
Einführung in Data Science Lifecycle
Im Mittelpunkt des Data Science Lifecycle steht die Verwendung von maschinellem Lernen und anderen Analysemethoden, um Erkenntnisse und Vorhersagen aus Daten zu gewinnen und ein Geschäftsziel zu erreichen. Der gesamte Prozess umfasst mehrere Schritte wie Datenbereinigung, Aufbereitung, Modellierung, Modellbewertung usw. Der Prozess ist langwierig und kann mehrere Monate dauern. Daher ist es sehr wichtig, für jedes Problem eine allgemeine Struktur zu haben. Die weltweit anerkannte Struktur zur Lösung von Analyseproblemen wird als branchenübergreifender Standardprozess für Data Mining oder CRISP-DM-Framework bezeichnet.
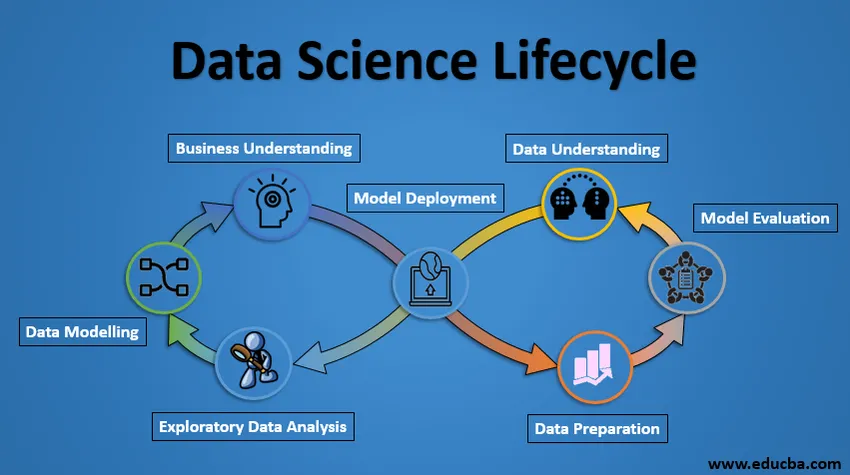
Lebenszyklus der Datenwissenschaft
Nachfolgend finden Sie das Lifecycle of Data Science-Projekt.
1. Geschäftsverständnis
Der gesamte Zyklus dreht sich um das Geschäftsziel. Was lösen Sie, wenn Sie kein genaues Problem haben? Es ist äußerst wichtig, das Geschäftsziel klar zu verstehen, da dies Ihr Endziel bei der Analyse ist. Nur wenn wir es richtig verstanden haben, können wir das spezifische Ziel der Analyse festlegen, das mit dem Geschäftsziel übereinstimmt. Sie müssen wissen, ob der Kunde Kreditverluste reduzieren oder den Preis einer Ware vorhersagen möchte.
2. Datenverständnis
Nach dem Geschäftsverständnis ist der nächste Schritt das Datenverständnis. Dies beinhaltet die Erfassung aller verfügbaren Daten. Hier müssen Sie eng mit dem Geschäftsteam zusammenarbeiten, da diese wissen, welche Daten vorhanden sind, welche Daten für dieses Geschäftsproblem verwendet werden können und andere Informationen. Dieser Schritt beinhaltet die Beschreibung der Daten, ihrer Struktur, ihrer Relevanz und ihres Datentyps. Untersuchen Sie die Daten mithilfe grafischer Darstellungen. Extrahieren von Informationen, die Sie über die Daten erhalten können, indem Sie nur die Daten untersuchen.
3. Datenaufbereitung
Als nächstes folgt die Datenvorbereitung. Dies umfasst Schritte wie die Auswahl der relevanten Daten, die Integration der Daten durch Zusammenführen der Datensätze, die Bereinigung, die Behandlung der fehlenden Werte durch Entfernen oder die Eingabe, die Behandlung fehlerhafter Daten durch Entfernen sowie die Prüfung auf Ausreißer mithilfe von Boxplots und deren Behandlung . Erstellen Sie neue Daten und leiten Sie neue Funktionen aus vorhandenen ab. Formatieren Sie die Daten in die gewünschte Struktur, entfernen Sie unerwünschte Spalten und Features. Die Datenaufbereitung ist der zeitaufwendigste und wohl wichtigste Schritt im gesamten Lebenszyklus. Ihr Modell ist so gut wie Ihre Daten.
