

Was ist der Boosting-Algorithmus?
Boosting ist die Methode in Algorithmen, die schwache Lerner in starke Lerner umwandeln. Diese Technik fügt neue Modelle hinzu, um vorhandene Modellfehler zu korrigieren.
Beispiel:
Verstehen wir dieses Konzept anhand des folgenden Beispiels. Nehmen wir ein Beispiel für die E-Mail. Woran erkennen Sie, ob es sich bei Ihrer E-Mail um Spam handelt? Sie können es an folgenden Bedingungen erkennen:
- Wenn eine E-Mail so viele Quellen enthält, handelt es sich um Spam.
- Wenn eine E-Mail nur ein Bild enthält, handelt es sich um Spam.
- Wenn eine E-Mail die Nachricht "Sie besitzen eine Lotterie von $ xxxxx" enthält, bedeutet dies, dass es sich um Spam handelt.
- Wenn eine E-Mail eine bekannte Quelle enthält, handelt es sich nicht um Spam.
- Wenn es die offizielle Domain wie educba.com usw. enthält, bedeutet dies, dass es sich nicht um Spam handelt.
Die oben genannten Regeln sind nicht so mächtig, um den Spam zu erkennen oder nicht, daher werden diese Regeln als schwache Lerner bezeichnet.
Um einen schwachen in einen starken Lernenden umzuwandeln, kombinieren Sie die Vorhersage des schwachen Lernenden mit den folgenden Methoden.
- Verwenden des Durchschnitts oder des gewichteten Durchschnitts.
- Betrachten Sie Vorhersage hat eine höhere Stimme.
Beachten Sie die oben genannten 5 Regeln, es gibt 3 Stimmen für Spam und 2 Stimmen für Nicht-Spam. Da es Spam mit hoher Stimmenzahl gibt, betrachten wir ihn als Spam.
Wie funktioniert das Boosten von Algorithmen?
Boosting-Algorithmen kombinieren jeden schwachen Lernenden, um eine starke Vorhersageregel zu erstellen. Um die schwache Regel zu identifizieren, gibt es einen Basis-Lernalgorithmus (Machine Learning). Bei jeder Anwendung des Basisalgorithmus werden mithilfe des Iterationsprozesses neue Vorhersageregeln erstellt. Nach einer gewissen Iteration werden alle schwachen Regeln kombiniert, um eine einzige Vorhersageregel zu erstellen.
Um die richtige Verteilung zu wählen, gehen Sie wie folgt vor:
Schritt 1: Der Basislernalgorithmus kombiniert jede Verteilung und wendet für jede Verteilung das gleiche Gewicht an.
Schritt 2: Wenn während des ersten Basislernalgorithmus eine Vorhersage erfolgt, wird diesem Vorhersagefehler große Aufmerksamkeit geschenkt.
Schritt 3: Wiederholen Sie Schritt 2, bis die Grenze des Basislernalgorithmus oder eine hohe Genauigkeit erreicht wurde.
Schritt 4: Schließlich werden alle schwachen Lernenden zu einer starken Vorhersage zusammengefasst.
Arten von Boosting-Algorithmen
Boosting-Algorithmen verwenden verschiedene Engines wie Entscheidungsstempel, Klassifizierungsalgorithmus zur Maximierung des Spielraums usw. Es gibt drei Arten von Boosting-Algorithmen:
- AdaBoost-Algorithmus (Adaptive Boosting)
- Gradient Boosting-Algorithmus
- XG-Boost-Algorithmus
AdaBoost-Algorithmus (Adaptive Boosting)
Um AdaBoost zu verstehen, beachten Sie bitte das folgende Bild:
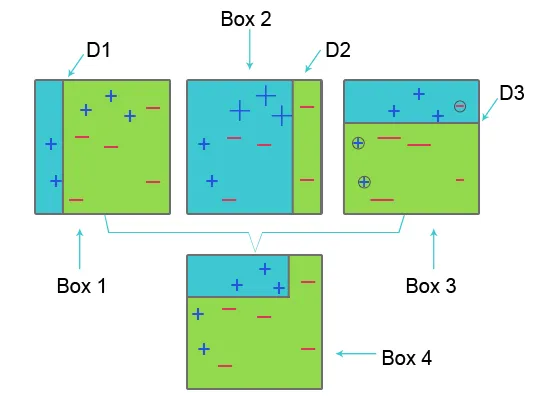
Box 1: In Box 1 haben wir für jeden Datensatz die gleichen Gewichte vergeben und zur Klassifizierung von Plus (+) und Minus (-) setzen wir den Entscheidungsstumpf D1 ein, der eine vertikale Linie auf der linken Seite von Box 1 erzeugt. Diese Linie ist falsch prognostizierte drei Pluszeichen (+) als Minuszeichen (-), daher wenden wir höhere Gewichte auf diese Pluszeichen an und wenden einen weiteren Entscheidungsstumpf an.
