

Einführung in Spark-Befehle
Apache Spark ist ein auf Hadoop aufgebautes Framework für schnelle Berechnungen. Es erweitert das Konzept von MapReduce im clusterbasierten Szenario, um eine Aufgabe effizient auszuführen. Spark Command ist in Scala geschrieben.
Hadoop kann von Spark auf folgende Arten verwendet werden (siehe unten):
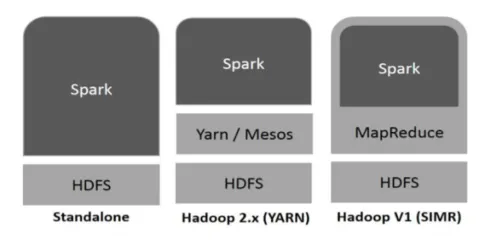
Abb 1
https://www.tutorialspoint.com/
- Standalone: Spark wird direkt auf Hadoop bereitgestellt. Spark-Jobs werden auf Hadoop und Spark parallel ausgeführt.
- Hadoop YARN: Spark läuft auf Yarn, ohne dass eine Vorinstallation erforderlich ist.
- Funken in MapReduce (SIMR): Funken in MapReduce wird zusätzlich zur eigenständigen Bereitstellung zum Starten eines Funkenjobs verwendet. Mit SIMR kann Spark gestartet und die Shell ohne Administratorzugriff verwendet werden.
Bestandteile des Funkens:
- Apache Spark Core
- Spark SQL
- Spark-Streaming
- MLib
- GraphX
Resilient Distributed Datasets (RDD) gelten als die grundlegende Datenstruktur von Spark-Befehlen. RDD ist unveränderlich und schreibgeschützt. Alle Arten von Berechnungen in Funkenbefehlen werden durch Transformationen und Aktionen an RDDs durchgeführt.
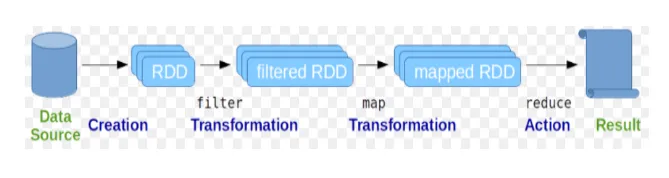
Abb 2
Google Bild
Die Spark-Shell bietet Benutzern ein Medium zur Interaktion mit ihren Funktionen. Spark-Befehle enthalten viele verschiedene Befehle, mit denen Daten auf der interaktiven Shell verarbeitet werden können.
Grundlegende Funkenbefehle
Werfen wir einen Blick auf einige der folgenden Basic Spark-Befehle:
-
So starten Sie die Spark-Shell:

Abb. 3
-
Datei vom lokalen System lesen:

Hier ist "sc" der Spark-Kontext. Da sich "data.txt" im Ausgangsverzeichnis befindet, wird es so gelesen, ansonsten muss der vollständige Pfad angegeben werden.
-
Erstellen Sie RDD durch Parallelisierung

NewData ist jetzt das RDD.
-
Elemente in RDD zählen

-
Sammeln
Diese Funktion gibt den gesamten Inhalt von RDD an das Treiberprogramm zurück. Dies ist hilfreich beim Debuggen in verschiedenen Schritten des Schreibprogramms.
-
Lesen Sie die ersten 3 Artikel von RDD

-
Speichern Sie die ausgegebenen / verarbeiteten Daten in der Textdatei

Hier ist der "Ausgabe" -Ordner der aktuelle Pfad.
Zwischenzündbefehle
1. Filtern Sie nach RDD
Erstellen wir eine neue RDD für Elemente, die "Ja" enthalten.

Der Transformationsfilter muss für die vorhandene RDD aufgerufen werden, um nach dem Wort "yes" zu filtern. Dadurch wird eine neue RDD mit der neuen Elementliste erstellt.
2. Kettenbetrieb

Hier wirkten Filtertransformation und Zählaktion zusammen. Dies wird Kettenoperation genannt.
3. Lesen Sie den ersten Artikel von RDD

4. Zählen Sie die RDD-Partitionen
Wie wir wissen, besteht RDD aus mehreren Partitionen, daher muss die Nr. Gezählt werden. von Partitionen. Da es bei der Optimierung und Fehlerbehebung bei der Arbeit mit Spark-Befehlen hilft.

Standardmäßig mindestens no. Die pf-Partition ist 2.
5. beitreten
Diese Funktion verknüpft zwei Tabellen (Tabellenelement ist paarweise) auf der Grundlage des gemeinsamen Schlüssels. Bei paarweiser RDD ist das erste Element der Schlüssel und das zweite Element der Wert.
6. Cache eine Datei
Caching ist eine Optimierungstechnik. Caching von RDD bedeutet, dass sich RDD im Speicher befindet und alle zukünftigen Berechnungen für diese RDD im Speicher durchgeführt werden. Dies spart Zeit beim Lesen der Festplatte und verbessert die Leistung. Kurz gesagt, es reduziert die Zeit für den Zugriff auf die Daten.

