
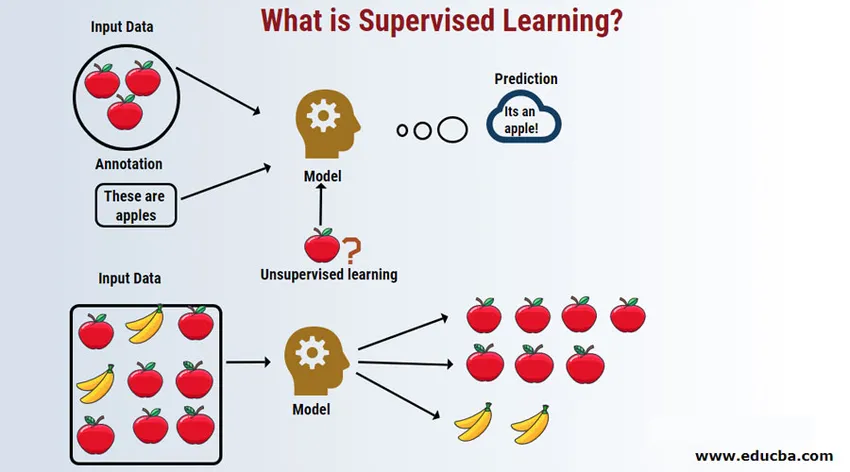
Einführung in betreutes Lernen
Überwachtes Lernen ist ein Bereich des maschinellen Lernens, in dem wir daran arbeiten, die Werte anhand von beschrifteten Datensätzen vorherzusagen. Die beschrifteten Eingabedatensätze werden als unabhängige Variable bezeichnet, während die vorhergesagten Ergebnisse als abhängige Variable bezeichnet werden, da ihre Ergebnisse von der unabhängigen Variablen abhängen. Zum Beispiel haben wir alle einen Spam-Ordner in unserem E-Mail-Konto (z. B. Google Mail), der die meisten Spam- / Betrugs-E-Mails automatisch mit einer Genauigkeit von mehr als 95% erkennt. Es basiert auf einem überwachten Lernmodell, bei dem wir einen Schulungssatz mit gekennzeichneten Daten haben, in diesem Fall mit gekennzeichneten Spam-E-Mails, die von Benutzern gekennzeichnet wurden. Diese Schulungssets werden zum Lernen verwendet, die später zur Kategorisierung neuer E-Mails als Spam verwendet werden, wenn sie zur Kategorie passen.
Arbeiten am überwachten maschinellen Lernen
Lassen Sie uns das überwachte maschinelle Lernen anhand eines Beispiels verstehen. Nehmen wir an, wir haben einen Obstkorb, der mit verschiedenen Obstsorten gefüllt ist. Unsere Aufgabe ist es, Früchte anhand ihrer Kategorie zu kategorisieren.
In unserem Fall haben wir vier Arten von Früchten betrachtet, nämlich Apfel, Banane, Trauben und Orangen.
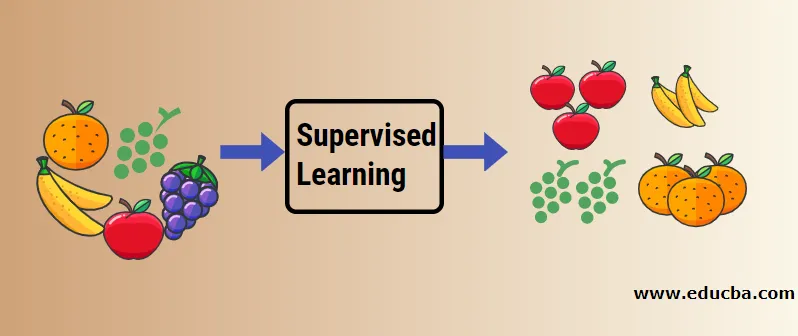
Jetzt werden wir versuchen, einige der einzigartigen Eigenschaften dieser Früchte zu erwähnen, die sie einzigartig machen.
