: Wählen Sie Installation anpassen.
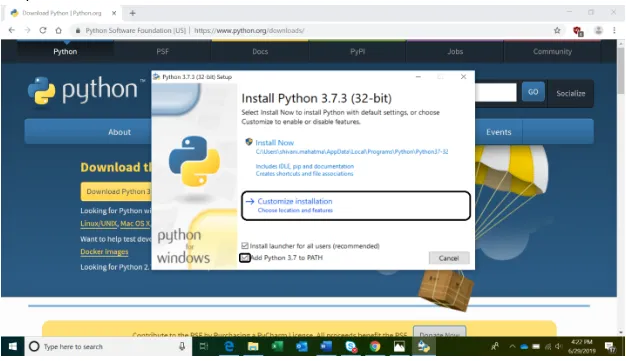
Schritt 4: Überprüfen Sie alle Funktionen, insbesondere "pip", da dies bei der Installation von NLTK hilfreich ist, und klicken Sie auf "Weiter".
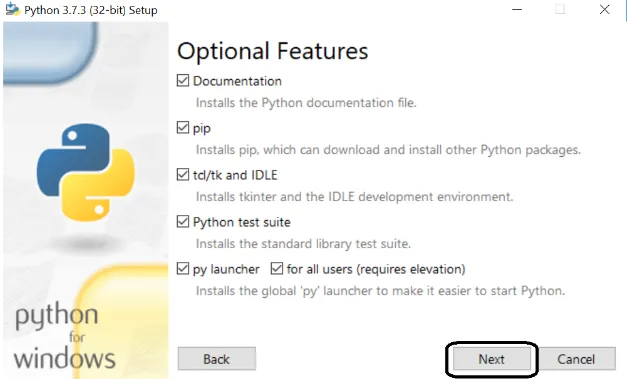
Schritt 5: Wählen Sie im nächsten Bildschirm erweiterte Optionen aus, wählen Sie den Pfad aus und klicken Sie auf Installieren.
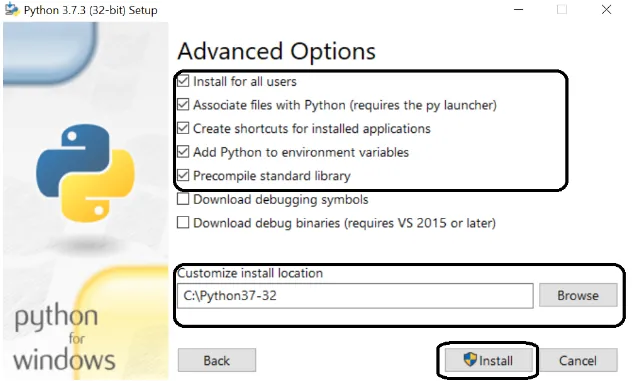
Schritt 6: Sobald die Installation erfolgreich war, schließen Sie das Fenster.
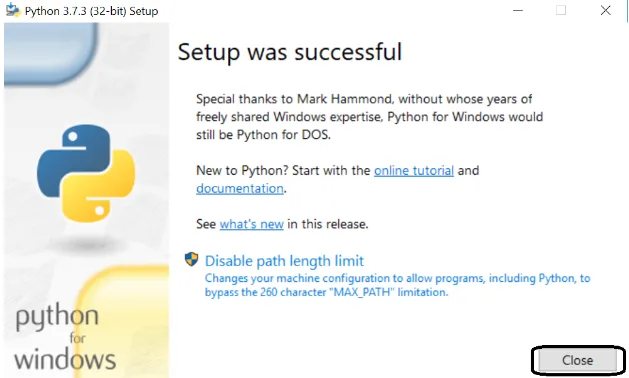
Schritt 7: Kopieren Sie den Pfad des Scripts-Ordners, um NLTK im selben Ordner zu installieren.
NLTK kann einfach mit einem Pip-Installer installiert werden. Außerdem müssen wir auch "numpy" installieren.
Schritt 8: Um NLTK zu installieren, öffnen Sie die Eingabeaufforderung und geben Sie den folgenden Befehl ein.

Stellen Sie sicher, dass die Installation erfolgreich ist.
Nach erfolgreicher Installation ist es nun an der Zeit, das NLTK für die Verarbeitung natürlicher Sprachen zu verwenden.
Schritt 9: Öffnen Sie die Python-Shell und geben Sie den folgenden Befehl ein.