Daten werden jedoch nicht zwischengespeichert, wenn Sie die obige Funktion ausführen. Dies kann durch den Besuch der Webseite bewiesen werden:
http: // localhost: 4040 / storage
RDD wird zwischengespeichert, sobald die Aktion abgeschlossen ist. Beispielsweise:

Eine weitere Funktion, die ähnlich wie cache () funktioniert, ist persist (). Persist gibt Benutzern die Flexibilität, das Argument anzugeben, mit dessen Hilfe Daten im Arbeitsspeicher, auf der Festplatte oder außerhalb des Heapspeichers zwischengespeichert werden können. Persist ohne Argument funktioniert genauso wie cache ().
Erweiterte Funkbefehle
Werfen wir einen Blick auf einige der erweiterten Spark-Befehle, die unten aufgeführt sind:
-
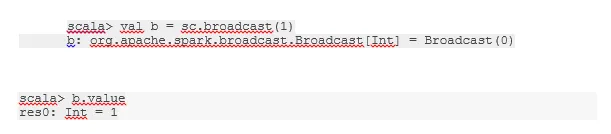
Senden Sie eine Variable
Broadcast-Variable hilft dem Programmierer, die einzige auf jedem Computer im Cluster zwischengespeicherte Variable zu lesen, anstatt eine Kopie dieser Variablen mit Aufgaben zu versenden. Dies hilft bei der Reduzierung der Kommunikationskosten.
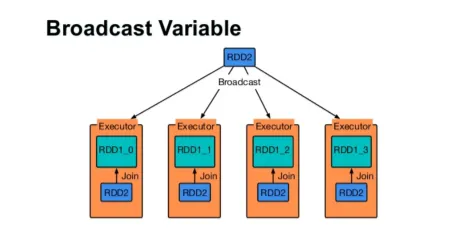
Abb. 4
Google Bild
Kurz gesagt, es gibt drei Hauptmerkmale der Broadcasted-Variablen:
- Unveränderlich
- Fit in Erinnerung
- Über Cluster verteilt
-
Akkus
Akkumulatoren sind die Variablen, die assoziierten Operationen hinzugefügt werden. Es gibt viele Verwendungsmöglichkeiten für Akkumulatoren wie Zähler, Summen usw.

Der Name des Akkus im Code ist auch in der Spark-Benutzeroberfläche zu sehen.
-
Karte
Die Kartenfunktion hilft beim Durchlaufen jeder Zeile in RDD. Die in der Karte verwendete Funktion wird auf jedes Element in RDD angewendet.
Wenn wir zum Beispiel in RDD (1, 2, 3, 4, 6) "rdd.map (x => x + 2)" anwenden, erhalten wir das Ergebnis als (3, 4, 5, 6, 8).
-
Flatmap
Flatmap funktioniert ähnlich wie Map, aber Map gibt nur ein Element zurück, während Flatmap die Liste der Elemente zurückgeben kann. Das Teilen von Sätzen in Wörter erfordert daher eine Flatmap.
-
Verschmelzen
Diese Funktion hilft, das Mischen von Daten zu vermeiden. Dies wird in der vorhandenen Partition angewendet, damit weniger Daten gemischt werden. Auf diese Weise können wir die Verwendung von Knoten im Cluster einschränken.
Tipps und Tricks zum Verwenden von Funkenbefehlen
Nachfolgend sind die verschiedenen Tipps und Tricks von Spark-Befehlen aufgeführt:
- Anfänger von Spark können Spark-Shell verwenden. Da Spark-Befehle auf Scala basieren, ist die Verwendung der Scala-Spark-Shell auf jeden Fall großartig. Es gibt jedoch auch eine Python-Spark-Shell, sodass auch etwas verwendet werden kann, das sich gut mit Python auskennt.
- Die Spark-Shell verfügt über zahlreiche Optionen zum Verwalten der Ressourcen des Clusters. Der folgende Befehl kann Ihnen dabei helfen:

- In Spark ist das Arbeiten mit langen Datensätzen die übliche Sache. Aber es geht schief, wenn schlechte Eingaben gemacht werden. Es ist immer eine gute Idee, fehlerhafte Zeilen mit der Filterfunktion von Spark zu löschen. Der gute Input wird ein großartiger Erfolg sein.
- Spark wählt selbst eine gute Partition für Ihre Daten. Es ist jedoch immer eine gute Praxis, Partitionen im Auge zu behalten, bevor Sie mit der Arbeit beginnen. Das Ausprobieren verschiedener Partitionen hilft Ihnen bei der Parallelisierung Ihres Jobs.
Fazit - Spark-Befehle:
Spark Command ist eine revolutionäre und vielseitige Big-Data-Engine, die für die Stapelverarbeitung, Echtzeitverarbeitung, Zwischenspeicherung von Daten usw. geeignet ist. Spark verfügt über eine Vielzahl von Bibliotheken für maschinelles Lernen, mit denen Datenwissenschaftler und Analyseunternehmen starke, interaktive und leistungsfähige Datenbanken erstellen können schnelle Anwendungen.
Empfohlene Artikel
Dies war eine Anleitung für Spark-Befehle. Hier haben wir grundlegende sowie erweiterte Spark-Befehle und einige unmittelbare Spark-Befehle besprochen. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- Adobe Photoshop-Befehle
- Wichtige VBA-Befehle
- Tableau-Befehle
- Spickzettel SQL (Befehle, kostenlose Tipps und Tricks)
- Arten von Joins in Spark SQL (Beispiele)
- Spark Components | Übersicht und Top 6 Komponenten