

Unterschied zwischen Hadoop und Hive
Hadoop:
Hadoop ist ein Framework oder eine Software, die zur Verwaltung großer Datenmengen oder Big Data entwickelt wurde. Hadoop wird zum Speichern und Verarbeiten der großen Datenmengen verwendet, die über einen Cluster von Commodity-Servern verteilt sind.
Hadoop speichert die Daten mit dem verteilten Hadoop-Dateisystem und verarbeitet / fragt sie mit dem Map Reduce-Programmiermodell ab.
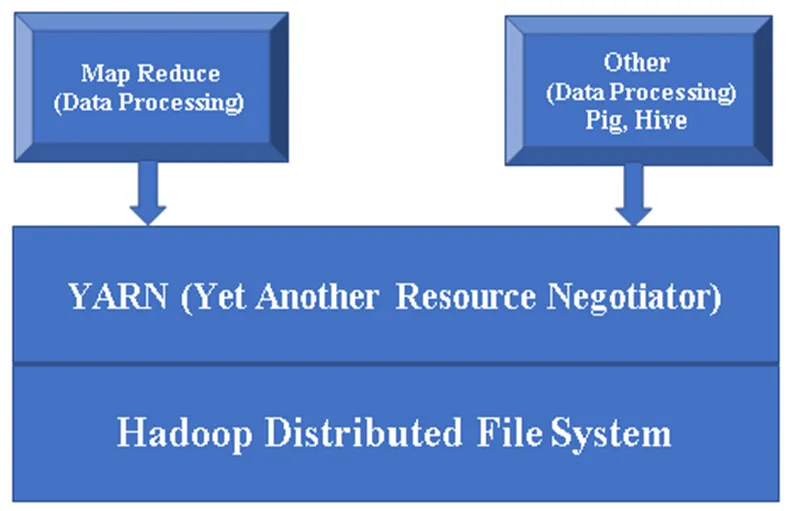
Abbildung 1: Grundlegende Architektur einer Hadoop-Komponente
Die Hauptkomponenten von Hadoop:
Hadoop Base / Common: Hadoop Common bietet Ihnen eine Plattform für die Installation aller Komponenten.
HDFS (Hadoop Distributed File System): HDFS ist ein wesentlicher Bestandteil des Hadoop-Frameworks und kümmert sich um alle Daten in Hadoop Cluster. Es arbeitet mit der Master / Slave-Architektur und speichert die Daten mithilfe der Replikation.
Master / Slave Architektur & Replikation:
- Masterknoten / Namensknoten: Der Namensknoten speichert die Metadaten jedes Blocks / jeder Datei, die in HDFS gespeichert sind. HDFS kann nur einen Masterknoten haben (im Fall von HA fungiert ein anderer Masterknoten als sekundärer Masterknoten).
- Slave-Knoten / Datenknoten: Datenknoten enthalten tatsächliche Datendateien in Blöcken. HDFS kann mehrere Datenknoten haben.
- Replikation: HDFS speichert seine Daten, indem es sie in Blöcke unterteilt. Die Standardblockgröße beträgt 64 MB. Aufgrund der Replikation werden die Daten in 3 (Standard-Replikationsfaktor, kann je nach Anforderung erhöht werden) verschiedenen Datenknoten gespeichert. Daher besteht die geringste Wahrscheinlichkeit, dass die Daten bei einem Knotenausfall verloren gehen.
YARN (noch ein weiterer Resource Negotiator): Er wird hauptsächlich für die Verwaltung von Hadoop-Ressourcen verwendet und spielt auch eine wichtige Rolle bei der Planung der Benutzeranwendung.
MR (Map Reduce): Dies ist das grundlegende Programmiermodell von Hadoop. Es wird verwendet, um die Daten innerhalb des Hadoop-Frameworks zu verarbeiten / abzufragen.
Bienenstock:
Hive ist eine Anwendung, die über das Hadoop-Framework ausgeführt wird und eine SQL-ähnliche Schnittstelle zum Verarbeiten / Abfragen der Daten bietet. Hive wurde von Facebook entworfen und entwickelt, bevor es Teil des Apache-Hadoop-Projekts wurde.