4. Explorative Datenanalyse
In diesem Schritt erhalten Sie eine Vorstellung von der Lösung und den sie beeinflussenden Faktoren, bevor Sie das eigentliche Modell erstellen. Die Verteilung von Daten innerhalb verschiedener Variablen eines Features wird mithilfe von Balkendiagrammen grafisch untersucht. Die Beziehungen zwischen verschiedenen Features werden durch grafische Darstellungen wie Streudiagramme und Wärmekarten erfasst. Viele andere Datenvisualisierungstechniken werden häufig verwendet, um jedes Merkmal einzeln zu untersuchen und mit anderen Merkmalen zu kombinieren.
5. Datenmodellierung
Datenmodellierung ist das Herzstück der Datenanalyse. Ein Modell nimmt die vorbereiteten Daten als Eingabe und liefert die gewünschte Ausgabe. Dieser Schritt umfasst die Auswahl des geeigneten Modelltyps, unabhängig davon, ob es sich bei dem Problem um ein Klassifizierungsproblem oder ein Regressionsproblem oder ein Clusterproblem handelt. Nachdem wir die Modellfamilie unter den verschiedenen Algorithmen dieser Familie ausgewählt haben, müssen wir die Algorithmen sorgfältig auswählen, um sie zu implementieren und zu implementieren. Wir müssen die Hyperparameter jedes Modells anpassen, um die gewünschte Leistung zu erzielen. Wir müssen auch sicherstellen, dass ein korrektes Gleichgewicht zwischen Leistung und Generalisierbarkeit besteht. Wir möchten nicht, dass das Modell die Daten lernt und bei neuen Daten eine schlechte Leistung erzielt.
6. Modellbewertung
Hier wird das Modell ausgewertet, um zu überprüfen, ob es bereit ist, bereitgestellt zu werden. Das Modell wird anhand unsichtbarer Daten getestet und anhand sorgfältig durchdachter Bewertungsmetriken bewertet. Wir müssen auch sicherstellen, dass das Modell der Realität entspricht. Wenn die Auswertung kein zufriedenstellendes Ergebnis liefert, müssen wir den gesamten Modellierungsprozess wiederholen, bis das gewünschte Maß erreicht ist. Jede datenwissenschaftliche Lösung, ein Modell des maschinellen Lernens, sollte sich wie ein Mensch weiterentwickeln, sich selbst mit neuen Daten verbessern und sich an eine neue Bewertungsmetrik anpassen können. Wir können mehrere Modelle für ein bestimmtes Phänomen erstellen, aber viele davon können unvollkommen sein. Die Modellbewertung hilft uns bei der Auswahl und Erstellung eines perfekten Modells.
7. Modellbereitstellung
Das Modell nach einer strengen Evaluierung wird schließlich im gewünschten Format und Kanal bereitgestellt. Dies ist der letzte Schritt im Data Science-Lebenszyklus. Jeder oben erläuterte Schritt im Data Science-Lebenszyklus sollte sorgfältig abgearbeitet werden. Wenn ein Schritt nicht ordnungsgemäß ausgeführt wird, wirkt sich dies auf den nächsten Schritt aus und der gesamte Aufwand geht verloren. Wenn Daten beispielsweise nicht ordnungsgemäß erfasst werden, gehen Informationen verloren und Sie erstellen kein perfektes Modell. Wenn die Daten nicht ordnungsgemäß bereinigt werden, funktioniert das Modell nicht. Wenn das Modell nicht ordnungsgemäß ausgewertet wird, schlägt es in der realen Welt fehl. Vom Geschäftsverständnis bis zur Modellbereitstellung sollte jedem Schritt die richtige Aufmerksamkeit, Zeit und Mühe geschenkt werden.
Empfohlene Artikel
Dies ist ein Leitfaden zum Data Science-Lebenszyklus. Hier diskutieren wir einen Überblick über den Data Science-Lebenszyklus und die Schritte, die einen Data Science-Lebenszyklus ausmachen. Sie können auch unsere verwandten Artikel durchgehen, um mehr zu erfahren -
- Einführung in Data Science-Algorithmen
- Data Science vs Software Engineering | Top 8 nützliche Vergleiche
- Unterschiedstypen von Data Science-Techniken
- Data Science Skills mit Typen