
Unterschiede zwischen Data Scientist und Machine Learning
Ein Data Scientist ist ein Experte, der dafür verantwortlich ist, große Datenmengen zu sammeln, zu untersuchen und zu interpretieren, um Möglichkeiten zu erkennen, mit denen ein Unternehmen seine Abläufe verbessern und einen Vorteil gegenüber Wettbewerbern erzielen kann. Es folgt einem interdisziplinären Ansatz. Es liegt zwischen der Verbindung von Mathematik, Statistik, Software-Engineering, künstlicher Intelligenz und Design Thinking. Es befasst sich mit Datenerfassung, Bereinigung, Analyse, Visualisierung, Validierungsmodell, Vorhersage von Experimenten, Entwerfen, Testen und Hypothesen. Maschinelles Lernen ist eine Abteilung für künstliche Intelligenz, die von der Datenwissenschaft genutzt wird, um ihre Ziele zu erreichen. Das maschinelle Lernen konzentriert sich hauptsächlich auf Algorithmen, Polynomstrukturen und das Hinzufügen von Wörtern. Es besteht aus einer Gruppe von Algorithmen und Maschinen, die es ihnen ermöglichen, zu lernen, ohne eindeutig dafür programmiert zu sein.
Datenwissenschaftler
Diese Rolle als Data Scientist ist ein Zweig der Statistik, der die Verwendung von Analysetechnologien der fortgeschrittenen Version, einschließlich maschinellem Lernen und prädiktiver Modellierung, umfasst, um Visionen zu liefern, die über die statistische Analyse hinausgehen. Die Petition für datenwissenschaftliche Fähigkeiten ist in den letzten Jahren erheblich gewachsen, da Unternehmen nützliche Informationen aus den riesigen Mengen strukturierter, halbstrukturierter und unstrukturierter Daten sammeln möchten, die ein großes Unternehmen produziert und als Big Data bezeichnet. Ziel aller Schritte ist es, Erkenntnisse nur aus Daten abzuleiten.
Standardaufgaben:
- Allokieren, aggregieren und synthetisieren Sie Daten aus verschiedenen strukturierten und unstrukturierten Quellen
- Intelligentes Lernen erforschen, entwickeln und auf reale Daten anwenden, wichtige Erkenntnisse liefern und darauf aufbauend erfolgreiche Maßnahmen ergreifen
- Analysieren und Bereitstellen von in der Organisation gesammelten Daten
- Entwerfen und erstellen Sie neue Prozesse für Modellierung, Data Mining und Implementierung
- Entwickeln Sie Prototypen, Algorithmen, Vorhersagemodelle und Prototypen
- Führen Sie Anfragen zur Datenanalyse durch und teilen Sie deren Ergebnisse und Entscheidungen mit
Darüber hinaus gibt es abhängig von der Domäne, in der der Arbeitgeber arbeitet oder in der das Projekt durchgeführt wird, spezifischere Aufgaben.
Rohdaten -> Data Science -> umsetzbare Erkenntnisse
Maschinelles Lernen
Die Position des Machine Learning Engineer ist eher „technisch“. ML Engineer hat mehr mit klassischem Software Engineering gemein als Data Scientist. Es hilft Ihnen, die Zielfunktion zu erlernen, die die Eingaben für die Zielvariable und / oder unabhängige Variablen für die abhängigen Variablen darstellt.
Die Standardaufgaben von ML Engineer sind im Allgemeinen wie Data Scientist. Sie müssen auch in der Lage sein, mit Daten zu arbeiten, mit verschiedenen Algorithmen für maschinelles Lernen zu experimentieren, um die Aufgabe zu lösen, Prototypen zu erstellen und vorgefertigte Lösungen zu finden.
Die für diese Position erforderlichen Kenntnisse und Fähigkeiten überschneiden sich auch mit Data Scientist. Von den Hauptunterschieden würde ich herausgreifen:
- Gute Programmierkenntnisse in einer oder mehreren gängigen Sprachen (in der Regel Python und Java) sowie in Datenbanken;
- Weniger Wert auf die Fähigkeit, in Datenanalyseumgebungen zu arbeiten, sondern mehr auf Algorithmen für maschinelles Lernen;
- R und Python sind für die Modellierung Matlab, SPSS und SAS vorzuziehen.
- Möglichkeit, vorgefertigte Bibliotheken für verschiedene Stapel in der Anwendung zu verwenden, z. B. Mahout, Lucene für Java, NumPy / SciPy für Python;
- Möglichkeit zum Erstellen verteilter Anwendungen mit Hadoop und anderen Lösungen.
