

Splunk Interview Fragen und Antworten - Einführung
Sie haben also endlich Ihren Traumjob in Splunk gefunden, fragen sich aber, wie Sie das Splunk-Interview knacken können und was die wahrscheinlichen Splunk-Interview-Fragen für 2018 sein könnten. Jedes Interview ist anders und der Umfang eines Jobs ist auch anders. Aus diesem Grund haben wir die häufigsten Fragen und Antworten zu Splunk-Vorstellungsgesprächen für 2018 erstellt, um Ihnen dabei zu helfen, Ihr Vorstellungsgespräch erfolgreich zu gestalten.Nachstehend finden Sie die wichtigsten Fragen und Antworten zu Splunk-Vorstellungsgesprächen. Diese Top-Fragen gliedern sich in zwei Teile:
Teil 1 - Splunk Interview Fragen (Basic)
In diesem ersten Teil werden grundlegende Fragen und Antworten zu Splunk-Interviews behandelt.
1. Was ist Splunk? Warum wird Splunk zur Analyse von Maschinendaten verwendet?
Antworten:
Eines der am häufigsten verwendeten Analyse-Tools ist Microsoft Excel. Der Nachteil dabei ist, dass Excel nur bis zu 1048576 Zeilen laden kann und die Maschinendaten im Allgemeinen riesig sind. Splunk ist praktisch im Umgang mit maschinengenerierten Daten (Big Data). Die Daten von Servern, Geräten oder Netzwerken können einfach in Splunk geladen und analysiert werden, um zu überprüfen, ob Bedrohungen sichtbar sind, Compliance-Anforderungen erfüllt sind, Sicherheitsprobleme bestehen usw. Sie können auch verwendet werden zur Anwendungsüberwachung.
2. Erklären Sie, wie Splunk funktioniert
Antworten:
Dies sind die häufigsten Splunk-Interviewfragen, die in einem Interview gestellt werden. Daten werden mit dem Forwarder, der als Schnittstelle zwischen der Splunk-Umgebung und der Außenwelt fungiert, in Splunk geladen. Anschließend werden diese Daten an einen Indexer weitergeleitet, in dem die Daten entweder lokal oder in einer Cloud gespeichert werden. Der Indexer indiziert die Maschinendaten und speichert sie auf dem Server. Search Head ist die GUI, die von Splunk zum Suchen und Analysieren (Suchen, Visualisieren, Analysieren und Durchführen verschiedener anderer Funktionen) der Daten bereitgestellt wird.
Der Deployment Server verwaltet alle Komponenten von Splunk wie den Indexer, den Forwarder und den Suchkopf in der Splunk-Umgebung. 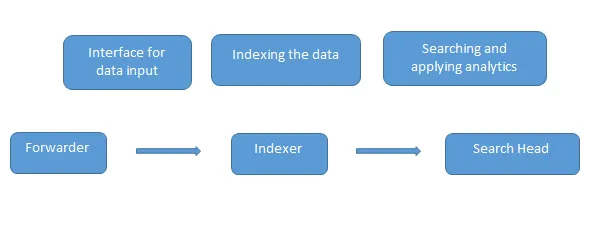
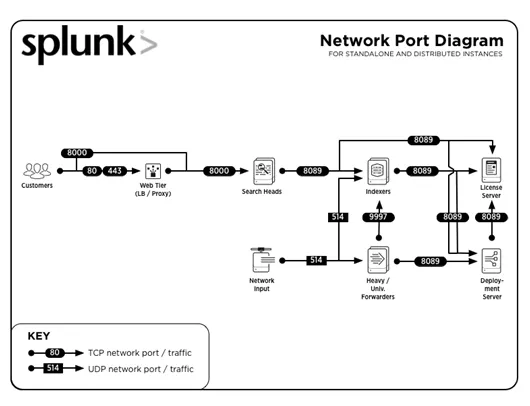
3. Welche allgemeinen Portnummern werden von Splunk verwendet?
Antwort :
Häufige Portnummern, auf denen Dienste ausgeführt werden (standardmäßig):
| Bedienung | Port-Nummer |
| Management / REST API | 8089 |
| Suchkopf / Indexer | 8000 |
| Suchkopf | 8065, 8191 |
| Peerknoten des Indexerclusters / Mitglied des Suchkopfclusters | 9887 |
| Indexer | 9997 |
| Indexer / Weiterleiter | 514 |
Fahren wir mit den nächsten Fragen zum Splunk-Interview fort.
