

Was ist der Bayes-Satz?
Der Satz von Bayes ist ein Rezept, das zeigt, wie die Wahrscheinlichkeiten von Theorien aktualisiert werden, wenn Beweise vorliegen. Es folgt im Wesentlichen den Maximen der bedingten Wahrscheinlichkeit, kann jedoch verwendet werden, um ein breites Spektrum von Fragen, einschließlich Aktualisierungen der Überzeugung, zu erörtern.
Unter der Annahme einer Theorie H und eines Beweises E drückt der Satz von Bayes aus, dass der Zusammenhang zwischen der Wahrscheinlichkeit der Spekulation vor dem Erhalt des Beweises P (H) und der Wahrscheinlichkeit der Theorie nach dem Erhalt des Beweises P (H∣E) besteht
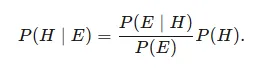
Es ist ein wunderschönes Konzept der Wahrscheinlichkeit, bei dem wir die Wahrscheinlichkeit finden, wenn wir andere Wahrscheinlichkeiten kennen
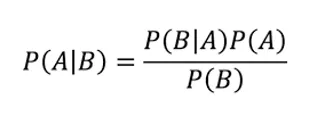
Was uns sagt: Wie häufig A vorkommt, wenn B vorkommt, zusammengesetzt aus P (A | B),
Wenn wir wissen: wie regelmäßig B vorkommt, wenn An vorkommt, zusammengesetzt P (B | A)
darüber hinaus, wie wahrscheinlich es ist, dass An ohne jemand anderen ist, zusammengesetzt aus P (A)
was mehr ist, wie wahrscheinlich es ist, dass B ohne jemand anderen ist, zusammengesetztes P (B)
Beispiel des Bayes-Theorems
Sie planen heute einen Ausflug, aber der Morgen ist bewölkt, Gott hilft uns! Die Hälfte jedes stürmischen Tages beginnt im Schatten! Auf jeden Fall sind schattige Vormittage normal (ungefähr 40% der Tage beginnen bewölkt). Außerdem ist dies im Allgemeinen ein trockener Monat (nur 3 von 30 Tagen sind im Allgemeinen stürmisch oder 10%). Wie hoch ist die Wahrscheinlichkeit, dass es tagsüber regnet? Wir werden Regen verwenden, um Regenguss während des Tages zu bedeuten, und Wolke, um bewölkten Morgen zu bedeuten. Die Möglichkeit von Regen bei Wolken setzt sich zusammen aus P (Regen | Wolke)
Also sollten wir das in die Gleichung einfügen:

- P (Regen) Wahrscheinlichkeit, dass es regnen wird = 10% (Gegeben)
- P (Wolke | Regen) Wahrscheinlichkeit, dass Wolken da sind und Regen passiert = 50%
- P (Wolke) ist die Wahrscheinlichkeit, dass Wolken vorhanden sind = 40%
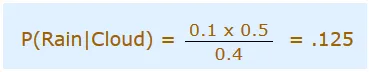
Also können wir sagen, dass In c:
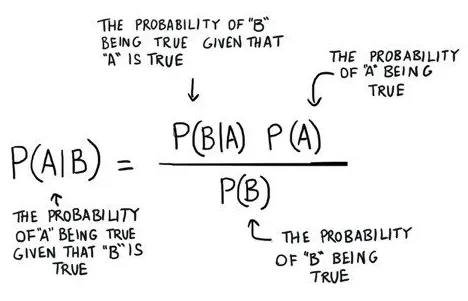
Das ist der Bayes-Satz: dass man die Wahrscheinlichkeit einer Sache nutzen kann, um die Wahrscheinlichkeit von etwas anderem vorherzusagen. Das Bayes-Theorem ist jedoch alles andere als eine statische Sache. Es ist eine Maschine, die Sie für bessere Prognosen als neue Proofoberflächen verwenden. Eine faszinierende Aktivität besteht darin, die Faktoren zu zappeln, indem bestimmte theoretische Eigenschaften auf P (B) oder P (A) herabgesetzt werden, und ihre kohärente Wirkung auf P (A | B) zu berücksichtigen. Wenn Sie zum Beispiel den Nenner P (B) auf der rechten Seite erhöhen, wird P (A | B) an diesem Punkt kleiner. Solides Modell: Eine laufende Nase ist ein Hinweis auf die Masern, dennoch sind laufende Nasen zweifellos typischer als Hautausschläge mit kleinen weißen Flecken. Das heißt, für den Fall, dass Sie P (B) wählen, wo B eine laufende Nase ist, verringert das Wiederauftreten der laufenden Nase in der Gesamtöffentlichkeit die Möglichkeit, dass die laufende Nase ein Hinweis auf Masern ist. Die Wahrscheinlichkeit eines Masernbefundes sinkt in Bezug auf Nebenwirkungen, die sich zunehmend normalisieren. Diese Manifestationen sind keine soliden Zeiger. In ähnlicher Weise steigt P (A | B) mit zunehmender Normalität der Masern und steigendem P (A) im Zähler auf der rechten Seite im Wesentlichen an, da die Masern in der Regel weniger auf die Nebenwirkung achten Du denkst darüber nach.