Wie Sie sehen, erfordert die Position des ML Engineer (oder einer engeren Position) mehr Kenntnisse im Bereich Software Engineering und ist dementsprechend gut für erfahrene Entwickler geeignet. Sehr oft funktioniert der Fall, wenn der übliche Entwickler die ML-Aufgabe für seine Aufgabe lösen muss und beginnt, die erforderlichen Algorithmen und Bibliotheken zu verstehen.
Head to Head Vergleich zwischen Data Scientist und Machine Learning
Nachfolgend sind die fünf wichtigsten Unterschiede zwischen Data Scientist und Machine Learning Engineer aufgeführt 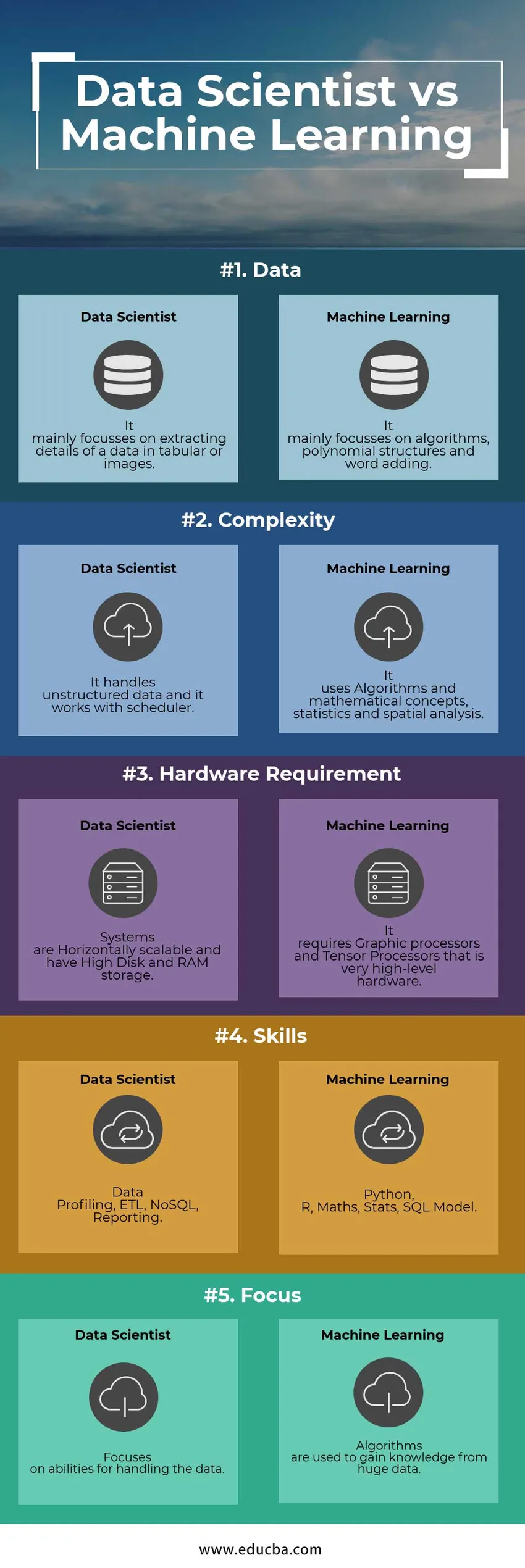
Hauptunterschied zwischen Data Scientist und Machine Learning
Nachstehend finden Sie eine Liste der Punkte, in denen die wichtigsten Unterschiede zwischen Data Scientist und Machine Learning Engineer beschrieben sind
- Maschinelles Lernen und Statistik sind Teil der Datenwissenschaft. Das Wort Lernen beim maschinellen Lernen bedeutet, dass die Algorithmen von einigen Daten abhängen, die als Trainingssatz verwendet werden, um einige Modell- oder Algorithmusparameter zu optimieren. Dies umfasst viele Techniken wie Regression, naives Bayes oder überwachtes Clustering. Aber nicht alle Techniken passen in diese Kategorie. Beispielsweise zielt das unbeaufsichtigte Clustering - eine statistische und datenwissenschaftliche Technik - darauf ab, Cluster und Clusterstrukturen ohne Vorkenntnisse oder Trainingssätze zu erkennen, die den Klassifizierungsalgorithmus unterstützen. Ein Mensch wird benötigt, um die gefundenen Cluster zu kennzeichnen. Einige Techniken sind hybride Techniken, z. B. die halbüberwachte Klassifizierung. Einige Mustererkennungs- oder Dichteschätzungsverfahren passen in diese Kategorie.