|
S Nr. | Größe | Farbe | Gestalten |
Vorname |
|
1 | Klein | Grün | Rund bis oval, Bündelform Zylindrisch |
Traube |
|
2 | Groß | rot | Abgerundete Form mit einer Vertiefung oben |
Apfel |
|
3 | Groß | Gelb | Langer geschwungener Zylinder |
Banane |
| 4 | Groß | Orange | Abgerundete Form |
Orange |
Nehmen wir nun an, Sie haben eine Frucht aus dem Obstkorb genommen, ihre Merkmale untersucht, z. B. Form, Größe und Farbe, und dann festgestellt, dass die Farbe dieser Frucht rot ist, die Größe, wenn sie groß ist, die Form ist abgerundet mit Vertiefung an der Spitze, daher ist es ein Apfel.
- Ebenso machen Sie dasselbe für alle anderen verbleibenden Früchte.
- Die Spalte ganz rechts („Fruchtname“) wird als Antwortvariable bezeichnet.
- Auf diese Weise formulieren wir ein überwachtes Lernmodell. Jetzt ist es für jeden, der über bestimmte Eigenschaften verfügt (z. B. einen Roboter oder einen Außerirdischen), ganz einfach, dieselbe Obstsorte zu einer Gruppe zusammenzufassen.
Arten von überwachten maschinellen Lernalgorithmen
Sehen wir uns verschiedene Arten von Algorithmen für maschinelles Lernen an:
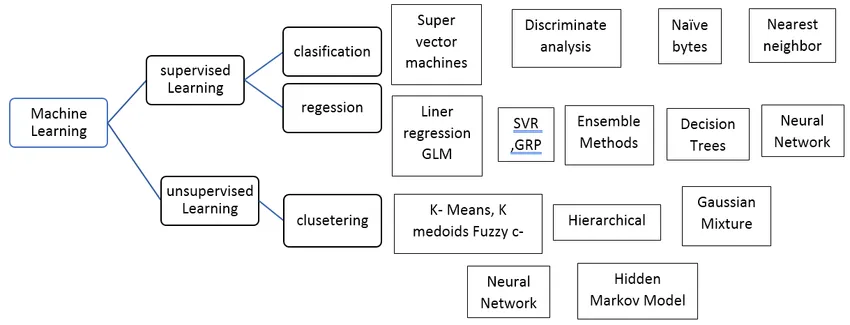
Regression:
Die Regression wird verwendet, um die Einzelwertausgabe unter Verwendung des Trainingsdatensatzes vorherzusagen. Der Ausgabewert wird immer als abhängige Variable bezeichnet, während die Eingaben als unabhängige Variable bezeichnet werden. Wir haben verschiedene Arten der Regression im überwachten Lernen, zum Beispiel
- Lineare Regression - Hier haben wir nur eine unabhängige Variable, die zur Vorhersage der Ausgabe verwendet wird, dh abhängige Variable.
- Multiple Regression - Hier haben wir mehr als eine unabhängige Variable, die zur Vorhersage der Ausgabe verwendet wird, dh die abhängige Variable.
- Polynom-Regression - Hier folgt der Graph zwischen der abhängigen und der unabhängigen Variablen einer Polynomfunktion. Zum Beispiel nimmt das Gedächtnis zunächst mit dem Alter zu, erreicht dann in einem bestimmten Alter eine Schwelle und beginnt mit zunehmendem Alter abzunehmen.
Einstufung:
Die Klassifizierung von überwachten Lernalgorithmen wird verwendet, um ähnliche Objekte in eindeutige Klassen zu gruppieren.
- Binäre Klassifizierung - Wenn der Algorithmus versucht, zwei verschiedene Klassengruppen zu gruppieren, wird dies als binäre Klassifizierung bezeichnet.
- Klassifizierung mehrerer Klassen - Wenn der Algorithmus versucht, Objekte in mehr als 2 Gruppen zu gruppieren, wird dies als Klassifizierung mehrerer Klassen bezeichnet.
- Stärke - Klassifizierungsalgorithmen funktionieren normalerweise sehr gut.
