

Einführung in Data Mining-Methoden
Die Datenmenge steigt täglich enorm an. Aber alle gesammelten oder gesammelten Daten sind nicht nützlich. Bedeutungsvolle Daten müssen von verrauschten Daten (bedeutungslosen Daten) getrennt werden. Dieser Prozess der Trennung erfolgt durch Data Mining.
Was ist Data Mining?
Beim Data Mining werden nützliche Informationen oder Kenntnisse aus einer enormen Datenmenge (oder Big Data) extrahiert. Die Lücke zwischen Daten und Informationen wurde mithilfe verschiedener Data Mining-Tools verringert. Data Mining kann auch als Wissenserkennung aus Daten oder KDD bezeichnet werden .
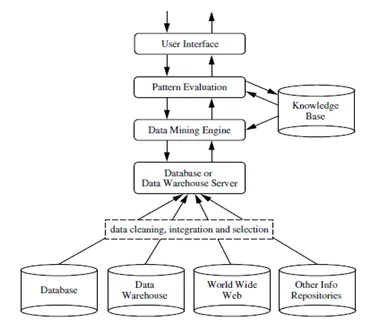
Quellen: - www.ques10.com
Data Mining kann für verschiedene Arten von Datenbanken und Informationsrepositorys wie relationale Datenbanken, Data Warehouses, Transaktionsdatenbanken, Datenströme und vieles mehr durchgeführt werden.
Verschiedene Data Mining-Methoden:
Für das Data Mining werden viele Methoden verwendet. Der entscheidende Schritt besteht jedoch darin, die geeignete Methode entsprechend dem Unternehmen oder der Problemstellung auszuwählen. Mithilfe dieser Data Mining-Methoden können Sie die Zukunft vorhersagen und entsprechende Entscheidungen treffen. Diese helfen auch bei der Analyse des Markttrends und bei der Steigerung des Unternehmensumsatzes.
Einige Data Mining-Methoden sind:
- Verband
- Einstufung
- Clusteranalyse
- Prognose
- Sequentielle Muster oder Musterverfolgung
- Entscheidungsbäume
- Ausreißeranalyse oder Anomalieanalyse
- Neurales Netzwerk
Lassen Sie uns nacheinander alle Data Mining-Methoden verstehen.
1. Verein:
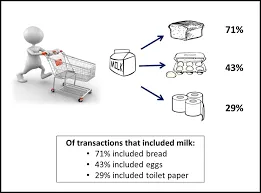
Es ist eine Methode, um eine Korrelation zwischen zwei oder mehr Elementen zu finden, indem das verborgene Muster im Datensatz identifiziert und daher auch als Beziehungsanalyse bezeichnet wird . Diese Methode wird in der Warenkorbanalyse verwendet, um das Verhalten des Kunden vorherzusagen.
Angenommen, der Marketingleiter eines Supermarkts möchte bestimmen, welche Produkte häufig zusammen gekauft werden.
Als Beispiel,
Kauft (x, "Bier") -> Kauft (x, "Pommes") (Unterstützung = 1%, Vertrauen = 50%)
- Hier steht x für einen Kunden, der Bier und Pommes zusammen kauft.
- Das Vertrauen zeigt die Gewissheit, dass ein Kunde, der ein Bier kauft, mit einer Wahrscheinlichkeit von 50% auch die Chips kauft.
- Unterstützung bedeutet, dass 1% aller untersuchten Transaktionen zeigten, dass Bier und Pommes zusammen gekauft wurden.
Viele ähnliche Beispiele wie Brot und Butter oder Computer und Software können in Betracht gezogen werden.
Es gibt zwei Arten von Zuordnungsregeln:
- Eindimensionale Zuordnungsregel: Diese Regeln enthalten ein einzelnes Attribut, das wiederholt wird.
