

Einführung in Funktionen in R
Die Funktion ist als eine Reihe von Anweisungen definiert, mit denen eine bestimmte logische Aufgabe ausgeführt und ausgeführt werden kann. Function verwendet einige Eingabeparameter, die als Argumente bezeichnet werden, um diese Aufgabe auszuführen. Funktionen helfen dabei, den Code in einfachere Blöcke zu unterteilen, indem sie ihn logisch orchestrieren, was leichter zu lesen und zu verstehen ist. In diesem Thema lernen wir Funktionen in R kennen.
Wie schreibe ich Funktionen in R?
Um die Funktion in R zu schreiben, ist hier die Syntax:
Fun_name <- function (argument) (
Function body
)
Hier ist zu sehen, dass in R ein funktionsspezifisches reserviertes Wort verwendet wird, um eine beliebige Funktion zu definieren. Die Funktion nimmt Eingaben in Form von Argumenten entgegen. Der Funktionskörper besteht aus einer Reihe logischer Anweisungen, die über Argumente ausgeführt werden, und gibt dann die Ausgabe zurück. "Fun_name" ist der Name der Funktion, über den sie an einer beliebigen Stelle im R-Programm aufgerufen werden kann.
Schauen wir uns ein Beispiel an, das das Verständnis des Funktionsbegriffs in R verdeutlicht.
R-Code
Multi <- function(x, y) (
# function to print x multiply y
result <- x*y
print(paste(x, "Multiply", y, "is", result))
)
Ausgabe:
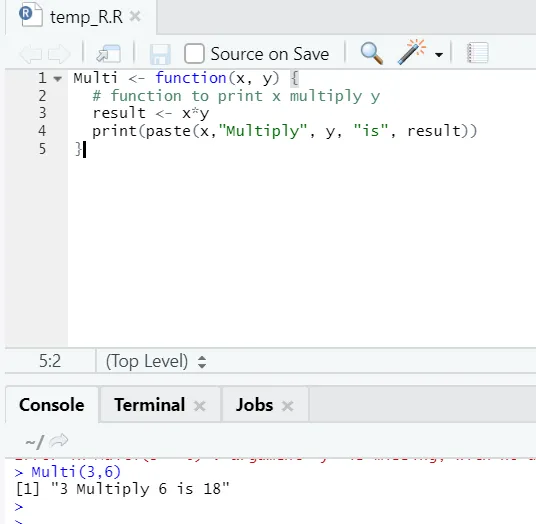
Hier haben wir den Funktionsnamen „Multi“ erstellt, der zwei Argumente als Eingabe verwendet und die multiplizierte Ausgabe bereitstellt. Das erste Argument ist x und das zweite Argument ist y. Wie Sie sehen, haben wir die Funktion mit dem Namen "Multi" bezeichnet. Wenn jemand möchte, können hier auch Argumente auf den Standardwert gesetzt werden.
Verschiedene Arten von Funktionen in R
Verschiedene R-Funktionen mit Syntax und Beispielen (eingebaut, mathematisch, statistisch usw.)
1) Eingebaute Funktion -
Dies sind die Funktionen, die mit R geliefert werden, um eine bestimmte Aufgabe zu lösen, indem ein Argument als Eingabe verwendet und eine Ausgabe basierend auf der angegebenen Eingabe ausgegeben wird. Lassen Sie uns hier einige wichtige allgemeine Funktionen von R diskutieren:
a) Sortieren: Die Daten können in aufsteigender oder absteigender Reihenfolge sortiert werden. Die Daten können sein, ob ein Vektor einer kontinuierlichen Variablen oder einer Faktorvariablen ist.
Syntax:

Hier ist die Erklärung seiner Parameter:
- x: Dies ist ein Vektor der stetigen Variablen oder Faktorvariablen
- absteigend: Dies kann entweder auf Wahr / Falsch gesetzt werden, um die Reihenfolge aufsteigend oder absteigend zu steuern. Standardmäßig ist es FALSE`.