- Nachteile - Neigt zur Überanpassung und ist möglicherweise nicht eingeschränkt. Zum Beispiel - Email Spam Classifier
- Logistische Regression / Klassifikation - Wenn die Y-Variable eine binäre kategoriale (dh 0 oder 1) ist, verwenden wir die logistische Regression für die Vorhersage. Zum Beispiel - Vorhersage, ob eine bestimmte Kreditkartentransaktion ein Betrug ist oder nicht.
- Naive Bayes-Klassifikatoren - Der Naive Bayes-Klassifikator basiert auf dem Bayes'schen Theorem. Dieser Algorithmus ist normalerweise am besten geeignet, wenn die Dimensionalität der Eingaben hoch ist. Es besteht aus azyklischen Diagrammen mit einem übergeordneten und mehreren untergeordneten Knoten. Die untergeordneten Knoten sind voneinander unabhängig.
- Entscheidungsbäume - Ein Entscheidungsbaum ist eine baumdiagrammartige Struktur, die aus einem internen Knoten (Test auf Attribut), einem Zweig, der das Ergebnis des Tests angibt, und den Blattknoten besteht, die die Verteilung der Klassen darstellen. Der Wurzelknoten ist der oberste Knoten. Es ist eine sehr weit verbreitete Technik, die zur Klassifizierung verwendet wird.
- Support Vector Machine - Eine Support Vector Machine ist oder eine SVM erledigt die Klassifizierung, indem sie die Hyperebene findet, die den Spielraum zwischen zwei Klassen maximieren soll. Diese SVM-Maschinen sind mit den Kernelfunktionen verbunden. Bereiche, in denen SVMs häufig verwendet werden, sind Biometrie, Mustererkennung usw.
Vorteile
Nachfolgend sind einige der Vorteile von Modellen für überwachtes maschinelles Lernen aufgeführt:
- Die Leistung von Modellen kann durch die Benutzererfahrungen optimiert werden.
- Überwachtes Lernen führt zu Ergebnissen, die auf früheren Erfahrungen basieren, und ermöglicht es Ihnen, Daten zu sammeln.
- Überwachte Algorithmen für maschinelles Lernen können zum Implementieren einer Reihe von Problemen aus der Praxis verwendet werden.
Nachteile
Die Nachteile des überwachten Lernens sind folgende:
- Wenn der Datensatz größer ist, kann der Schulungsaufwand für überwachte Modelle des maschinellen Lernens viel Zeit in Anspruch nehmen.
- Die Klassifizierung von Big Data ist manchmal eine größere Herausforderung.
- Man muss sich möglicherweise mit den Problemen der Überanpassung auseinandersetzen.
- Wir brauchen viele gute Beispiele, wenn wir wollen, dass das Modell eine gute Leistung erbringt, während wir den Klassifikator trainieren.
Gute Praktiken beim Aufbau von Lernmodellen
Es wird empfohlen, beim Erstellen eines Modells für überwachte Lernmaschinen Folgendes zu beachten:
- Bevor ein gutes Modell für maschinelles Lernen erstellt werden kann, muss der Prozess der Datenvorverarbeitung durchgeführt werden.
- Man muss den Algorithmus bestimmen, der für ein gegebenes Problem am besten geeignet ist.
- Wir müssen entscheiden, welche Art von Daten für den Trainingssatz verwendet werden.
- Muss über die Struktur des Algorithmus und der Funktion entscheiden.
Fazit
In unserem Artikel haben wir gelernt, was überwachtes Lernen ist, und wir haben gesehen, dass wir hier das Modell unter Verwendung von beschrifteten Daten trainieren. Dann beschäftigten wir uns mit den Modellen und ihren verschiedenen Typen. Wir haben endlich die Vor- und Nachteile dieser überwachten Algorithmen für maschinelles Lernen gesehen.
Empfohlene Artikel
Dies ist ein Leitfaden zu dem, was betreutes Lernen ist. Hier diskutieren wir die Konzepte, wie es funktioniert, Typen, Vor- und Nachteile von Supervised Learning. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Was ist tiefes Lernen?
- Betreutes Lernen gegen tiefes Lernen
- Was ist Synchronisation in Java?
- Was ist Webhosting?
- Möglichkeiten zur Erstellung eines Entscheidungsbaums mit Vorteilen
- Polynom-Regression | Gebrauch und Eigenschaften