- Mehrdimensionale Zuordnungsregel: Diese Regeln enthalten mehrere Attribute, die wiederholt werden.
https://bit.ly/2N61gzR
2. Klassifizierung:
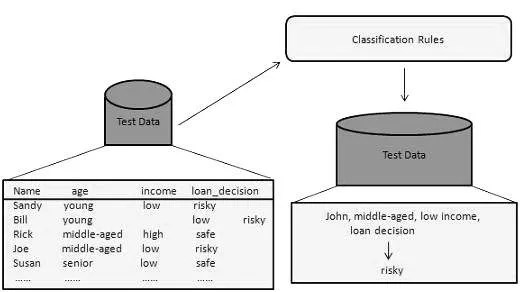
Mit dieser Data Mining-Methode werden die Elemente in den Datensätzen in Klassen oder Gruppen unterteilt. Es hilft, das Verhalten von Elementen innerhalb der Gruppe genau vorherzusagen. Es ist ein zweistufiger Prozess:
- Lernschritt (Trainingsphase): Hierbei baut ein Klassifikationsalgorithmus den Klassifikator auf, indem er einen Trainingssatz analysiert.
- Klassifizierungsschritt: Testdaten werden verwendet, um die Genauigkeit oder Präzision der Klassifizierungsregeln abzuschätzen.
Beispielsweise identifiziert ein Bankunternehmen Kreditantragsteller mit niedrigem, mittlerem oder hohem Kreditrisiko. Ebenso analysiert ein medizinischer Forscher Krebsdaten, um vorherzusagen, welches Arzneimittel dem Patienten verschrieben werden soll.
Quellen: - www.tutorialspoint.com
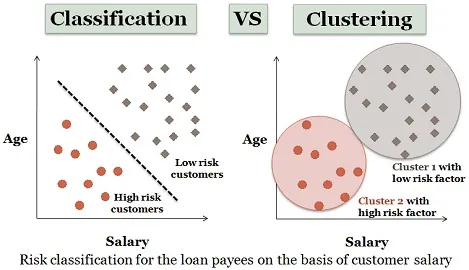
3. Clusteranalyse:
Clustering ähnelt fast der Klassifizierung, wird jedoch in diesem Cluster in Abhängigkeit von den Ähnlichkeiten der Datenelemente erstellt. Verschiedene Cluster haben unterschiedliche oder nicht verwandte Objekte. Es wird auch als Datensegmentierung bezeichnet, da große Datenmengen entsprechend der Ähnlichkeiten in Cluster aufgeteilt werden.
Es werden verschiedene Clustering-Methoden verwendet:
- Hierarchische agglomerative Methoden
- Gitterbasierte Methoden
- Partitionierungsmethoden
- Modellbasierte Methoden
- Dichtebasierte Methoden
Ein ähnliches Beispiel für Kreditantragsteller kann auch hier betrachtet werden. Es gibt einige Unterschiede, die in der folgenden Abbildung dargestellt sind.
https://bit.ly/2N6aZpP
4. Vorhersage:
Diese Methode wird verwendet, um die Zukunft basierend auf vergangenen und gegenwärtigen Trends oder Datensätzen vorherzusagen. Die Vorhersage wird hauptsächlich in Kombination mit anderen Data-Mining-Methoden wie Klassifizierung, Musterabgleich, Trendanalyse und Beziehung verwendet.
Zum Beispiel, wenn der Verkaufsleiter eines Supermarkts die Höhe der Einnahmen vorhersagen möchte, die jeder Artikel auf der Grundlage vergangener Verkaufsdaten erzielen würde. Es modelliert eine stetig bewertete Funktion, die fehlende numerische Datenwerte vorhersagt.

Quellen: - data-mining.philippe-fournier
Die Regressionsanalyse ist die beste Wahl für die Vorhersage. Es kann verwendet werden, um eine Beziehung zwischen unabhängigen Variablen und abhängigen Variablen festzulegen.
5. Sequentielle Muster oder Musterverfolgung:
Mit dieser Data Mining-Methode werden Muster identifiziert, die über einen bestimmten Zeitraum häufig auftreten.
Zum Beispiel sieht der Verkaufsleiter der Bekleidungsfirma, dass der Verkauf von Jacken kurz vor der Wintersaison zuzunehmen scheint oder der Verkauf von Backwaren zu Weihnachten oder Silvester zuzunehmen scheint.
Schauen wir uns ein Beispiel mit einer Grafik an
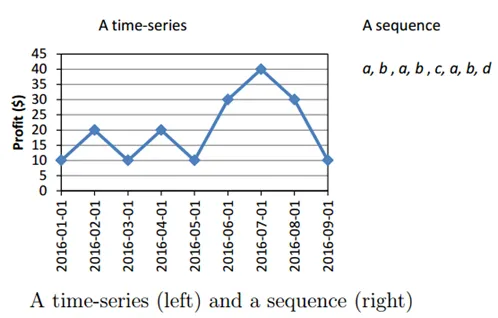
Quellen: - data-mining.philippe-fournier-viger
Bäume 6.Decision:
Ein Entscheidungsbaum ist eine Baumstruktur (wie der Name schon sagt), in der
- Jeder interne Knoten repräsentiert einen Test für das Attribut.
