

Unterschiede zwischen Sqoop und Flume
Sqoop ist ein Produkt der Apache-Software. Sqoop extrahiert nützliche Informationen aus Hadoop und leitet sie an die externen Datenspeicher weiter. Mit Hilfe von Sqoop können wir Daten von einem RDBMS oder Mainframe in HDFS importieren. Flume ist auch von Apache-Software. Es sammelt und verschiebt die generierten rekursiven Daten. Der Apache Flume ist nicht nur auf die Protokolldatenaggregation beschränkt, sondern die Datenquellen sind anpassbar, sodass Flume zum Transport großer Datenmengen verwendet werden kann. Das Sammeln, Aggregieren und Verschieben großer Datenmengen zwischen dem Hadoop Distributed File System und RDBMS erfolgt am besten mit Tools wie Sqoop oder Flume.
Lassen Sie uns diese beiden häufig verwendeten Tools für den oben genannten Zweck diskutieren.
Was ist Sqoop?
Um Sqoop zu verwenden, muss ein Benutzer das zu verwendende Tool und die Argumente angeben, die das jeweilige Tool steuern. Sie können die Daten dann auch mit Sqoop wieder in ein RDBMS exportieren. Die Exportfunktion von Sqoop wird verwendet, um nützliche Informationen aus Hadoop zu extrahieren und in die externen strukturierten Datenspeicher zu exportieren. Es funktioniert mit verschiedenen Datenbanken wie Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Architektur: -
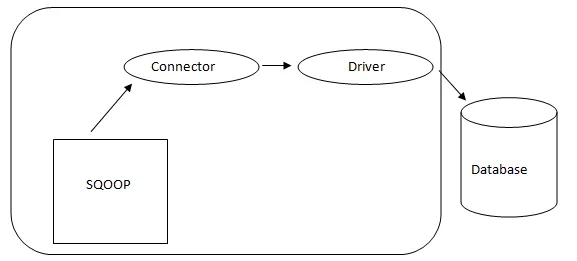
Architektur von Sqoop
Der Connector in einem Sqoop ist ein Plug-in für eine bestimmte Datenbankquelle. Daher ist es von grundlegender Bedeutung, dass es sich um eine Sqoop-Einrichtung handelt. Trotz der Tatsache, dass Treiber datenbankspezifische Komponenten sind und von verschiedenen Datenbankanbietern vertrieben werden, wird Sqoop selbst mit verschiedenen Arten von Konnektoren ausgeliefert, die für das gängige Datenbank- und Information-Warehousing-System verwendet werden. Daher wird Sqoop auch mit einer gemischten Auswahl an Steckverbindern ausgeliefert. Sqoop bietet eine steckbare Komponente für ein ideales Netzwerk und ein externes System. Die Sqoop-API bietet eine hilfreiche Struktur zum Zusammenstellen neuer Connectors. Daher können alle Datenbankconnectors in die Sqoop-Installation eingefügt werden, um die Konnektivität für verschiedene Datensysteme zu gewährleisten.
Was ist Gerinne?
Der Apache Flume ist nicht nur auf die Aggregation von Protokolldaten beschränkt, sondern die Datenquellen sind anpassbar. Somit kann Flume zum Transport großer Datenmengen verwendet werden, einschließlich, aber nicht beschränkt auf E-Mail-Nachrichten, von sozialen Medien generierte Daten, Netzwerkverkehrsdaten und so ziemlich alle Datenquelle möglich.
Ablaufarchitektur: - Die Ablaufarchitektur basiert auf vielen Kernkonzepten:
- Flume-Ereignis - Es wird als die Einheit des Datenflusses dargestellt, die eine Byte-Nutzlast und eine Menge von Zeichenfolgen mit optionalen Zeichenfolgen-Headern aufweist. Flume betrachtet ein Ereignis nur als einen generischen Blob von Bytes.
- Flume Agent - Hierbei handelt es sich um einen JVM-Prozess, in dem die Komponenten wie Kanäle, Senken und Quellen gehostet werden . Es hat das Potenzial, Ereignisse von einer externen Quelle zu empfangen, zu speichern und an die nächste Ebene weiterzuleiten.
- Gerinne- es ist der Zeitpunkt, zu dem das Ereignis generiert wird.
- Flume-Client - bezieht sich auf die Schnittstelle, auf der der Client am Ursprungspunkt des Ereignisses arbeitet und diese an den Flume-Agenten übermittelt.
- Quelle - Eine Quelle ist eine Quelle, die Ereignisse mit einem bestimmten Format verarbeitet und über einen bestimmten Mechanismus bereitstellt .
- Kanal - Es ist ein passiver Speicher, in dem Ereignisse stattfinden, bis das Waschbecken es für den weiteren Transport entfernt.
- Sink - Entfernt das Ereignis aus einem Kanal und legt es in einem externen Repository wie HDFS ab. Derzeit werden das Erstellen von Text- und Sequenzdateien sowie die Komprimierung in beiden Dateitypen unterstützt.
