
Unterschied zwischen Hadoop und Redshift
Hadoop ist ein Open-Source-Framework, das von Apache Software Foundation entwickelt wurde und dessen Hauptvorteile Skalierbarkeit, Zuverlässigkeit und verteiltes Computing sind. Datenverarbeitung, Speicherung, Zugriff und Sicherheit sind verschiedene Arten von Funktionen, die im Hadoop-Ökosystem verfügbar sind. HDFS hat einen hohen Durchsatz, was bedeutet, dass große Datenmengen parallel verarbeitet werden können. Redshift ist ein Cloud-Hosting-Webdienst, der von Amazon Web Services innerhalb von Amazon.com Inc. entwickelt wurde. Es wird zum Entwerfen eines großen Data Warehouse in der Cloud verwendet. Redshift ist ein Data-Warehouse-Service im Petabyte-Bereich, der vollständig verwaltet und kostengünstig für den Betrieb großer Datenmengen ist.
Lasst uns mehr über Hadoop und Redshift im Detail lernen:
Hadoop HDFS verfügt über eine hohe Fehlertoleranz und wurde für den Betrieb auf kostengünstigen Hardwaresystemen entwickelt. Hadoop kann eine minimale Typgröße von TeraBytes bis GigaBytes von Dateien in seinem System verarbeiten. HDFS ist eine Master-Slave-Architektur, die aus Namensknoten und Datenknoten besteht, wobei der Namensknoten Metadaten und der Datenknoten echte Daten enthält, die verarbeitet oder verarbeitet werden sollen.
RedShift verwendet verschiedene Datenladetechniken wie BI-Berichte (Business Intelligence), Analysetools und Data Mining. Redshift bietet eine Konsole zum Erstellen und Verwalten von Amazon Redshift-Clustern. Die Kernkomponente des Redshift Data Warehouse ist ein Cluster.
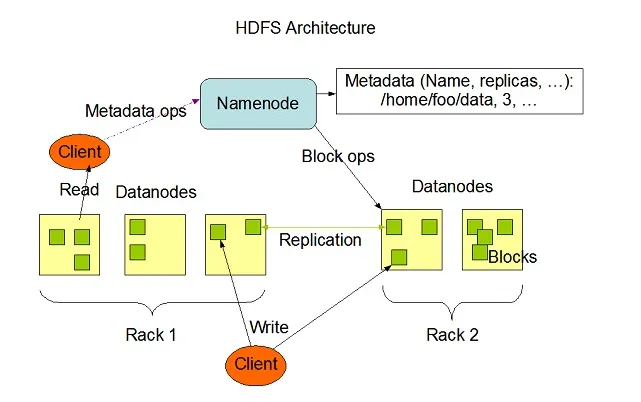
Bildquelle: Apache.org
RedShift-Architektur:
 Bildquelle: Amazon.com
Bildquelle: Amazon.com
Direkter Vergleich zwischen Hadoop und Redshift (Infografik):
Nachfolgend finden Sie die Top-10-Vergleiche zwischen Hadoop und Redshift

Hauptunterschiede zwischen Hadoop und Redshift:
Im Folgenden sind die wichtigsten Unterschiede zwischen Hadoop und Redshift wie folgt
1. Die Hadoop HDFS-Architektur (Hadoop Distributed File System) verfügt über Namensknoten und Datenknoten, wohingegen Redshift über Leader-Knoten und Compute-Knoten verfügt, bei denen Compute-Knoten als Slices partitioniert werden.
2. Hadoop bietet eine Befehlszeilenschnittstelle für die Interaktion mit dem Dateisystem, während RedShift über eine Verwaltungskonsole für die Interaktion mit Amazon-Speicherdiensten wie S3, DynamoDB usw. verfügt.
3.Die Datenbankoperationen müssen von den Entwicklern konfiguriert werden. In Redshift werden die Datenbankoperationen durch Analysieren der Ausführungspläne automatisiert.
4. Hadoop bietet Unterstützung für verschiedene Tools von Drittanbietern, die problemlos integriert werden können, während Redshift nur die von Amazon in seiner Cloud entwickelten Produkte unterstützt.
5. In Bezug auf das Architekturdesign von Hadoop wurden Netzwerk, Speicher, Sicherheit und Leistung als Hauptelemente betrachtet, während diese Elemente in Redshift mithilfe der Amazon Cloud Management Console einfach und flexibel konfiguriert werden können.
6.Hadoop ist eine Dateisystemarchitektur, die auf Java Application Programming Interfaces (API) basiert, während Redshift auf RDBMS (Relational Model Database Management System) basiert.
7. Hadoop kann Integrationen mit verschiedenen Anbietern haben, und Redshift bietet in diesem Fall keine Unterstützung, wenn Amazon der einzige Anbieter ist. Was ist, wenn ein Benutzer mit dem Service unzufrieden ist? In diesem Fall ist Hadoop von Vorteil.
8. Die meisten bestehenden Unternehmen nutzen noch immer Hadoop, während sich Neukunden für RedShift entscheiden.
9. In Bezug auf die Leistung bleibt Hadoop immer zurück und Redshift überzeugt immer bei der Ausführung von Abfragen mit großen Datenmengen.
10. Hadoop verwendet das Map Reduce-Programmiermodell zum Ausführen von Jobs. Amazon Redshift verwendet Amazon Elastic Map Reduce.