Wenn es fehlerfrei importiert wird, bedeutet dies, dass NLTK ordnungsgemäß installiert ist.
Installieren Sie NLTK für Mac / Linux
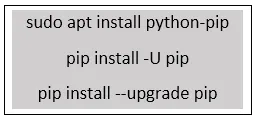
Anders als unter Windows wird auf Linux-Systemen Python installiert. Um NLTK unter Linux / Mac zu installieren, wird das Python-Installationsprogramm für Pip-Pakete verwendet. Um pip zu installieren oder zu aktualisieren, geben Sie die folgenden Befehle in die Eingabeaufforderung ein.
Verwenden Sie die folgenden Befehle, um Python unter Linux zu installieren.
Schritt 1: Verwenden Sie den folgenden Befehl, um den Paketindex zu aktualisieren.

Schritt 2: Um Python unter Linux zu installieren, gehen Sie wie folgt vor .

Schritt 3: Geben Sie den folgenden Befehl ein, um "pip" für Python 3 zu installieren.
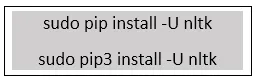
Schritt 4: Nachdem "Pip" erfolgreich installiert wurde, verwenden Sie die folgenden Befehle, um NLTK zu installieren.
NLTK-Datensatz
NLTK verfügt über viele Datensätze für die Verarbeitung natürlicher Sprache, z. B. WordNet, WikiCorpus, Gutenberg, Meinungslexikon, Tweebank usw. Diese Datensätze werden als Korpora bezeichnet. Grundsätzlich enthält der NLTK-Datensatz eine Reihe von Dateien oder Dokumenten. Jede Datei / jedes Dokument enthält eine Sammlung von Wörtern, Buchstaben oder Text in einer einzigen Sprache. Ein Korpus besteht also hauptsächlich aus Bibliotheken zum Verstehen / Lernen einer Sprache. Es hat Regeln der Grammatik und Struktur einer Sprache.
Nachdem Sie NLTK erfolgreich installiert haben, können Sie es importieren und seine Korpora mit dem folgenden Befehl herunterladen.

Der NLTK-Downloader öffnet ein Fenster zum Herunterladen der Datensätze. Die Größe des Datensatzes ist groß, daher wird es einige Zeit dauern. Um zu testen, ob Datasets ordnungsgemäß installiert sind, importieren Sie das Dataset und verwenden Sie es.

Verarbeitung von NLTK
Es gibt 5 Hauptprozesse der Verarbeitung natürlicher Sprache. Dies sind die Schritte, die bei der Verarbeitung von Text erforderlich sind.
- EOS-Erkennung : Die Sprachendeerkennung unterteilt den Text in eine Sammlung aussagekräftiger Sätze. Es unterteilt den Langtext in Teile, die eine Bedeutung haben.
- Tokenisierung : Dieser Schritt teilt die Sätze in Token auf. Token enthalten nicht nur Wörter, sondern auch Leerzeichen und Satzumbrüche.
- POS-Tagging : POS steht für Pat-of-Speech. Hier werden dem Token Informationen zugeordnet. Diese Informationen legen nahe, welche Art von Sprache als Zeitform, Verb, Adjektiv, Substantiv usw. bezeichnet wird.
- Chunking : Unter Chunking versteht man das Sammeln von Text anhand von Tags.
- Extraktion: Die Extraktion ist ein fortlaufender Prozess, bei dem Blöcke durchlaufen und als benannte Entitäten wie Personen, Standorte, Organisationen usw. gekennzeichnet werden.
Fazit:
NLTK wird für die Klassifizierung von Text, Bildunterschriften, Spracherkennung, Beantwortung von Fragen, Sprachmodellierung, Dokumentenzusammenfassung und viele andere Vorgänge verwendet. Es gibt viele andere Tools für die Verarbeitung natürlicher Sprache. NLTK verfügt jedoch über eine breite Palette von Bibliotheken, die es zu einem der leistungsstärksten Tools für die Verarbeitung natürlicher Sprachen macht. Es ist genauer als jedes andere Tool, aber aufgrund der großen Anzahl von Bibliotheken etwas langsam. Es hängt also alles von den Anforderungen des Benutzers ab. Wenn der Benutzer Geschwindigkeit wünscht, kann er auch andere Tools bevorzugen, muss jedoch Kompromisse bei der Genauigkeit des Inhalts eingehen. Aber wenn Genauigkeit Priorität hat, sollten sie sich definitiv für NLTK entscheiden.
Empfohlene Artikel:
Dies war eine Anleitung zur Installation von NLTK. Hier diskutieren wir das Grundkonzept und die verschiedenen Schritte zur Installation von NLTK unter Windows und Linux \ Mac. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren.
- Installieren Sie Kubernetes Dashboard
- So installieren Sie JDK
- Installieren Sie Docker
- Wie installiere ich Magento?
- Magento Versionen | Funktionen von Magento-Versionen