
Was ist ein Bienenstock?
Bevor wir die Hive-Datentypen verstehen, werden wir zunächst den Hive untersuchen. Hive ist eine Data Warehousing-Technik von Hadoop. Hadoop ist das Segment für die Speicherung und Verarbeitung von Daten auf der Big Data-Plattform. Hive behauptet seine Position im Bereich der Datenverarbeitung. Wie in anderen Sequel-Umgebungen kann Hive über Sequel-Abfragen erreicht werden. Die wichtigsten Angebote von hive sind Datenanalyse, Ad-hoc-Abfrage und Zusammenfassung der gespeicherten Daten aus Sicht der Latenz, wobei die Abfragen eine größere Menge umfassen.
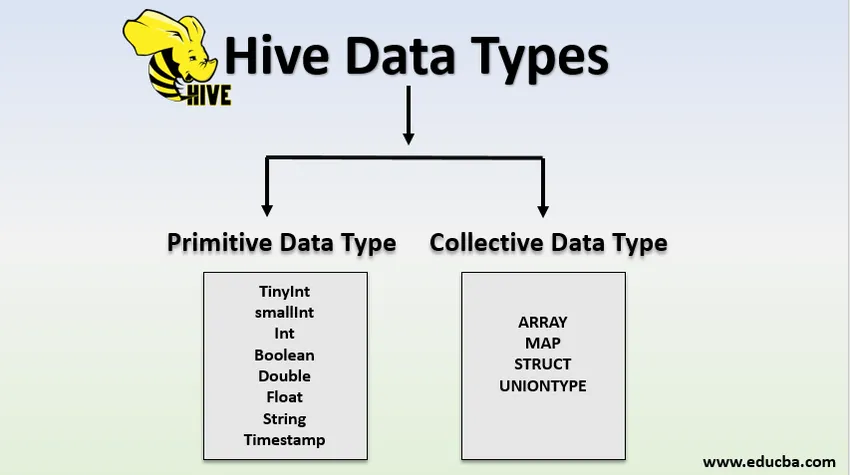
Hive-Datentypen
Datentypen werden in zwei Typen eingeteilt:
- Primitive Datentypen
- Sammeldatentypen
1. Primitive Datentypen
Ursprüngliche Mittel waren uralt und alt. Alle als primitiv aufgeführten Datentypen sind Legacy-Datentypen. Die folgenden wichtigen Bereiche für primitive Datentypen:
| Art | Größe (Byte) | Beispiel |
| TinyInt | 1 | 20 |
| SmallInt | 2 | 20 |
| Int | 4 | 20 |
| Bigint | 8 | 20 |
| Boolean | Boolean wahr / falsch | FALSCH |
| Doppelt | 8 | 10.2222 |
| Schweben | 4 | 10.2222 |
| String | Zeichenfolge | A B C D |
| Zeitstempel | Ganzzahl / Float / String | 03.02.2012 12: 34: 56: 1234567 |
| Datum | Ganzzahl / Float / String | 2/3/2019 |
Hive-Datentypen werden mit JAVA implementiert
Beispiel: Java Int wird hier zur Implementierung des Int-Datentyps verwendet.
- Zeichenarrays werden in HIVE nicht unterstützt.
- Hive verwendet Trennzeichen, um seine Felder zu trennen. Die Koordination mit Hadoop ermöglicht die Steigerung der Schreib- und Leseleistung.
- Die Angabe der Länge jeder Spalte wird in der Strukturdatenbank nicht erwartet.
- String-Literale können in doppelte Anführungszeichen (“) oder einfache Anführungszeichen (') gesetzt werden.
- In einer neueren Version des Hives werden Varchar-Typen eingeführt, die einen Bereichsspezifizierer von (zwischen 1 und 65535) bilden. Für eine Zeichenfolge ist dies also die größte Wertelänge, die sie aufnehmen kann. Wenn ein Wert eingefügt wird, der diese Länge überschreitet, werden die Elemente ganz rechts dieses Werts abgeschnitten. Die Zeichenlänge ist die Auflösung, wobei die Anzahl der Codepunkte von der Zeichenfolge gesteuert wird.
- Alle ganzzahligen Literale (TINYINT, SMALLINT, BIGINT) werden grundsätzlich als INT-Datentypen betrachtet, und nur die Länge überschreitet die tatsächliche int-Ebene, die in ein BIGINT oder einen anderen entsprechenden Typ umgewandelt wird.
- Dezimalliterale bieten im Vergleich zum Typ DOUBLE definierte Werte und eine überlegene Sammlung von Gleitkommawerten. Hier werden numerische Werte in ihrer genauen Form gespeichert, aber im Fall von double werden sie nicht genau als numerische Werte gespeichert.