- Zweig bezeichnet das Ergebnis des Tests.
- Terminalknoten enthalten die Klassenbezeichnung.
- Der oberste Knoten ist der Wurzelknoten mit der einfachen Frage, die zwei oder mehr Antworten enthält. Dementsprechend wächst der Baum und es wird eine flussdiagrammartige Struktur erzeugt.
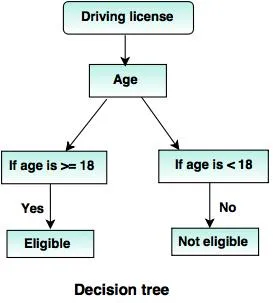
Quellen: - www.tutorialride.com
In dieser Entscheidung klassifiziert die Baumregierung Bürger unter 18 Jahren oder über 18 Jahren. Dies würde ihnen helfen, zu entscheiden, ob eine Lizenz für einen bestimmten Bürger ausgestellt werden muss oder nicht.
7. Frühere Analyse oder Anomalie-Analyse:
Mit dieser Data Mining-Methode werden die Datenelemente identifiziert, die nicht dem erwarteten Muster oder dem erwarteten Verhalten entsprechen. Diese unerwarteten Datenelemente werden als Ausreißer oder Rauschen betrachtet. Sie sind in vielen Bereichen hilfreich, z. B. bei der Erkennung von Kreditkartenbetrug, der Erkennung von Eindringlingen und Fehlern. Dies wird auch als Outlier Mining bezeichnet .
Nehmen wir zum Beispiel an, dass die folgende Grafik anhand einiger Datensätze in unserer Datenbank dargestellt wird.
So wird die am besten passende Linie gezogen. Die in der Nähe der Linie liegenden Punkte zeigen das erwartete Verhalten, während der von der Linie entfernte Punkt ein Ausreißer ist.
Dies würde helfen, die Anomalien zu erkennen und mögliche Maßnahmen entsprechend zu ergreifen.
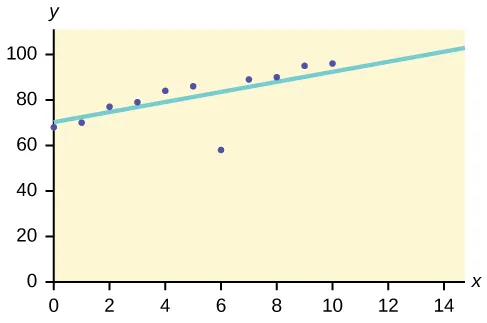
https://bit.ly/2GrgjDP
8. Neuronales Netzwerk:
Dieses Data Mining-Verfahren oder -Modell basiert auf biologischen neuronalen Netzen. Es ist eine Ansammlung von Neuronen wie Verarbeitungseinheiten mit gewichteten Verbindungen zwischen ihnen. Sie dienen zur Modellierung der Beziehung zwischen Ein- und Ausgängen. Es wird zur Klassifizierung, Regressionsanalyse, Datenverarbeitung usw. verwendet. Diese Technik basiert auf drei Säulen:
- Modell
- Lernalgorithmus (überwacht oder unbeaufsichtigt)
- Aktivierungsfunktion
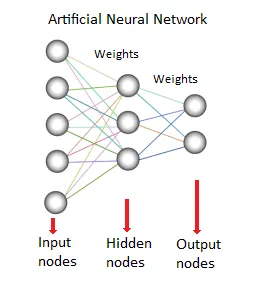
Quellen: - www.saedsayad.com
Empfohlene Artikel
Dies war ein Leitfaden für Data Mining-Methoden. Hier haben wir am Beispiel Was ist Data Mining und verschiedene Arten von Data Mining-Methoden erläutert. Sie können sich auch die folgenden Artikel ansehen, um mehr zu erfahren -
- Big Data Analytics-Software
- Fragen im Vorstellungsgespräch zur Datenstruktur
- Wichtige Data Mining-Techniken
- Data Mining-Architektur