
Einführung in R CSV-Dateien
CSV-Dateien werden häufig verwendet, um die Informationen in Tabellenform zu speichern, wobei jede Zeile ein Datensatz ist. Um Daten in R lesen, schreiben oder manipulieren zu können, müssen uns einige Daten zur Verfügung stehen. Die Daten können im Internet gefunden oder aus verschiedenen Quellen wie Umfragen zusammengetragen werden. Mit R kann man die Daten lesen, schreiben und bearbeiten, die in einer externen Umgebung gespeichert sind. R kann Daten aus verschiedenen Formaten wie XML, CSV und Excel lesen und schreiben. In diesem Artikel erfahren Sie, wie Sie mit R verschiedene Vorgänge für CSV-Dateien lesen, schreiben und ausführen können.
Erstellen einer CSV-Datei in R
In diesem Abschnitt wird gezeigt, wie ein Datenrahmen erstellt und in die CSV-Datei in R exportiert werden kann. Im ersten Abschnitt wird ein Datenrahmen erstellt, der aus den Variablen Mitarbeiter und dem jeweiligen Gehalt besteht.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
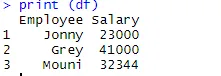
Sobald der Datenrahmen erstellt ist, ist es Zeit, dass wir die Exportfunktion von R verwenden, um eine CSV-Datei in R zu erstellen. Um den Datenrahmen in CSV zu exportieren, können wir den folgenden Code verwenden.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
In der obigen Codezeile haben wir ein Pfadverzeichnis für unseren Datenrahmen angegeben und den Datenrahmen im CSV-Format gespeichert. In diesem Fall wurde die CSV-Datei auf meinem persönlichen Desktop gespeichert. Diese spezielle Datei wird in unserem Lernprogramm für die Ausführung mehrerer Vorgänge verwendet.
Lesen von CSV-Dateien in R
Bei der Durchführung von Analysen mit R müssen wir in vielen Fällen die Daten aus der CSV-Datei lesen. R ist beim Lesen von CSV-Dateien sehr zuverlässig. Im obigen Beispiel haben wir die Datei erstellt, die wir zum Lesen mit dem Befehl read.csv verwenden werden. Unten ist das Beispiel dafür in R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Der obige Befehl liest die Datei Employee.csv, die auf dem Desktop verfügbar ist, und zeigt sie in R Studio an. Der Befehl "Header" impliziert, dass der Header für das Dataset verfügbar gemacht wird, und der Befehl "sep" impliziert, dass die Daten durch Kommas getrennt sind.
Schreiben Sie CSV-Dateien in R
Das Schreiben in eine CSV-Datei ist eine der nützlichsten Funktionen, die in R für einen Datenanalysten verfügbar sind. Hiermit kann eine bearbeitete CSV-Datei in eine neue CSV-Datei geschrieben werden, um die Daten zu analysieren. Mit dem Befehl Write.csv wird die Datei in CSV geschrieben.
Im folgenden Code df in dem Datenrahmen, in dem unsere Daten verfügbar sind, wird mit Anhängen angegeben, dass die neue Datei erstellt wird, anstatt in der alten Datei angehängt oder überschrieben zu werden. Falsch anhängen bedeutet, dass eine neue CSV-Datei erstellt wird. Sep steht für das durch Komma getrennte Feld.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV-Operationen
CSV-Vorgänge müssen die Daten nach dem Laden in das System überprüfen. R verfügt über mehrere integrierte Funktionen zum Überprüfen und Überprüfen der Daten. Diese Vorgänge bieten vollständige Informationen zum Datensatz.
Einer der am häufigsten verwendeten Befehle ist eine Zusammenfassung.
> summary(df)
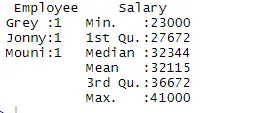
Der Befehl summary liefert uns spaltenweise Statistiken. Die numerische Variable wird auf statistische Weise beschrieben, die statistische Ergebnisse wie Mittelwert, Min, Median und Max enthält. Im obigen Beispiel werden zwei Variablen, Employee und Salary, getrennt und Statistiken für die numerische Variable Salary angezeigt.
Mit dem Befehl View () wird das Dataset auf einer anderen Registerkarte geöffnet und manuell überprüft.
> View(df)