Hive führt seine Abfrage mit HQL (Hive-Abfragesprache) aus. Hive hat dieselbe Struktur wie RDBMS und in Hive können fast dieselben Befehle verwendet werden.
Hive kann die Daten in externen Tabellen speichern, daher ist die Verwendung von HDFS nicht zwingend erforderlich. Außerdem werden Dateiformate wie ORC, Avro-Dateien, Sequenzdateien und Textdateien usw. unterstützt.
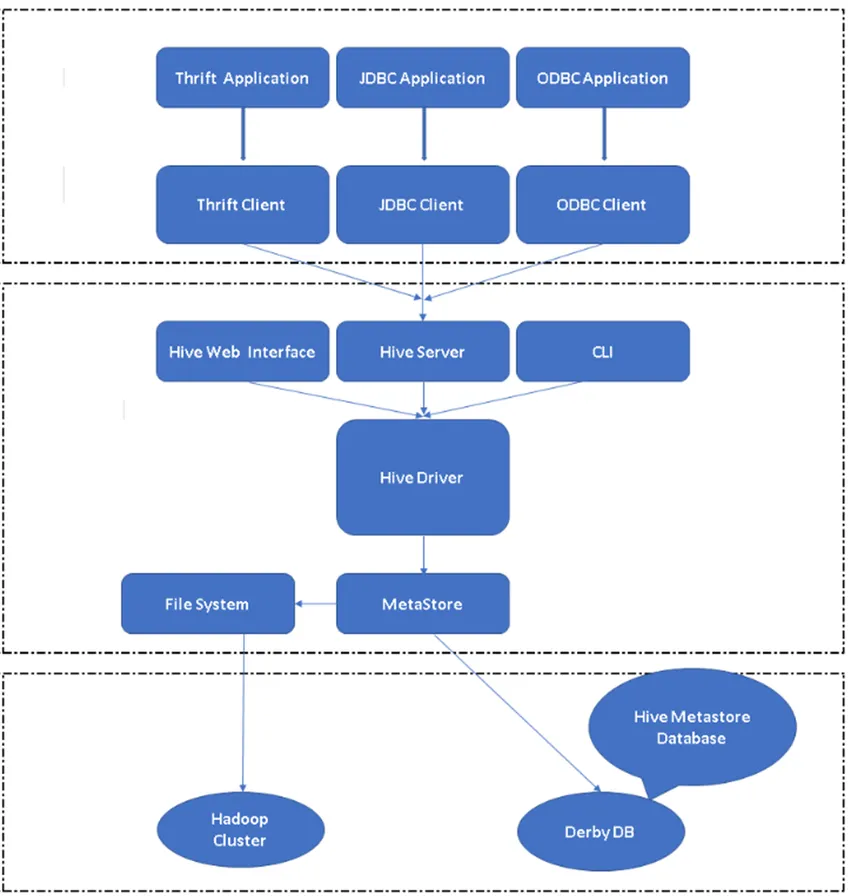
Abbildung 2, Hives Architektur und seine Hauptkomponenten.
Hauptbestandteil von Hive:
Hive-Clients: Hive unterstützt nicht nur SQL, sondern auch Programmiersprachen wie Java, C, Python mit verschiedenen Treibern wie ODBC, JDBC und Thrift. Man kann jede Hive-Client-Anwendung in anderen Sprachen schreiben und mit diesen Clients in Hive ausführen.
Hive Services: Unter Hive Services werden Befehle und Abfragen ausgeführt. Das Hive-Webinterface besteht aus fünf Unterkomponenten.
- CLI: Standard-Befehlszeilenschnittstelle, die von Hive zur Ausführung von Hive-Abfragen / -Befehlen bereitgestellt wird.
- Hive Web Interfaces: Dies ist eine einfache grafische Benutzeroberfläche. Es ist eine Alternative zur Hive-Befehlszeile und wird zum Ausführen der Abfragen und Befehle in der Hive-Anwendung verwendet.