11.Hadoop verwendet das Map Reduce-Programmiermodell zum Ausführen von Jobs. Amazon Redshift verwendet Amazon Elastic Map Reduce.
12.Hadoop ist vorzuziehen, um Batch-Jobs täglich auszuführen, die billiger werden, während Redshift im Falle der OLAP-Technologie (Online Analytical Processing), die hinter vielen Business Intelligence-Tools steckt, billiger wird.
13. Hadoop ist 10-mal langsamer als Redshift, wenn Abfragen ausgeführt werden, ähnlich wie Hadoop 10-mal teurer ist als Redshift, was dazu führt, dass Hadoop vor Redshift am wenigsten ausgewählt wird.
14. Auch beim Laden von Daten liegt Hadoop hinter Redshift zurück, wenn das System Stunden benötigt, um Daten aus dem Speicher in sein Dateiverarbeitungssystem zu laden.
15.Hadoop kann für kostengünstige Speicherung, Datenarchivierung, Data Lakes, Data Warehousing und Datenanalyse verwendet werden, wohingegen Redshift unter die Data Warehouse-Funktionen fällt, um die Mehrzwecknutzung einzuschränken.
16. Die Hadoop-Plattform bietet Unterstützung für verschiedene externe Anbieter und ihre eigenen Apache-Projekte wie Storm, Spark, Kafka, Solr usw., und auf der anderen Seite bietet Redshift mit seinen einzigen Amazon-Produkten nur eingeschränkte Integrationsunterstützung
Hadoop vs Redshift Vergleichstabelle
| BASIS FÜR
VERGLEICH | HADOOP | REDSHIFT |
| Verfügbarkeit | Open Source Framework von Apache Projects | Von Amazon bereitgestellte kostenpflichtige Dienste |
| Implementierung | Zur Verfügung gestellt von Hortonworks und Cloudera Anbietern etc., | Entwickelt und bereitgestellt von Amazon |
| Performance | Hadoop MapReduce-Jobs sind langsamer | Redshift ist schneller als Hadoop-Cluster |
| Skalierbarkeit | Einschränkungen bei der Skalierbarkeit | Leicht nach Bedarf verkleinert / vergrößert werden |
| Preisgestaltung | Die Ausführung von Abfragen kostet 200 USD pro Monat | Der Preis hängt von der Serverregion ab und ist billiger als bei Hadoop
ZB: 20 USD / Monat |
| Geschwindigkeit | Schneller aber langsamer als bei Redshift | 10 mal schneller als Hadoop |
| Abfragegeschwindigkeit | Die Ausführung von 1, 2 TB Daten dauert 1491 Sekunden | 155 Sekunden, um 1, 2 TB Daten auszuführen |
| Datenintegration | Flexibel mit lokalem Dateisystem und jeder Datenbank | Kann nur Daten von Amazon S3 oder DynamoDB laden |
| Datei Format | Alle Datenformate werden unterstützt | Streng in Datenformaten wie CSV-Dateiformaten |
| Benutzerfreundlichkeit | Komplexe und schwierigere Verwaltungstätigkeiten | Automatisierte Backup- und Data Warehouse-Verwaltung |
Fazit - Hadoop vs Redshift
Die abschließende Aussage, die den großen Gewinner dieses Vergleichs ausmacht, ist Redshift, das hinsichtlich Benutzerfreundlichkeit, Wartung und Produktivität gewinnt, während Hadoop hinsichtlich der Leistungsskalierbarkeit und der Servicekosten den einzigen Vorteil einer einfachen Integration in Tools von Drittanbietern vermisst und Produkte. Redshift hat sich in letzter Zeit mit einem enormen Wachstum und einer enormen Akzeptanz bei vielen Kunden und Kunden entwickelt, da es im Vergleich zu Hadoop aufgrund seiner hohen Verfügbarkeit und geringeren Betriebskosten immer beliebter wird. Bisher verwendeten die meisten Fortune 1000-Unternehmen Hadoop-Plattformen in ihren Architekturen, um die Kundendaten zu verwalten.
In den meisten Fällen erwies sich RedShift als die beste Wahl für geschäftliche Zwecke eines Kunden oder Kunden, um die großen und vertraulichen Daten von Finanzinstituten oder öffentlichen Informationen mit größerer Datenintegrität und -sicherheit zu verarbeiten.
Abgesehen davon hat Hadoop seine eigenen Vorteile als Open-Source-Projekt und war über viele Jahre verfügbar, was auch dazu führte, dass die vorhandenen Systeme als kostenintensiver Prozess ersetzt wurden. Das Produkt sollte letztendlich auf der Grundlage der Anforderungen und der Flexibilität ausgewählt werden und nicht auf der Grundlage der Preisgestaltung oder der Popularität, die auf den betriebswirtschaftlichen Anforderungen basiert.
Empfohlener Artikel:
Dies war ein Leitfaden für Hadoop vs Redshift, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Hadoop vs Hive - Finde die besten Unterschiede heraus
- HADOOP vs RDBMS | Kennen Sie die 12 nützlichen Unterschiede
- Apache Hadoop gegen Apache Spark | Top 10 Vergleiche, die Sie kennen müssen!
- Big Data vs Data Science - Wie unterscheiden sie sich?
- Leitfaden für Hadoop vs Spark
- Top 4 Cloud-Hosting-Anbieter mit Funktionen