
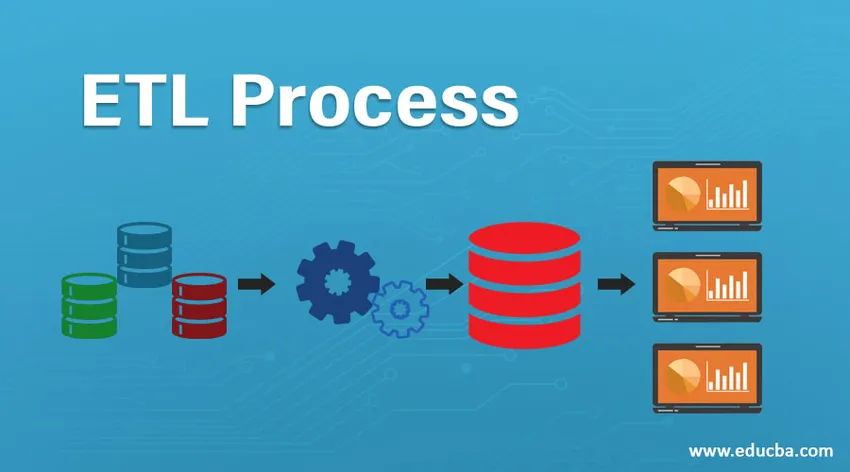
Einführung des ETL-Prozesses
ETL ist einer der wichtigsten Prozesse, die von Business Intelligence benötigt werden. Business Intelligence stützt sich auf die in Data Warehouses gespeicherten Daten, aus denen viele Analysen und Berichte generiert werden. Dies trägt zur Entwicklung effektiverer Strategien bei und führt zu taktischen und operativen Einsichten und Entscheidungen.
ETL bezieht sich auf den Prozess Extrahieren, Transformieren und Laden. Es ist eine Art Datenintegrationsschritt, bei dem Daten aus verschiedenen Quellen extrahiert und an Data Warehouses gesendet werden. Daten, die aus verschiedenen Ressourcen extrahiert werden, werden zunächst transformiert, um sie gemäß den Geschäftsanforderungen in ein bestimmtes Format zu konvertieren. Verschiedene Tools, mit denen Sie diese Aufgaben ausführen können, sind:
- IBM DataStage
- Abinitio
- Informatica
- Tableau
- Talend
ETL-Prozess
Wie funktioniert es?
Der ETL-Prozess besteht aus 3 Schritten und beginnt mit dem Extrahieren der Daten aus verschiedenen Datenquellen. Anschließend werden die Rohdaten verschiedenen Transformationen unterzogen, um sie für die Speicherung im Data Warehouse geeignet zu machen und in Data Warehouses im erforderlichen Format zu laden und für die Speicherung vorzubereiten Analyse.
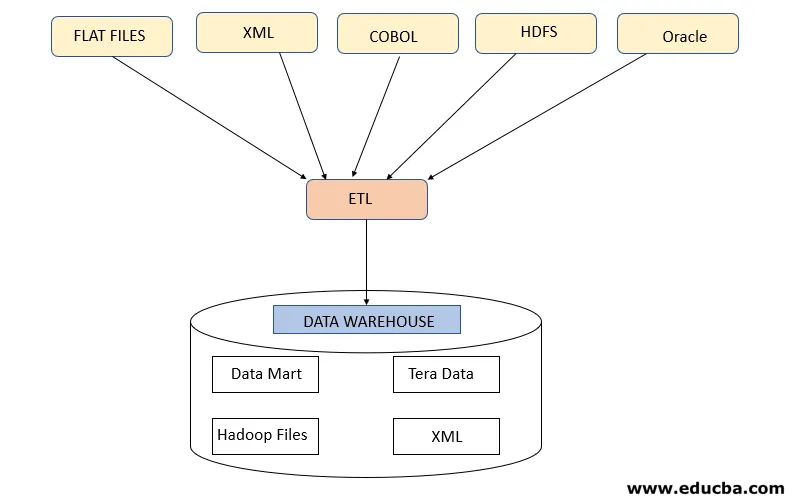
Schritt 1: Extrahieren
Dieser Schritt bezieht sich auf das Abrufen der erforderlichen Daten aus verschiedenen Quellen, die in verschiedenen Formaten wie XML, Hadoop-Dateien, Flat Files, JSON usw. vorliegen. Die extrahierten Daten werden im Staging-Bereich gespeichert, in dem weitere Transformationen durchgeführt werden. Daher werden Daten gründlich geprüft, bevor sie in Data Warehouses verschoben werden. Andernfalls wird es zu einer Herausforderung, die Änderungen in Data Warehouses rückgängig zu machen.
Vor der Datenextraktion ist eine ordnungsgemäße Datenzuordnung zwischen Quelle und Ziel erforderlich, da der ETL-Prozess mit verschiedenen Systemen wie Oracle, Hardware, Mainframe und Echtzeitsystemen wie ATM, Hadoop usw. interagieren muss, während Daten von diesen Systemen abgerufen werden .
Hinweis - Es ist jedoch darauf zu achten, dass diese Systeme während der Extraktion nicht beeinträchtigt werden.
Datenextraktionsstrategien
- Vollständige Extraktion: Dies erfolgt, wenn vollständige Daten aus Quellen in die Data Warehouses geladen werden, die anzeigen, dass entweder das Data Warehouse zum ersten Mal gefüllt wird oder keine Strategie für die Datenextraktion festgelegt wurde.
- Teilextraktion (mit Update-Benachrichtigung): Diese Strategie ist auch als Delta bekannt, bei dem nur die zu ändernden Daten extrahiert und Data Warehouses aktualisiert werden
- Teilextraktion (ohne Update-Benachrichtigung): Diese Strategie bezieht sich auf das Extrahieren bestimmter erforderlicher Daten aus Quellen gemäß der Auslastung in den Data Warehouses, anstatt vollständige Daten zu extrahieren.