Datumswert Casting-Prozess
| Casting durchgeführt | Ergebnis |
| Besetzung (Datum als Datum) | Gleicher Datumswert |
| Besetzung (Zeitstempel als Datum) | Eine lokale Zeitzone wird verwendet, um die Werte für Jahr / Monat / Datum auszuwerten und in der Ausgabe auszudrucken. |
| Besetzung (Zeichenfolge als Datum) | Als Ergebnis dieses Castings wird ein entsprechender Datumswert abgefragt, aber wir müssen sicherstellen, dass die Zeichenfolge das Format 'JJJJ-MM-TT' hat. Null wird zurückgegeben, wenn die Zeichenfolge keine gültige Übereinstimmung ergibt. |
| Besetzung (Datum als Zeitstempel) | Entsprechend der aktuellen lokalen Zeitzone wird für diesen Casting-Vorgang ein Zeitstempelwert erstellt |
| Besetzung (Datum als Zeichenfolge) | JJJJ-MM-TT wird für den Wert Jahr / Monat / Datum gebildet und die Ausgabe erfolgt im Zeichenfolgenformat. |
2. Sammlungsdatentypen
Es gibt vier Sammlungsdatentypen in der Struktur, die auch als komplexe Datentypen bezeichnet werden.
- ARRAY
- KARTE
- STRUKTUR
- UNIONTYPE
1. ARRAY: Eine Folge von Elementen eines gemeinsamen Typs, die indiziert werden können und deren Indexwert bei Null beginnt.
Code:
array ('anand', 'balaa', 'praveeen');
2. MAP: Dies sind Elemente, die mithilfe von Schlüssel-Wert-Paaren deklariert und abgerufen werden.
Code:
'firstvalue' -> 'balakumaran', 'lastvalue' -> 'pradeesh' is represented as map('firstvalue', 'balakumaran', 'last', 'PG'). Now 'balakumaran ' can be retrived with map('first').
3. STRUCT: Wie in C ist die Struktur ein Datentyp, der eine Reihe von Feldern sammelt, die beschriftet sind und von einem beliebigen anderen Datentyp sein können.
Code:
For a column D of type STRUCT (Y INT; Z INT) the Y field can be retrieved by the expression DY
4. UNIONTYPE: Union kann einen der angegebenen Datentypen enthalten.
Code:
CREATE TABLE test(col1 UNIONTYPE ) CREATE TABLE test(col1 UNIONTYPE )
Ausgabe:

Verschiedene Trennzeichen, die in komplexen Datentypen verwendet werden, sind nachstehend aufgeführt.
| Trennzeichen | Code | Beschreibung |
| \ n | \ n | Datensatz- oder Zeilentrennzeichen |
| A (Strg + A) | \ 001 | Feldbegrenzer |
| B (Strg + B) | \ 002 | STRUCTS und ARRAYS |
| C (Strg + C) | \ 003 | MAP's |
Beispiel für komplexe Datentypen
Nachfolgend finden Sie Beispiele für komplexe Datentypen:
1. TISCHERSTELLUNG
Code:
create table store_complex_type (
emp_id int,
name string,
local_address STRUCT,
country_address MAP,
job_history array)
row format delimited fields terminated by ', '
collection items terminated by ':'
map keys terminated by '_';
2. MUSTERTABELLENDATEN
Code:
100, Shan, 4th : CHN : IND : 600101, CHENNAI_INDIA, SI : CSC
101, Jai, 1th : THA : IND : 600096, THANJAVUR_INDIA, HCL : TM
102, Karthik, 5th : AP : IND : 600089, RENIKUNDA_INDIA, CTS : HCL
3. LADEN DER DATEN
Code:
load data local inpath '/home/cloudera/Desktop/Hive_New/complex_type.txt' overwrite into table store_complex_type;
4. ANZEIGEN DER DATEN
Code:
select emp_id, name, local_address.city, local_address.zipcode, country_address('CHENNAI'), job_history(0) from store_complex_type where emp_id='100';
Schlussfolgerung - Hive-Datentypen
Als relationale Datenbank und dennoch als Sequel-Verbindung bietet der HIVE auf sehr raffinierte Weise alle wichtigen Eigenschaften der üblichen SQL-Datenbanken. Damit gehört er zu den effizienteren strukturierten Datenverarbeitungseinheiten in Hadoop.
Empfohlene Artikel
Dies ist eine Anleitung zum Hive-Datentyp. Hier diskutieren wir zwei Typen in Hive-Datentypen mit geeigneten Beispielen. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren -
- Was ist ein Bienenstock?
- Hive-Alternativen
- Integrierte Funktionen
- Fragen im Vorstellungsgespräch bei Hive
- PL / SQL-Datentypen
- Beispiele für integrierte Python-Funktionen
- Verschiedene Arten von SQL-Daten mit Beispielen