Kasten 2: In Kasten 2 wird die Größe von drei falsch vorhergesagten Pluszeichen (+) im Vergleich zu einem anderen größer. Der zweite Entscheidungsstumpf D2 auf der rechten Seite des Blocks sagt dieses falsch vorhergesagte Pluszeichen (+) als korrekt voraus. Da jedoch aufgrund des ungleichen Gewichts mit einem Minuszeichen (-) ein Fehlklassifizierungsfehler aufgetreten ist, weisen wir einem Minuszeichen (-) ein höheres Gewicht zu und wenden einen weiteren Entscheidungsstumpf an.
Feld 3: In Feld 3 hat das Minuszeichen (-) aufgrund eines Fehlklassifizierungsfehlers ein hohes Gewicht. Hier wird der Entscheidungsstumpf D3 angewendet, um diese Fehlklassifizierung vorherzusagen und zu korrigieren. Dieses Mal wird eine horizontale Linie zum Klassifizieren der Plus- (+) und Minuszeichen (-) erstellt.
Kasten 4: In Kasten 4 werden Entscheidungsstumpf D1, D2 und D3 kombiniert, um eine neue starke Vorhersage zu erstellen.
Adaptive Boosting funktioniert ähnlich wie oben erwähnt. Es kombiniert die Gruppe der schwachen Lernenden anhand des Gewichtsalters, um einen starken Lernenden zu schaffen. In der ersten Iteration erhält jeder Datensatz die gleiche Gewichtung, und die Vorhersage dieses Datensatzes beginnt. Wenn eine inkorrekte Vorhersage auftritt, wird dieser Beobachtung ein hohes Gewicht beigemessen. Adaptives Boosten Wiederholen Sie diesen Vorgang in der nächsten Iterationsphase und fahren Sie fort, bis die Genauigkeit erreicht ist. Kombiniert dies dann, um eine starke Vorhersage zu erstellen.
Gradienten-Boosting-Algorithmus
Der Gradientenverstärkungsalgorithmus ist eine maschinelle Lernmethode, um die Verlustfunktion zu definieren und zu reduzieren. Es wird verwendet, um Probleme der Klassifikation mit Hilfe von Vorhersagemodellen zu lösen. Es umfasst die folgenden Schritte:
1. Verlustfunktion
Die Verwendung der Verlustfunktion hängt von der Art des Problems ab. Der Vorteil der Gradientenanhebung besteht darin, dass für jede Verlustfunktion kein neuer Anhebungsalgorithmus erforderlich ist.
2. Schwacher Lerner
Bei der Steigungserhöhung werden Entscheidungsbäume als schwache Lernenden verwendet. Ein Regressionsbaum wird verwendet, um wahre Werte anzugeben, die kombiniert werden können, um korrekte Vorhersagen zu erstellen. Wie beim AdaBoost-Algorithmus werden kleine Bäume mit einfacher Teilung verwendet, dh Entscheidungsstumpf. Größere Bäume werden für große Ebenen i und 4-8 Ebenen verwendet.
3. Additives Modell
In diesem Modell werden Bäume einzeln hinzugefügt. vorhandene Bäume bleiben gleich. Während des Hinzufügens von Bäumen wird ein Gefälle verwendet, um die Verlustfunktion zu minimieren.
XG Boost
XG Boost ist die Abkürzung für Extreme Gradient Boosting. XG Boost ist eine aktualisierte Implementierung des Gradienten-Boosting-Algorithmus, der für hohe Rechengeschwindigkeit, Skalierbarkeit und bessere Leistung entwickelt wurde.
XG Boost bietet folgende Funktionen:
- Parallelverarbeitung: XG Boost bietet Parallelverarbeitung für die Baumkonstruktion, bei der während des Trainings CPU-Kerne verwendet werden.
- Cross-Validation: Mit XG Boost können Benutzer bei jeder Iteration eine Cross-Validation des Boosting-Prozesses durchführen, um auf einfache Weise die genau optimale Anzahl von Boosting-Iterationen in einem Durchgang zu erhalten.
- Cache-Optimierung: Bietet eine Cache-Optimierung der Algorithmen für eine höhere Ausführungsgeschwindigkeit.
- Distributed Computing : Zum Trainieren großer Modelle ermöglicht XG Boost Distributed Computing.
Empfohlene Artikel
In diesem Artikel haben wir gesehen, was Boosting-Algorithmus ist, verschiedene Arten von Boosting-Algorithmen beim maschinellen Lernen und ihre Funktionsweise. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- Was ist maschinelles Lernen? | Eine Definition
- Programmiersprachen zum Lernen von Algorithmen
- Was ist Blockchain-Technologie?
- Was ist ein Algorithmus?