Schritt 2: Transformieren
Dieser Schritt ist der wichtigste Schritt von ETL. In diesem Schritt werden viele Transformationen ausgeführt, um Daten in Data Warehouses für das Laden vorzubereiten, indem die folgenden Transformationen angewendet werden:
A. Grundlegende Transformationen: Diese Transformationen werden in jedem Szenario angewendet, da sie für das Laden der aus verschiedenen Quellen extrahierten Daten in die Data Warehouses von grundlegender Bedeutung sind
- Datenbereinigung oder -anreicherung: Dies bezieht sich auf die Bereinigung der unerwünschten Daten aus dem Staging-Bereich, damit keine falschen Daten aus den Data Warehouses geladen werden.
- Filtern: Hier filtern wir die erforderlichen Daten aus einer großen Datenmenge heraus, die entsprechend den Geschäftsanforderungen vorhanden ist. Für die Erstellung von Verkaufsberichten werden beispielsweise nur Verkaufsunterlagen für dieses bestimmte Jahr benötigt.
- Konsolidierung: Die extrahierten Daten werden im erforderlichen Format konsolidiert, bevor sie in die Data Warehouses geladen werden.
- Standardisierungen: Datenfelder werden transformiert, um dasselbe erforderliche Format zu erhalten, z. B. muss das Datenfeld als MM / TT / JJJJ angegeben werden.
B. Erweiterte Transformationen: Diese Arten von Transformationen sind spezifisch für die Geschäftsanforderungen.
- Verbinden: Bei dieser Operation werden Daten aus zwei oder mehr Quellen kombiniert, um Daten mit nur gewünschten Spalten mit Zeilen zu generieren, die miteinander in Beziehung stehen
- Überprüfung der Datenschwellenwertvalidierung: In verschiedenen Feldern vorhandene Werte werden überprüft, ob sie korrekt sind oder nicht, z. B. bei Bankdaten die Kontonummer nicht Null.
- Verwenden Sie Lookups, um Daten zusammenzuführen: Verschiedene Flatfiles oder andere Dateien werden verwendet, um die spezifischen Informationen zu extrahieren, indem eine Lookup-Operation für diese durchgeführt wird.
- Verwenden komplexer Datenüberprüfungen: Viele komplexe Überprüfungen werden angewendet, um gültige Daten nur aus den Quellsystemen zu extrahieren.
- Berechnete und abgeleitete Werte: Verschiedene Berechnungen werden angewendet, um die Daten in einige erforderliche Informationen umzuwandeln
- Duplikation: Doppelte Daten aus den Quellsystemen werden analysiert und entfernt, bevor sie in die Data Warehouses geladen werden.
- Schlüsselumstrukturierung: Bei der Erfassung sich langsam ändernder Daten müssen verschiedene Ersatzschlüssel generiert werden, um die Daten im erforderlichen Format zu strukturieren.
Hinweis - MPP-Massive Parallel Processing wird manchmal verwendet, um einige grundlegende Vorgänge auszuführen, z. B. Filtern oder Bereinigen von Daten im Staging-Bereich, um eine große Datenmenge schneller zu verarbeiten.
Schritt 3: Laden
Dieser Schritt bezieht sich auf das Laden der transformierten Daten in das Data Warehouse, von wo aus viele Analyseentscheidungen sowie Berichte generiert werden können.
1. Initial Load: Diese Art des Ladens erfolgt beim erstmaligen Laden von Daten in Data Warehouses.
2. Inkrementelle Auslastung : Dies ist die Art der Auslastung, die durchgeführt wird, um das Data Warehouse regelmäßig zu aktualisieren, wenn Änderungen an den Quellsystemdaten auftreten.
3. Vollständige Aktualisierung: Diese Art des Ladens bezieht sich auf den Fall, dass vollständige Daten der Tabelle gelöscht und mit neuen Daten geladen werden.
Das Data Warehouse lässt dann OLAP- oder OLTP-Funktionen zu.
Nachteile des ETL-Prozesses
- Zunehmende Daten - Es gibt eine Begrenzung der Daten, die vom ETL-Tool aus verschiedenen Quellen extrahiert und in Data Warehouses übertragen werden. Die Arbeit mit dem ETL-Tool und den Data Warehouses wird daher mit zunehmender Datenmenge umständlich.
- Anpassung - Dies bezieht sich auf die schnellen und effektiven Lösungen oder Reaktionen auf die von Quellsystemen generierten Daten. Die Verwendung des ETL-Tools verlangsamt diesen Prozess.
- Teuer - Die Verwendung eines Data Warehouse zum Speichern einer zunehmenden Menge von Daten, die regelmäßig generiert werden, ist ein hoher Kostenaufwand für ein Unternehmen.
Fazit - ETL-Prozess
Das ETL-Tool umfasst Extraktions-, Transformations- und Ladeprozesse, mit denen Informationen aus den Daten generiert werden können, die aus verschiedenen Quellsystemen gesammelt wurden. Die Daten aus dem Quellsystem können in beliebigen Formaten vorliegen und in beliebigen Formaten in Data Warehouses geladen werden. Daher muss das ETL-Tool die Konnektivität zu allen Arten dieser Formate unterstützen.
Empfohlene Artikel
Dies ist eine Anleitung zu einem ETL-Prozess. Hier diskutieren wir die Einführung, Wie funktioniert es ?, ETL-Tools und ihre Nachteile. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren.
- Informatica ETL-Tools
- ETL-Testwerkzeuge
- Was ist ETL?
- Was ist ETL-Testen?