4. Warum nur Splunk verwenden?
Antworten:
Es gibt viele Alternativen für Splunk, die viel Konkurrenz machen. Einige davon sind wie folgt:
• ELK / Logstash (Open Source)
Elasticsearch wird für die Suche verwendet, es ist wie der Suchkopf in Splunk, Log Stash für die Datenerfassung, die dem in Splunk verwendeten Forwarder ähnelt, und Kibana wird für die Datenvisualisierung verwendet (der Suchkopf macht dasselbe in Splunk).
• Graylog (Open Source mit kommerzieller Version)
Graylog ist ein weiteres Tool, das letztes Jahr mit Release 1.0 seinen Namen erhielt. Ähnlich wie ELK Stack hat Graylog auch verschiedene Komponenten, die Elasticsearch als Kernkomponente verwenden, aber die Daten werden in Mongo DB gespeichert und verwenden Apache Kafka. Es gibt zwei Versionen, eine kostenlose Core-Version und eine Enterprise-Version mit Funktionen wie Archivierung.
• Sumo Logic (Cloud-Dienst)
Das Beste an Splunk ist, dass Splunk als einzelnes Paket aus Datenkollektor, Speicher und integriertem Analysetool geliefert wird. Splunk ist auch skalierbar und bietet Support / professionelle Hilfe für die Enterprise Edition.
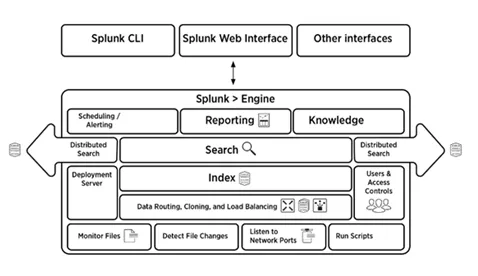
5. Erklären Sie kurz die Splunk-Architektur
Antworten:
Das folgende Bild gibt einen kurzen Überblick über die Splunk-Architektur und ihre Komponenten.
Teil 2 - Fragen zum Splunk-Interview (Fortgeschrittene)
Werfen wir jetzt einen Blick auf die erweiterten Splunk-Interviewfragen.
6. Was sind die Komponenten der Splunk-Architektur?
Antworten:
Die Splunk-Architektur besteht aus vier Komponenten. Sie sind:
- Indexer: Indexiert Maschinendaten
- Weiterleitung: Leitet Protokolle an den Index weiter
- Suchkopf: Bietet eine Benutzeroberfläche für die Suche
- Bereitstellungsserver: Verwaltet die Splunk-Komponenten (Indexer, Weiterleiter und Suchkopf) in einer verteilten Umgebung
7. Nennen Sie einige Anwendungsfälle von Wissensobjekten.
Antwort :
Dies sind die häufig gestellten Fragen zum Splunk-Interview in einem Interview. Wissensobjekte können in vielen Bereichen verwendet werden. Einige Beispiele sind:
Anwendungsüberwachung: Dies kann verwendet werden, um Anwendungen in Echtzeit mit konfigurierten Warnungen zu überwachen, die die Administratoren / Benutzer benachrichtigen, wenn eine Anwendung abstürzt.
Physische Sicherheit: Im Falle einer Überschwemmung / eines Vulkans usw. können die Daten verwendet werden, um Erkenntnisse darüber zu gewinnen, ob Ihre Organisation mit solchen Daten umgeht.
Netzwerksicherheit: Sie können eine sichere Umgebung erstellen, indem Sie die IP-Adresse unbekannter Geräte auf eine schwarze Liste setzen und so Datenlecks in jedem Unternehmen reduzieren.
Mitarbeiterverwaltung: Die Abnutzung von Mitarbeitern ist eine der Herausforderungen, mit denen jedes Unternehmen konfrontiert ist. Während der Kündigungsfrist kann die Aktivität des Mitarbeiters nachverfolgt werden, um die Daten des Unternehmens zu schützen und damit dessen Aktivität zu überwachen .