- Hive Server: Wird auch als Apache Thrift bezeichnet. Es ist dafür verantwortlich, Befehle von verschiedenen Befehlszeilenschnittstellen entgegenzunehmen und alle Befehle / Abfragen an Hive zu senden. Außerdem ruft es das Endergebnis ab.
- Apache Hive Driver: Er ist dafür verantwortlich, die Eingaben von der CLI, der Web-Benutzeroberfläche, ODBC, JDBC oder Thrift-Schnittstellen von einem Client zu übernehmen und die Informationen an den Metastore weiterzuleiten, in dem alle Dateiinformationen gespeichert sind.
- Metastore: Metastore ist ein Repository zum Speichern aller Hive-Metadateninformationen. In den Metadaten von Hive werden Informationen wie die Struktur von Tabellen, Partitionen und Spaltentypen usw. gespeichert.
Hive-Speicher: Dies ist der Ort, an dem die eigentliche Aufgabe ausgeführt wird. Alle Abfragen, die von Hive ausgeführt werden, haben die Aktion im Hive-Speicher ausgeführt.
Head to Head Vergleich zwischen Hadoop und Hive (Infografik)
Unten ist der Top 8 Unterschied zwischen Hadoop vs Hive
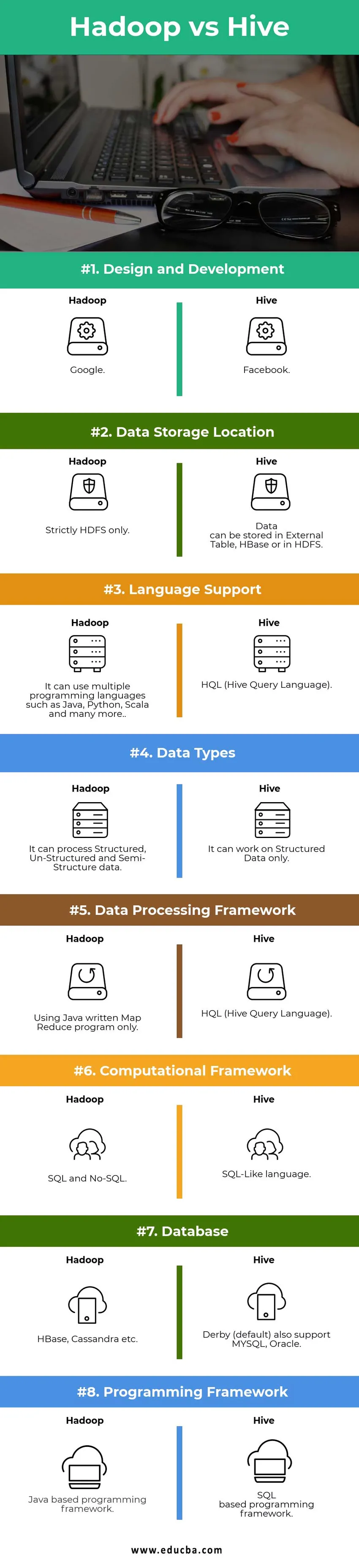
Hauptunterschiede zwischen Hadoop und Hive:
Nachfolgend sind die Punktelisten aufgeführt, die die wichtigsten Unterschiede zwischen Hadoop und Hive beschreiben:
1) Hadoop ist ein Framework zum Verarbeiten / Abfragen der Big Data, während Hive ein SQL-basiertes Tool ist, das über Hadoop erstellt, um die Daten zu verarbeiten.
2) Hive verarbeitet / fragt alle Daten mit HQL (Hive Query Language) ab, einer SQL-ähnlichen Sprache, während Hadoop nur Map Reduce versteht.
3) Map Reduce ist ein wesentlicher Bestandteil von Hadoop. Die Abfrage von Hive wird zuerst in Map Reduce konvertiert und dann von Hadoop verarbeitet, um die Daten abzufragen.
