

Unterschied zwischen Hadoop und HBase
Hadoop ist ein Open-Source-Java-Framework, das zum Verwalten und Verarbeiten einer großen Menge strukturierter und unstrukturierter Daten verwendet wird. Hadoop ist massiv skalierbar und wird daher zur Verarbeitung von Big-Data-Workloads verwendet. Big Data wird auf dem zuverlässigen und erweiterbaren Cluster gespeichert, abgerufen und verarbeitet. HBase (Hadoop Database) ist eine nicht relationale und nicht nur SQL-fähige NoSQL-Datenbank, die als verteilter und skalierbarer Big Data Store auf Hadoop ausgeführt wird. Es ist eine Open-Source-Datenbank, in der Daten in Form von Zeilen und Spalten gespeichert werden. In dieser Zelle befindet sich eine Schnittmenge von Spalten und Zeilen.
Nachfolgend sind die Kernkomponenten der Hadoop-Architektur aufgeführt:
- Hadoop Distributed File System (HDFS): Hadoop enthält ein verteiltes Speichersystem, das Hadoop Distributed File System (HDFS). HDFS ist die Master-Slave-Architektur, die Daten im gesamten Cluster speichert. Daten, die vom Masterknoten im Formularblock auf mehrere Slave-Knoten verteilt werden. Der Master-Knoten heißt Namenode und die Slave-Knoten heißen Datanode. HDFS ist leicht erweiterbar und speichert eine große Datenmenge auf Datanodes. HDFS verfügt über einen konfigurierbaren Replikationsfaktor mit dem Standardwert 3, der bearbeitet werden kann.
- MapReduce: MapReduce ist ein Programmierparadigma, das auf einer großen Anzahl von Datensätzen über das Netzwerk parallel verarbeitet wird. MapReduce bezieht sich auf zwei verschiedene Aufgaben: Zuordnen der Eingabedaten, in denen Daten in eine Teilmenge von Daten unterteilt sind, die als Tupel bezeichnet werden, und Reduzieren der Aufgabe, wobei diese Tupel aus der Karte als Eingabe übernommen und zur Ausgabe des Originals kombiniert werden.
- Yarn: YARN steht für einen weiteren Ressourcennavigator, der Ressourcen wie CPU und Speicher verwaltet und Ressourcenanforderungen plant.
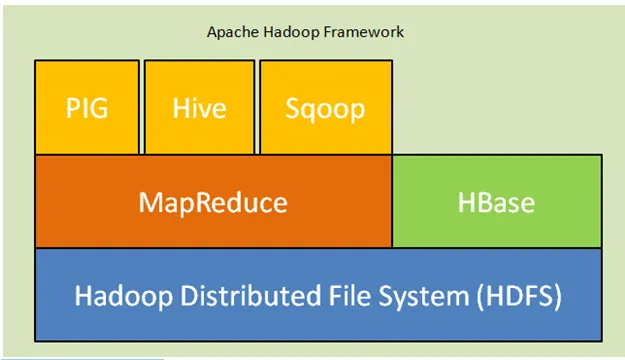
Abb. Apache Hadoop Framework
Der Regionsserver stellt Daten für Lese- / Schreibvorgänge bereit. Alle HBase-Daten werden in der HDFS-Datei gespeichert. Der HDFS-Datenknoten speichert die Daten, die der Regionsserver verwaltet. Der HDFS-Namenode speichert Metadateninformationen für alle physischen Datenblöcke, aus denen die Dateien bestehen.
Die Versionierung wird zum Nachverfolgen von Zellenänderungen verwendet, wodurch die Version des Inhalts nachverfolgt wird. Daraus kann jede Version von Inhalten abgerufen werden. Jeder Zellenwert enthält das Attribut 'version' in Bezug auf den Zeitstempel zum Abrufen der Zelle. Jeder Wert in der Map ist ein ununterbrochenes Array von Bytes. Die Karte wird durch einen Zeilenschlüssel, einen Spaltenschlüssel und einen Zeitstempel indiziert. Die Architektur von HBase ist hoch skalierbar, spärlich, verteilt, beständig und mehrdimensional sortiert.
Head to Head Vergleich zwischen Hadoop und HBase (Infografik)
Unten ist der Top 7 Unterschied zwischen Hadoop und HBase
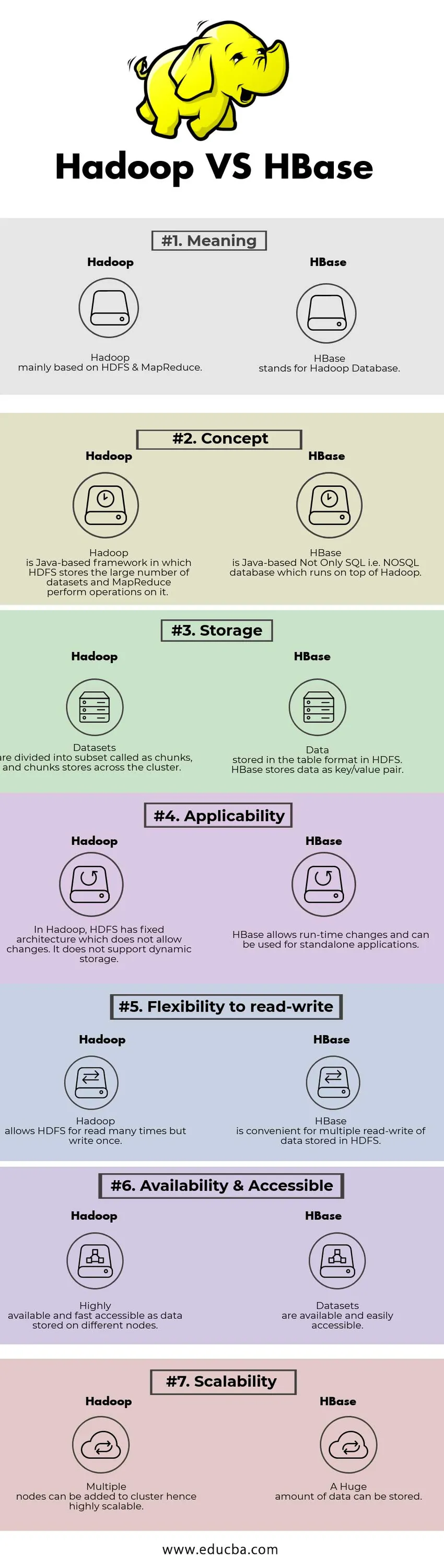
Hauptunterschiede zwischen Hadoop und HBase
Der Unterschied zwischen Hadoop und HBase wird in den folgenden Punkten erläutert:
- Hadoop ist nicht für die Online-Analyseverarbeitung (OLAP) geeignet, und HBase ist Teil des Hadoop-Ökosystems, das einen zufälligen Echtzeitzugriff (Lesen / Schreiben) auf Daten im Hadoop-Dateisystem bietet.