8. Suchfaktor (SF) und Replikationsfaktor (RF) erklären
Antworten:
Dies sind die Terminologien, die in Splunk-Clustering-Techniken verwendet werden. Der Indexer-Cluster ist eine speziell konfigurierte Gruppe von Splunk Enterprise-Indexern, die externe Daten replizieren und für die Notfallwiederherstellung verwendet werden.
In Bezug auf die Splunk-Dokumentationssuche kann der Faktor wie folgt beschrieben werden: „Die Anzahl durchsuchbarer Kopien von Daten, die ein Indexercluster verwaltet. Der Standardwert für den Suchfaktor ist 2 Zoll, während der Replikationsfaktor als die Anzahl der Kopien der Daten definiert wird, die der Cluster verwaltet.
Der Indexer-Cluster verfügt sowohl über einen Suchfaktor als auch einen Replikationsfaktor, während der Suchkopf-Cluster nur über einen Suchfaktor verfügt
Fahren wir mit den nächsten Fragen zum Splunk-Interview fort.
9. Was sind Splunk-Eimer? Erläutern Sie den Bucket-Lebenszyklus.
Antworten:
Die Verzeichnisse, in denen die indizierten Daten gespeichert sind, werden als Splunk-Buckets bezeichnet und weisen Ereignisse des bestimmten Zeitraums auf. Der Lebenszyklus des Splunk-Eimers umfasst vier Stufen: Heiß, Warm, Kalt, Gefroren und Aufgetaut.
- Hot - Dieser Bucket enthält die kürzlich indizierten Daten und ist zum Schreiben geöffnet.
- Warm - Nachdem die Daten in Abhängigkeit von Ihren Datenrichtlinien in den Hot Bucket gefallen sind, werden sie in Warm-Buckets verschoben
- Kalt - Die nächste Stufe nach Warm ist die Kaltstufe, in der die Daten nicht bearbeitet werden können.
- Eingefroren - Standardmäßig löscht der Indexer die Daten aus eingefrorenen Buckets, diese können jedoch auch archiviert werden.
- Aufgetaut - Das Abrufen von Informationen aus archivierten Dateien (eingefrorener Eimer) wird als Auftauen bezeichnet.
10. Warum sollten wir Splunk Alert verwenden? Welche verschiedenen Optionen stehen beim Einrichten von Warnungen zur Verfügung?
Antworten:
Der Status, nach möglichen Fehlern Ausschau zu halten, wird als Warnung bezeichnet. In Splunk können Umgebungswarnungen aufgrund von Verbindungsfehlern oder Sicherheitsverletzungen oder Verstößen gegen vom Benutzer erstellte Regeln auftreten.
Beispiel: Senden von Benachrichtigungen oder eines Berichts der Benutzer, die sich nach drei Versuchen in einem Portal nicht angemeldet haben, an den Anwendungsadministrator.
Beim Einrichten von Warnmeldungen stehen folgende Optionen zur Verfügung:
- Es kann ein Webhook erstellt werden, um die Warnungen an HipChat oder GitHub zu senden.
- Fügen Sie die Ergebnisse (.csv oder pdf) oder entsprechend dem Nachrichtentext hinzu, damit die Hauptursache der Warnung identifiziert werden kann.
- Tickets können erstellt und Warnungen von einem Computer oder einer IP gedrosselt werden.
Empfohlener Artikel
Dies war ein Leitfaden für die Liste der Fragen und Antworten zu Splunk-Vorstellungsgesprächen, damit der Kandidat diese Fragen und Antworten zu Splunk-Vorstellungsgesprächen auf einfache Weise durchgreifen kann. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Fragen im Vorstellungsgespräch bei SAS System - Die 10 wichtigsten Fragen
- 10 ausgezeichnete Tableau-Interview-Fragen, die Sie kennen müssen
- 15 Fragen und Antworten zu den erfolgreichsten Oracle-Interviews
- Fragen im Vorstellungsgespräch zur Netzwerksicherheit - am häufigsten gestellt
- Splunk gegen Nagios