
Übersicht über AWS RedShift
AWS bietet viele Funktionen, die uns die Arbeit erleichtern. In diesem Thema erfahren Sie mehr über Was ist AWS Redshift und einige der folgenden Technologien von AWS Redshift:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
Einer der wichtigsten von AWS bereitgestellten Dienste, mit dem wir uns befassen werden, ist Amazon RedShift. Also, was ist diese RedShift, wofür wird sie verwendet? Dies sind die grundlegenden Fragen, die uns in den Sinn kommen, wenn wir dies lesen. Lassen Sie uns im Detail prüfen, was Rotverschiebung ist und wofür sie verwendet wird. RedShift ist ein vollständig verwalteter Data Warehousing-Service für Unternehmen im Petabyte-Bereich.
Was ist ein Data Warehouse? Die Antwort für sich selbst liegt darin, wenn wir wissen, was ein Lager allgemein ist. Im Allgemeinen ist ein Lager ein Ort, an dem Rohstoffe oder hergestellte Waren vor ihrer Verteilung zum Verkauf gelagert werden können. Dasselbe gilt für Data. Auch Data Warehouse ist ein Ort zum Sammeln, Speichern und Verwalten von Daten aus verschiedenen Quellen und Bereitstellen der relevanten und aussagekräftigen Geschäftserkenntnisse. Daher bietet Amazon ein Warehousing-Tool für Unternehmen, mit dem wir Daten mit REDSHIFT verarbeiten und verwalten können. Der Bereich für diese Datasets variiert von 100 Gigabyte bis Petabyte.
Gründe für die Verwendung von AWS RedShift
Daher stoßen wir häufig auf die allgemeine Frage, wo vor diesem AWS-Tool dieses Lager war, wo wir all diese Daten verarbeitet, gespeichert und hergestellt haben. Früher, als das Laden von Daten ganz normal war, hatten wir physische Server, Datenbanken, die die Daten und deren Verarbeitung verfolgten, aber da die Datenmenge exponentiell zunahm, wurde das Abfragen und Verarbeiten von Daten zu einer schwierigen Aufgabe Abfragen begannen wie erwartet lange zu dauern.
Hier stießen wir auf das Bedürfnis nach Amazon Redshift, das bei sehr hoher Leistung und Skalierbarkeit für die Speicherung und Herstellung von Daten viel schneller war. Es war mit einer enormen Speicherkapazität und einer transparenten Preisgestaltung ausgestattet und vor verschiedenen Datenverletzungen geschützt. Durch die Unterstützung von SQL-Schnittstellen und verschiedenen Treibern für ODBC / JDBC ist es recht einfach zu bedienen und gut mit anderen Amazon-Diensten zu kombinieren.
Funktionsweise von AWS RedShift
Sehen wir uns nun das Architekturdiagramm von Redshift an und versuchen zu verstehen, wie RedShift tatsächlich funktioniert.
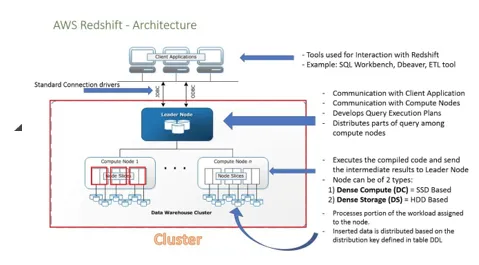
- Das folgende Diagramm zeigt die Funktionsweise von Amazon RedShift. Lassen Sie uns das im Detail überprüfen:
- Für die Verbindung mit der Client-Anwendung verfügen wir über mehrere Treiber, die eine Verbindung mit Redshift herstellen.
- In Redshift können wir mehr als einen Cluster erstellen und jeder Cluster kann mehrere Datenbanken hosten.
- Die Knoten sind in Slices unterteilt, wobei jedes Slice Daten enthält.
- Wenn aus den verfügbaren Knoten mehr als ein Knoten als Leader ausgewählt ist, ist dies die Hauptquelle für die Kommunikation des Clients. Die Client-Anwendung kommuniziert nur mit dem Leitknoten. Der Leitknoten ist für den Empfang von Abfragen und Befehlen vom Client-Programm verantwortlich.
- Sobald der Führungsknoten die vom Client ausgeführten Abfragen abruft, analysiert er die Abfrage und erstellt einen Plan, damit sie auf anderen Rechenknoten ausgeführt wird. Sobald der Prozess an die betreffenden Knoten verteilt wurde, wartet er auf das endgültige Ergebnis der Knoten, bevor er an den Client zurückgegeben wird.
- Wir können die Anzahl der Knoten hinzufügen und auch den Speicher erhöhen, wenn die Datenlast zunimmt.
- Die Rechenknoten verfügen über ein separates Netzwerk, auf das der Client keinen Zugriff hat, wodurch sie ebenfalls sicher sind.
- Es gibt zwei Arten von Knoten: Dichte Speicherknoten und Dichte Rechenknoten. Die Speicherkapazität kann zwischen 160 GB und 16 TB liegen
Hier haben wir die grundlegende Architektur der Funktionsweise von REDSHIFT gesehen. Fahren wir nun mit der Verwendung von Aws Redshift fort.