- Das Hadoop-Framework ist fehlertolerant und unterstützt die schnelle Datenübertragung zwischen Knoten, auch bei Systemausfällen. HBase ist eine nicht relationale und Open-Source-Nicht-Nur-SQL-Datenbank, die auf Hadoop ausgeführt wird. HBase fällt unter den CP-Typ des CAP-Theorems (Consistency, Availability, Partition Tolerance).
- Hadoop eignet sich am besten für die Durchführung von Batch-Analysen. Einer der größten Nachteile ist jedoch die Unfähigkeit, Echtzeitanalysen durchzuführen, was der Trend der IT-Branche ist. HBase hingegen kann mit großen Datenmengen umgehen und ist für die Stapelanalyse nicht geeignet. Stattdessen werden Daten von Hadoop in Echtzeit geschrieben / gelesen.
- Sowohl Hadoop als auch HBase können strukturierte, halbstrukturierte und unstrukturierte Daten verarbeiten. In Hadoop fehlt HDFS eine In-Memory-Prozessor-Engine, die den Prozess der Datenanalyse verlangsamt. wie es mit einfachen alten MapReduce ist, um es zu tun. Im Gegensatz dazu verfügt HBase über eine In-Memory-Prozessor-Engine, die die Lese- / Schreibgeschwindigkeit drastisch erhöht.
- Hadoop führt die Datenanalyse sehr transparent durch. HBase hingegen, eine NoSQL-Datenbank im Tabellenformat, ruft Werte ab, indem sie nach verschiedenen Schlüsselwerten sortiert werden.
Hadoop vs HBase Vergleichstabelle
| VERGLEICHSGRUNDLAGE | Hadoop | HBase |
| Bedeutung | Hadoop basiert hauptsächlich auf HDFS & MapReduce. | HBase steht für Hadoop Database. |
| Konzept | Hadoop ist ein Java-basiertes Framework, in dem HDFS die große Anzahl von Datensätzen speichert und MapReduce Vorgänge darauf ausführt. | HBase ist eine Java-basierte Nicht-Nur-SQL-Datenbank, dh eine NoSQL-Datenbank, die auf Hadoop läuft. |
| Lager | Datasets werden in Teilmengen unterteilt, die als Chunks bezeichnet werden, und Chunks werden im gesamten Cluster gespeichert. | In HDFS im Tabellenformat gespeicherte Daten. HBase speichert Daten als Schlüssel / Wert-Paar. |
| Anwendbarkeit | In Hadoop verfügt HDFS über eine feste Architektur, die keine Änderungen zulässt. Dynamische Speicherung wird nicht unterstützt. | HBase ermöglicht Laufzeitänderungen und kann für eigenständige Anwendungen verwendet werden. |
| Flexibilität zum Lesen und Schreiben | Mit Hadoop kann HDFS viele Male gelesen, aber nur einmal geschrieben werden. | HBase ist praktisch für das mehrfache Lesen und Schreiben von in HDFS gespeicherten Daten |
| Verfügbarkeit und Erreichbarkeit | Hochverfügbar und schnell verfügbar, da Daten auf verschiedenen Knoten gespeichert sind. | Datensätze sind verfügbar und leicht zugänglich |
| Skalierbarkeit | Mehrere Knoten können zu einem Cluster hinzugefügt werden, wodurch eine hohe Skalierbarkeit erzielt wird. | Eine große Datenmenge kann gespeichert werden. |
Fazit - Hadoop vs HBase
Hadoop-Architektur, die hauptsächlich auf HDFS und MapReduce basiert. HBase ist die unterstützende Komponente im Hadoop-System. HBase ist in der Lage, riesige Tabellen zu hosten und schnellen wahlfreien Zugriff auf verfügbare Daten zu ermöglichen, während HDFS zum Speichern großer Dateien geeignet ist. Sowohl Hadoop als auch HBase bieten einen schnellen Zugriff auf Daten, aber mit HBase können Lese- / Schreibvorgänge ausgeführt und für HDFS mehrere Male gelesen und einmal geschrieben werden. In diesem Artikel wurde ein Verständnis von Hadoop und HBase beschrieben, Funktionen kurz hervorgehoben und mit Bedacht verglichen.
Empfohlener Artikel
- Apache Hadoop gegen Apache Spark | Top 10 Vergleiche, die Sie kennen müssen!
- Hadoop vs Hive - Finde die besten Unterschiede heraus
- HBase vs Cassandra - Welches ist besser (Infografik)
- Top 12 Vergleich von Apache HBase vs Apache Hive (Infographics)
- Hadoop vs Spark: Was sind die Funktionen