- last: Wenn der Vektor NA-Werte hat, sollte er zuletzt gesetzt werden oder nicht
R Code und Ausgabe:
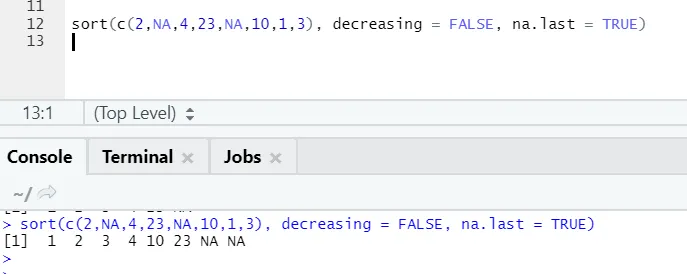
Hier merkt man, wie sich die NA-Werte am Ende angleichen. Als unser Parameter na.last = True war true.
b) Seq: Erzeugt eine Folge der Nummer zwischen zwei angegebenen Nummern.
Syntax
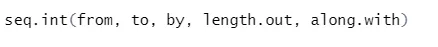
Hier ist die Erklärung seiner Parameter:
- von, bis Start- und Endwert der Sequenz.
- by: Inkrement / Lücke zwischen zwei aufeinanderfolgenden Zahlen
- length.out: Die erforderliche Länge der Sequenz.
- Along.with: Bezieht sich auf die Länge aus der Länge dieses Arguments
R Code und Ausgabe:
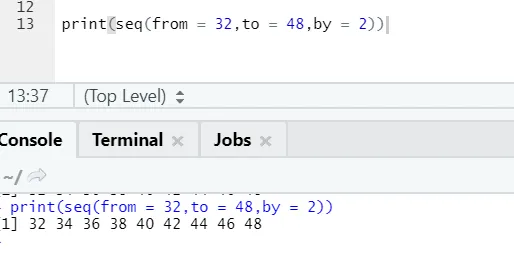
Hier kann man feststellen, dass die erzeugte Sequenz eine Inkrementierung von 2 aufweist, da by als 2 definiert ist.
c) Toupper, tolower: Die beiden Funktionen toupper und tolower sind Funktionen, die auf die Zeichenfolge angewendet werden, um die Groß- und Kleinschreibung der Buchstaben in Sätzen zu ändern.
R Code und Ausgabe:
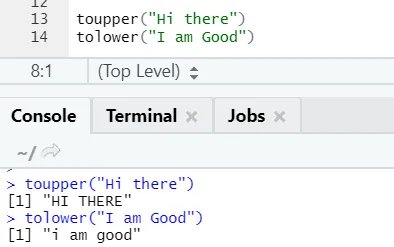
Man kann feststellen, wie sich die Groß- und Kleinschreibung von Buchstaben ändert, wenn man sie auf die Funktion anwendet.
d) Rnorm: Dies ist eine integrierte Funktion, die Zufallszahlen generiert.
R Code und Ausgabe:
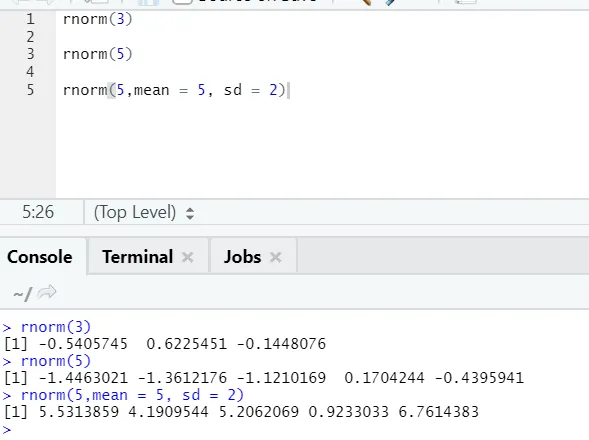
Die Funktion rnorm verwendet das erste Argument, das angibt, wie viele Zahlen generiert werden müssen.
e) Rep: Diese Funktion repliziert den Wert so oft wie angegeben.
R-Syntax: rnorm (x, n)
Hier steht x für den zu replizierenden Wert und n für die Häufigkeit der Replizierung.