Die Str-Funktion liefert dem Benutzer weitere Details zur Spalte des Datensatzes. Im folgenden Beispiel sehen wir, dass die Variable Employee den Datentyp Factor und die Variable Salary den Datentyp int (integer) hat.
> str(df)

In vielen Fällen müssen wir die Gesamtzahl der verfügbaren Zeilen im Falle des großen Datasets sehen, für das wir den Befehl nrow () verwenden können. Bitte beachten Sie das folgende Beispiel.
> # to show the total number of rows in the dataset
> nrow(df)

Auf ähnliche Weise können wir die Gesamtzahl der Spalten mit dem Befehl ncol () anzeigen
> ncol(df)

Mit R können wir die gewünschte Anzahl von Zeilen mit Hilfe des folgenden Befehls anzeigen. Wenn die Anzahl n der Zeilen im Datensatz verfügbar ist, können wir den anzuzeigenden Zeilenbereich angeben.
> # to display first 2 rows of the data
> df(1:2, )

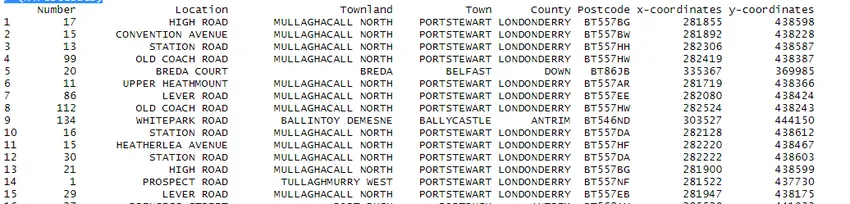
Die Datenoperation wird für den großen Datensatz ausgeführt. Zur Veranschaulichung habe ich den Open-Source-Datensatz für die Postleitzahl von NI aus dem Internet heruntergeladen.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
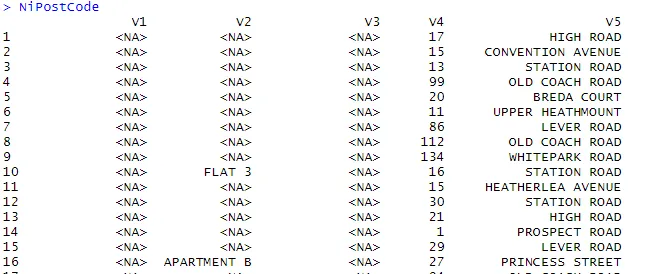
Im obigen Datensatz sehen wir, dass die Headernamen fehlen und viele Nullwerte vorhanden sind. Der Datensatz muss gereinigt werden, um für die Analyse bereit zu sein. Im nächsten Schritt werden die Überschriften entsprechend benannt.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Zählen wir nun die Anzahl der fehlenden Werte im Datenrahmen und entfernen Sie sie entsprechend.
> # count of all missing values
> table(is.na (NiPostCode))

Aus dem obigen Befehl können wir ersehen, dass die Gesamtzahl der Leerzeichen oder NA im Datenrahmen in der Nähe von 5445148 liegt. Das Entfernen aller Nullwerte führt zum Verlust der großen Datenmenge. Daher ist es ratsam, die Spalten zu entfernen, in denen mehr als die Hälfte vorhanden ist von 50% der Daten fehlen.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Fazit
In diesem Tutorial haben wir gesehen, wie CSV-Dateien mit Operationen in R erstellt, gelesen und angehängt werden können. Wir haben gelernt, wie ein neuer Datensatz in R erstellt und anschließend in das CSV-Format importiert wird. Wir haben außerdem mehrere Vorgänge gesehen, z. B. das Umbenennen von Kopfzeilen und das Zählen der Anzahl von Zeilen und Spalten.
Empfohlene Artikel
Dies ist eine Anleitung zu R CSV-Dateien. Hier diskutieren wir das Erstellen, Lesen und Schreiben von CSV-Dateien in R mit den CSV-Operationen. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- JSON gegen CSV
- Data Mining-Prozess
- Karriere in der Datenanalyse
- Excel vs CSV