4) Hive arbeitet mit SQL-ähnlichen Abfragen, während Hadoop diese nur mit Java-basierter Map Reduce versteht.
5) In Hive können auch früher verwendete traditionelle "Relational Database" -Befehle zum Abfragen der Big Data verwendet werden, während in Hadoop komplexe Map Reduce-Programme mit Java geschrieben werden müssen, das nicht mit traditionellem Java vergleichbar ist.
6) Hive kann nur die strukturierten Daten verarbeiten / abfragen, während Hadoop für alle Arten von Daten gedacht ist, unabhängig davon, ob es sich um strukturierte, unstrukturierte oder halbstrukturierte Daten handelt.
7) Mit Hive kann man die Daten ohne komplexe Programmierung verarbeiten / abfragen, während im Simple Hadoop-Ökosystem komplexe Java-Programme für dieselben Daten geschrieben werden müssen.
8) Eine Seite von Hadoop-Frameworks benötigt 100s Zeile für die Vorbereitung eines Java-basierten MR-Programms. Eine andere Seite von Hadoop mit Hive kann dieselben Daten mit 8 bis 10 Zeilen HQL abfragen.
9) In Hive ist es sehr schwierig, die Ausgabe einer Abfrage als Eingabe einer anderen einzufügen, während dieselbe Abfrage mit Hadoop mit MR problemlos durchgeführt werden kann.
10) Es ist nicht zwingend erforderlich, Metastore im Hadoop-Cluster zu haben, während Hadoop alle seine Metadaten in HDFS (Hadoop Distributed File System) speichert.
Hadoop vs Hive Vergleichstabelle
| Vergleichspunkte | Bienenstock | Hadoop |
|
Design und Entwicklung | ||
| Datenspeicherort |
Daten können in Extern gespeichert werden Tabelle, HBase oder in HDFS. | Nur für HDFS. |
| Sprachunterstützung | HQL (Hive Query Language) |
Es können mehrere Programmiersprachen wie Java, Python, Scala und viele mehr verwendet werden. |
| Datentypen | Es kann nur mit strukturierten Daten gearbeitet werden. |
Es kann strukturierte, unstrukturierte und halbstrukturierte Daten verarbeiten. |
| Datenverarbeitungs-Framework |
HQL (Hive Query Language) | Verwenden Sie nur ein mit Java geschriebenes Map Reduce-Programm. |
|
Computational Framework | SQL-ähnliche Sprache. | SQL und No-SQL. |
| Datenbank |
Derby (Standard) unterstützt auch MYSQL, Oracle … | HBase, Cassandra usw. |
| Programmier-Framework |
SQL-basiertes Programmierframework. | Java-basiertes Programmierframework. |
Fazit - Hadoop vs Hive
Hadoop und Hive werden beide zur Verarbeitung der Big Data verwendet. Hadoop ist ein Framework, das anderen Anwendungen die Möglichkeit bietet, Big Data abzufragen / zu verarbeiten, während Hive nur eine SQL-basierte Anwendung ist, die die Daten mit HQL (Hive Query Language) verarbeitet.
Hadoop kann ohne Hive zum Verarbeiten von Big Data verwendet werden, während es ohne Hadoop nicht einfach ist, Hive zu verwenden.
Zusammenfassend lässt sich festhalten, dass wir Hadoop und Hive in keiner Hinsicht vergleichen können. Sowohl Hadoop als auch Hive sind völlig unterschiedlich. Wenn Sie beide Technologien zusammen ausführen, kann der Big-Data-Abfrageprozess für Big-Data-Benutzer viel einfacher und komfortabler werden.
Empfohlene Artikel:
Dies war ein Leitfaden für Hadoop vs Hive, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Hadoop vs Apache Spark - Interessante Dinge, die Sie wissen müssen
- HADOOP vs RDBMS | Kennen Sie die 12 nützlichen Unterschiede
- Wie Big Data das Gesicht des Gesundheitswesens verändert
- Top 12 Vergleich von Apache HBase vs Apache Hive (Infographics)
- Erstaunliche Anleitung zu Hadoop vs Spark