- Data Science ist jedoch viel mehr als maschinelles Lernen. Daten in der Datenwissenschaft können aus einer Maschine oder einem mechanischen Prozess stammen oder auch nicht (Umfragedaten könnten manuell erfasst werden, klinische Studien beinhalten eine bestimmte Art von kleinen Daten) und sie haben möglicherweise nichts mit Lernen zu tun, wie ich gerade besprochen habe. Der Hauptunterschied ist jedoch die Tatsache, dass die Datenwissenschaft das gesamte Spektrum der Datenverarbeitung abdeckt, nicht nur die algorithmischen oder statistischen Aspekte. Data Science umfasst auch Datenintegration, verteilte Architektur, automatisiertes maschinelles Lernen, Datenvisualisierung, Dashboards und Big Data Engineering.
Data Scientist vs Machine Learning Vergleichstabelle
Im Folgenden sind die Punktelisten aufgeführt, die die Vergleiche zwischen Data Scientist und Machine Learning Engineer beschreiben:
| Feature | Datenwissenschaftler | Maschinelles Lernen |
| Daten | Es konzentriert sich hauptsächlich auf das Extrahieren von Details von Daten in Tabellen oder Bildern | Es konzentriert sich hauptsächlich auf Algorithmen, Polynomstrukturen und das Hinzufügen von Wörtern |
| Komplexität | Es verarbeitet unstrukturierte Daten und arbeitet mit dem Scheduler | Es verwendet Algorithmen und mathematische Konzepte, Statistiken und räumliche Analysen |
| Hardware-Anforderung | Systeme sind horizontal skalierbar und verfügen über High Disk- und RAM-Speicher | Es werden Grafikprozessoren und Tensor-Prozessoren benötigt, die eine sehr hochwertige Hardware darstellen |
| Kompetenzen | Datenprofilerstellung, ETL, NoSQL, Berichterstellung | Python, R, Mathematik, Statistik, SQL-Modell |
| Fokus | Konzentriert sich auf die Fähigkeiten zum Umgang mit den Daten | Algorithmen werden verwendet, um Wissen aus riesigen Datenmengen zu gewinnen |
Fazit - Data Scientist vs. Machine Learning
Durch maschinelles Lernen lernen Sie die Zielfunktion, mit der die Eingaben für die Zielvariable und / oder unabhängige Variablen für die abhängigen Variablen aufgezeichnet werden
Ein Data Scientist untersucht Daten sehr genau und gelangt zu der umfassenden Strategie, wie er sie angehen soll. Er ist dafür verantwortlich, Fragen innerhalb der Daten zu stellen und herauszufinden, welche Antworten man vernünftigerweise aus Daten ziehen kann. Feature Engineering gehört zum Bereich Data Scientist. Kreativität spielt auch hier eine Rolle, und ein Ingenieur für maschinelles Lernen kennt mehr Werkzeuge und kann Modelle mit einer Reihe von Funktionen und Daten erstellen - gemäß den Anweisungen des Data Scientist. Der Bereich Datenvorverarbeitung und Feature-Extraktion gehört ML Engineer.
Datenwissenschaft und -prüfung verwenden maschinelles Lernen für diese Art der archetypischen Validierung und Erstellung. Es ist wichtig zu beachten, dass nicht alle Algorithmen in dieser Modellerstellung aus maschinellem Lernen stammen. Sie können aus zahlreichen anderen Bereichen ankommen. Das Modell möchte immer aktuell gehalten werden. Wenn sich die Situationen ändern, wird das Modell, das wir zuvor erstellt haben, möglicherweise unwichtig. Die Modellanforderungen müssen zu verschiedenen Zeitpunkten auf ihre Gewissheit überprüft und angepasst werden, wenn sich ihre Gewissheit verringert.
Die Datenwissenschaft ist eine große Domäne. Wenn wir versuchen, es in eine Pipeline zu bringen, würde es Datenerfassung, Datenspeicherung, Datenvorverarbeitung oder Datenbereinigung, Lernmuster in Daten (über maschinelles Lernen) und Lernen für Vorhersagen beinhalten. Dies ist eine Möglichkeit zu verstehen, wie maschinelles Lernen in die Datenwissenschaft passt.
Empfohlener Artikel
Dies war ein Leitfaden für die Unterschiede zwischen Data Scientist und Machine Learning Engineer, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Data Mining vs Maschinelles Lernen - 10 Dinge, die Sie wissen müssen
- Maschinelles Lernen vs Predictive Analytics - 7 nützliche Unterschiede
- Data Scientist vs Business Analyst - Finden Sie die 5 großartigen Unterschiede heraus
- Data Scientist vs Data Engineer - 7 erstaunliche Vergleiche
- Im Vorstellungsgespräch bei Software Engineering | Top und am meisten gefragt