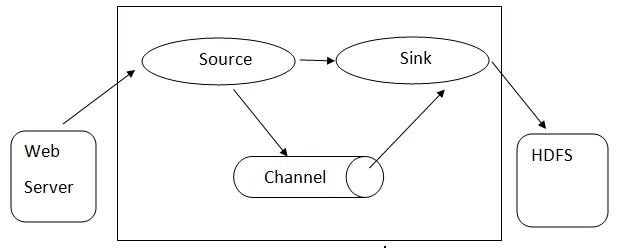
Architektur von Flume
Head to Head Vergleich zwischen Sqoop und Flume (Infografik)
Unten ist der Top 7 Vergleich zwischen Sqoop vs Flume

Hauptunterschiede zwischen Sqoop und Flume
Wir wissen jetzt, dass es viele Unterschiede zwischen Sqoop und Flume gibt. Hier sind die wichtigsten Unterschiede:
1. Sqoop dient zum Austausch von Masseninformationen zwischen Hadoop und Relational Database.
Während Flume verwendet wird, um Daten aus verschiedenen Quellen zu sammeln, die Daten für einen bestimmten Anwendungsfall generieren, und diese große Datenmenge dann von verteilten Ressourcen an ein einziges zentrales Repository zu übertragen.
2. Sqoop enthält auch eine Reihe von Befehlen, mit denen Sie die Datenbank überprüfen können, mit der Sie arbeiten. Daher können wir Sqoop als eine Sammlung verwandter Tools betrachten.
Beim Sammeln des Datums skaliert Flume die Daten horizontal und mehrere Flume-Agenten können in Aktion gesetzt werden, um das Datum zu sammeln und zu aggregieren. Danach werden die Datenprotokolle in einen zentralen Datenspeicher verschoben, z. B. in das Hadoop Distributed File System (HDFS).
3. Der Schlüsselfaktor für die Verwendung von Flume ist, dass die Daten kontinuierlich und in Streaming-Form generiert werden müssen. Ebenso eignet sich Sqoop am besten für Situationen, in denen Ihre Daten in Datenbanksystemen wie MySQL, Oracle, Teradata und PostgreSQL gespeichert sind
Sqoop vs Flume (Vergleichstabelle)
| Grundlage für den Vergleich | SQOOP | FLUME |
|
Grundlegende Natur | Sqoop funktioniert gut mit allen RDBMS mit JDBC (Java Database Connectivity) wie Oracle, MySQL, Teradata usw. | Flume eignet sich gut für Streaming-Datenquellen, die kontinuierlich generiert werden, z. B. Protokolle, JMS, Verzeichnisse, Absturzberichte usw. |
| Datenfluss | Sqoop speziell für die parallele Datenübertragung. Aus diesem Grund kann die Ausgabe in mehreren Dateien erfolgen | Flume wird aufgrund seiner verteilten Natur zum Sammeln und Aggregieren von Daten verwendet. |
| Angetriebene Ereignisse | Sqoop wird nicht von Ereignissen gesteuert. | Der Ablauf ist vollständig ereignisgesteuert. |
| Die Architektur | Sqoop folgt einer Connector-basierten Architektur, dh Connectors können Verbindungen zu einer anderen Datenquelle herstellen. | Flume folgt einer agentenbasierten Architektur, bei der der darin geschriebene Code als Agent bezeichnet wird, der für das Abrufen von Daten verantwortlich ist. |
| Wo zu verwenden | In erster Linie zum schnelleren Kopieren von Daten und anschließenden Generieren von Analyseergebnissen. | Wird im Allgemeinen zum Abrufen von Daten verwendet, wenn Unternehmen Muster, Ursachen oder Stimmungsanalysen mithilfe von Protokollen und sozialen Medien analysieren möchten. |
| Performance | Es reduziert übermäßige Speicher- und Verarbeitungslasten, indem es diese auf andere Systeme überträgt, und bietet eine schnelle Leistung. | Flume ist fehlertolerant, robust und verfügt über einen zuverlässigen Mechanismus für Failover und Recovery. |
| Versionshistorie | Die erste Version von Apache Sqoop wurde im März 2012 veröffentlicht. Die aktuelle stabile Version ist 1.4.7 | Die erste stabile Version 1.2.0 von Apache Flume wurde im Juni 2012 veröffentlicht. Die aktuelle stabile Version ist Apache Flume Version 1.8.0. |
Fazit - Sqoop vs Flume
Wie Sie bereits über Sqoop und Flume erfahren haben, werden in erster Linie zwei Data Ingestion-Tools in der Big Data-Welt verwendet. Wenn Sie Textprotokolldaten in Hadoop / HDFS einlesen müssen, ist Flume die richtige Wahl. Wenn Ihre Daten nicht regelmäßig generiert werden, funktioniert Flume immer noch, aber es ist ein Overkill für diese Situation. Ebenso eignet sich Sqoop nicht für die ereignisgesteuerte Datenverarbeitung.
Empfohlene Artikel
Dies war ein Leitfaden für die Unterschiede zwischen Sqoop und Flume, deren Bedeutung, Kopf-an-Kopf-Vergleich, Hauptunterschiede, Vergleichstabelle und Schlussfolgerung. Dieser Artikel enthält alle nützlichen Unterschiede zwischen Sqoop und Flume. Weitere Informationen finden Sie auch in den folgenden Artikeln
- Hadoop vs Teradata - Nützliche Unterschiede zu lernen
- 5 Wichtigster Unterschied zwischen Apache Kafka und Flume
- Big Data vs Apache Hadoop - Top 4-Vergleich, den Sie lernen müssen
- 5 Wichtigster Unterschied zwischen Apache Kafka und Flume
- Wichtige Text Mining vs Natural Language Processing - Top 5 Vergleiche