Verwendung des Bayes-Theorems beim maschinellen Lernen
Naiver Bayes-Klassifikator
Naive Bayes ist eine Charakterisierungsberechnung für doppelte (zwei Klassen) und mehrklassige Gruppierungsprobleme. Das System muss am wenigsten verstanden werden, wenn es mit doppelten oder direkten Infoqualitäten dargestellt wird.
Man nennt es naive Bayes oder imbecile Bayes, da die Ermittlung der Wahrscheinlichkeiten für jede Theorie rationalisiert wird, um ihre Zählung nachvollziehbar zu machen. Im Gegensatz zu dem Bestreben, die Schätzungen jeder Eigenschaftsschätzung P (d1, d2, d3 | h) zu ermitteln, wird angenommen, dass sie in Anbetracht des Zielwerts restriktiv frei sind und als P (d1 | h) * P (d2 | H bestimmt werden. etc.
Dies ist eine solide Annahme, die in echten Informationen am weitesten verbreitet ist, zum Beispiel, dass die Eigenschaften nicht kommunizieren. Nach und nach funktioniert die Methode bei Informationen, bei denen diese Vermutung nicht zutrifft, erstaunlich gut.
Von Naive Bayes-Modellen verwendete Darstellung
Die Darstellung eines naiven Bayes-Algorithmus ist die Wahrscheinlichkeit.
Mit Wahrscheinlichkeiten gesetzte werden zur Einreichung eines wissenschaftlich naiven Bayes'schen Modells abgewiesen. Dies beinhaltet:
Klassenwahrscheinlichkeit: Die Wahrscheinlichkeit für alles im Vorbereitungsdatensatz.
Bedingte Wahrscheinlichkeit: Die bedingte Wahrscheinlichkeit für jede Instanzinformation, die sich bei gegebener Wertschätzung für jede Klasse lohnt.
Nehmen Sie ein Naive Bayes-Modell aus Daten auf. Das Aufnehmen eines naiven Bayes'schen Modells anhand von Vorbereitungsinformationen ist schnell. Die Vorbereitung erfolgt schnell, da für jede Instanz der Klasse und für jede Instanz der Klasse nur die Wahrscheinlichkeitswerte ermittelt werden müssen, für die unterscheidbare Informationswerte (x) vorliegen. Es sollten keine Koeffizienten durch Anreicherungssysteme angepasst werden.
Ermittlung der Klassenwahrscheinlichkeiten
Eine Klassenwahrscheinlichkeit ist im Grunde die Wiederholung von Fällen, bei denen jede Klasse durch die Gesamtzahl der Fälle abgegrenzt ist.
Beispielsweise wird in einer Parallelklasse die Wahrscheinlichkeit, dass ein Fall einen Platz mit Klasse 1 hat, wie folgt bestimmt:
Wahrscheinlichkeit (Klasse = 1) = gesamt (Klasse = 1) / (gesamt (Klasse = 0) + gesamt (Klasse = 1))
Im einfachsten Fall hat jede Klasse eine Wahrscheinlichkeit von 0, 5 oder der Hälfte für ein zweifaches Klassifizierungsproblem mit einer ähnlichen Anzahl von Vorkommen in jeder Instanz der Klasse.
Bedingte Wahrscheinlichkeit ermitteln
Die bedingten Wahrscheinlichkeiten sind das Wiederauftreten jeder Eigenschaftsbewertung für eine bestimmte Klasse, die es wert ist, durch das Wiederauftreten von Beispielen mit dieser Klassenbewertung unterteilt zu werden.
Alle Anwendungen des Bayes-Theorems
In der Realität gibt es viele Verwendungen des Bayes-Theorems. Versuchen Sie, nicht auf die Möglichkeit zu verzichten, dass Sie nicht sofort alle eingeschlossenen Arithmetiken sehen. Ein Gefühl dafür zu bekommen, wie es funktioniert, reicht aus, um zu beginnen.
Die Bayes'sche Entscheidungstheorie ist ein messbarer Weg, um mit der Frage der Beispielklassifikation umzugehen. Unter dieser Hypothese wird erwartet, dass die grundlegende Wahrscheinlichkeitsübertragung für die Klassen bekannt ist. Auf diese Weise erhalten wir einen perfekten Bayes-Klassifikator, gegen den jeder andere Klassifikator eine Entscheidung zur Ausführung trifft.
Wir werden über die drei grundlegenden Verwendungen des Bayes-Theorems sprechen:
- Naiver Bayes-Klassifikator
- Diskriminanzfunktionen und Entscheidungsoberflächen
- Bayes'sche Parameterschätzung
Fazit
Die Größe und Intensität von Bayes 'Theorem überrascht mich immer wieder aufs Neue. Eine Grundidee, die von einem Priester stammt, der vor über 250 Jahren verstorben ist, wird heute in den absolut unverwechselbarsten KI-Verfahren angewendet.
Empfohlene Artikel
Dies ist eine Anleitung zum Bayes-Theorem. Hier diskutieren wir die Verwendung des Bayes-Theorems beim maschinellen Lernen und die Darstellung, die von naiven Bayes-Modellen verwendet wird, mit Beispielen. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Naiver Bayes-Algorithmus
- Arten von Algorithmen für maschinelles Lernen
- Modelle für maschinelles Lernen
- Methoden des maschinellen Lernens