Verwenden von AWS RedShift -
Für die Arbeit mit AWS Redshift müssen wir einige grundlegende Schritte ausführen, die unten aufgeführt sind:
1) Melden Sie sich bei AWS an und erstellen Sie dort ein Konto. (Wenn nicht)
2) Gehen Sie über den folgenden Link zur Amazon Redshift-Konsole: -
https://console.aws.amazon.com/redshift/
3) Jetzt müssen wir eine I AM-Rolle erstellen, um zum folgenden Link zu navigieren:
https://console.aws.amazon.com/iam/
- Gehen Sie zu Rollen
- Wählen Sie, um Rollen zu erstellen.
- Wählen Sie im AWS-Service die Option Rotverschiebung
- Wählen Sie Rotverschiebung - Anpassbar und dann Weiter: Berechtigungen unter Wählen Sie Ihren Anwendungsfall.
- Berechtigungsgrenze festlegen
- Geben Sie einen Namen für Ihre Rolle ein
- Überprüfen und erstellen Sie die Rolle.
4) Nun müssen wir einen Cluster erstellen, indem wir dort in der Konsole ein Regionsmenü auswählen.
- Wählen Sie die Region aus, in der der Cluster erstellt wird.
- Klicken Sie auf Starten.
- Wir müssen einige Details wie den Datenbanknamen und das Passwort eingeben und die Weiter-Schaltfläche aktivieren
- Sobald der Cluster sichtbar ist, überprüfen Sie dies in der Liste und überprüfen Sie die Statusinformationen.
- Sobald wir den Cluster bei uns haben, müssen wir als Nächstes die Sicherheitsgruppe festlegen. Hier müssen wir die Protokollquelle und den Bereich für den Inbounds-Regeltyp festlegen.
- Überprüfen Sie die erforderliche Konfiguration und stellen Sie eine Verbindung zu Redshift Cluster her.
5) Sobald wir mit allen Cluster-bezogenen Konfigurationen fertig sind, müssen wir uns jetzt mit unserem Redshift verbinden. Wir können uns direkt oder über SSL mit diesem Redshift verbinden. Um es direkt zu verbinden, benötigen wir JDBC / ODBC-Treiber, die wir über die Konfigurationsseite des Clusters einstellen müssen.
Sobald diese verschiedenen Konfigurationen gut gemacht sind, können wir Redshift verwenden.
Vorteile von AWS RedShift -
Warum also wird jemand AWS Redshift verwenden, muss es einen Vorteil gegenüber anderen Diensten geben, die dies zu etwas Besonderem machen. Lassen Sie uns nun einige der Vorteile der Verwendung von Redshift prüfen.
- Hohe Geschwindigkeit : - Die Verarbeitungszeit für die Abfrage ist vergleichsweise schneller als bei den anderen Datenverarbeitungstools, und die Datenvisualisierung hat ein klares Bild.
- Massendatenverarbeitung : - Je größer die Datenmenge, desto schneller kann Redshift große Datenmengen verarbeiten.
- Minimaler Datenverlust : - Da Daten über den Cluster verteilt und parallel über das Netzwerk verarbeitet werden, besteht eine minimale Wahrscheinlichkeit für Datenverlust, und die Genauigkeitsrate für die verarbeiteten Daten ist besser.
- Kostengünstig : - Kostengünstig ist es billiger als alle anderen verfügbaren Alternativen, die es im Vergleich zur Industrie stark machen. Da die Preise niedriger sind, können wir über große Datenmengen verfügen und diese innerhalb des Budgets verarbeiten.
- SQL-Schnittstelle : - Die auf Redshift basierende Abfrage-Engine ist mit der von Postgres SQL identisch, sodass SQL-Entwickler leichter damit spielen können.
- Sicherheit : - Die Daten in RedShift sind verschlüsselt und an mehreren Stellen in RedShift verfügbar. Außerdem können wir die eingehende und ausgehende Regel definieren, die die Daten viel sicherer macht.
Rotverschiebung als bessere Wahl für das Data Warehouse bietet weitaus mehr Vorteile.
AWS RedShift-Preise -
RedShift wird mit einer erstaunlichen Preisliste geliefert, die Entwickler oder den Markt anzieht. Da es mit einer On-Demand-Preisfunktion ausgestattet ist, können wir es auf einer Basis von etwas mehr als einer Stunde und mit einer Anzahl von Knoten in unserem Cluster verwenden. Spectrum Pricing hilft uns dabei, SQL-Abfragen direkt für alle unsere Daten auszuführen.
Wir können große Data Warehouses mit HDD zu einem sehr niedrigen Preis erstellen. Weitere Informationen zu den genauen Preisangaben finden Sie in der Dokumentation von Amazon: -
https://aws.amazon.com/redshift/pricing/
Das obige Dokument enthält alle Details zu den verschiedenen Preisen für AWS REDSHIFT.
Fazit
Aus dem obigen Artikel, den wir für Redshift gesehen haben, müssen wir nun eine genaue Vorstellung davon haben, was eigentlich Redshift ist und wie es verwendet wird. RedShift ist so skalierbar und benutzerfreundlich, dass es von der Industrie aufgrund der Unterstützung verschiedener anderer Technologien von Amazon, die es leistungsfähiger machen, am häufigsten eingesetzt wird. In einer Welt voller Daten wird Redshift mit einem sehr guten Paket an Data Warehousing und Verarbeitung ausgeliefert.
Empfohlene Artikel
Dies ist eine Anleitung zu AWS RedShift. Hier diskutieren wir die Arbeitsweise, Verwendung und Vorteile von AWS RedShift. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- AWS-Architektur
- Was ist AWS?
- Was ist Azure?
- Was ist AWS Lambda?
- AWS Storage Services