R Code und Ausgabe:
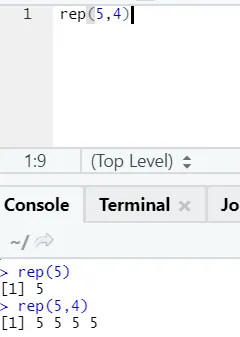
f) Einfügen: Mit dieser Funktion werden Zeichenfolgen mit einem bestimmten Zeichen dazwischen verkettet.
Syntax
paste(x, sep = “”, collapse = NULL)
R-Code
paste("fish", "water", sep=" - ")
R Ausgang:
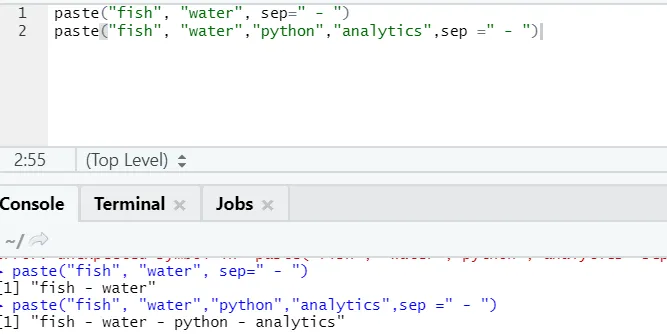
Wie Sie sehen, können wir auch mehr als zwei Zeichenfolgen einfügen. Sep ist das spezifische Zeichen, das wir zwischen den Zeichenfolgen hinzugefügt haben. Standardmäßig ist sep Leerzeichen.
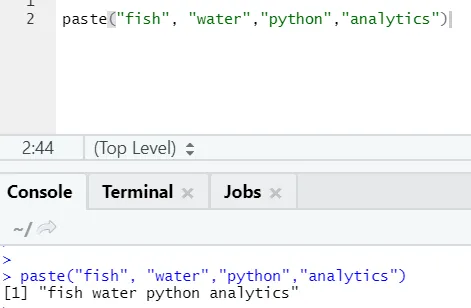
Es gibt noch eine ähnliche Funktion, die jeder kennen sollte: paste0.
Die Funktion paste0 (x, y, collapse) funktioniert ähnlich wie paste (x, y, sep = “”, collapse).
Bitte beachten Sie das folgende Beispiel:
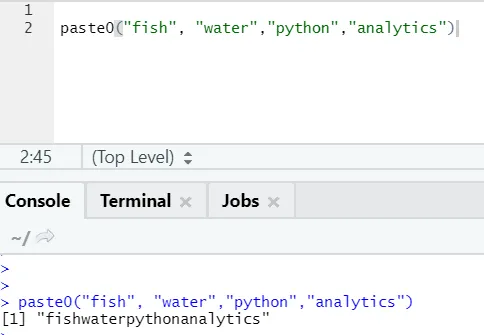
In einfachen Worten, um paste und paste0 zusammenzufassen:
Paste0 ist schneller als Paste, wenn es um die Verkettung von Strings ohne Trennzeichen geht. Als Paste sucht man immer "sep" und das ist standardmäßig Leerzeichen drin.
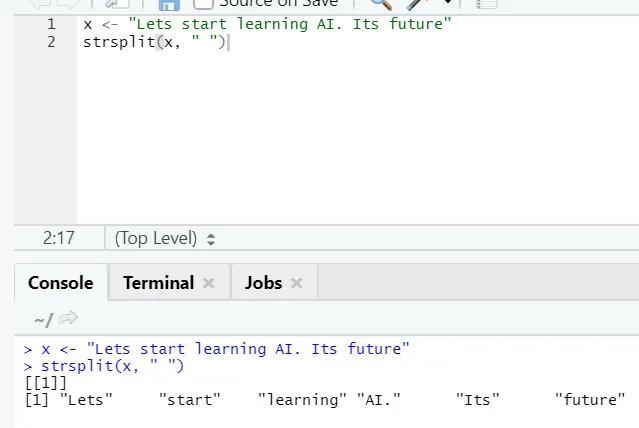
g) Strsplit: Diese Funktion dient zum Teilen der Zeichenkette. Schauen wir uns die einfachen Fälle an:
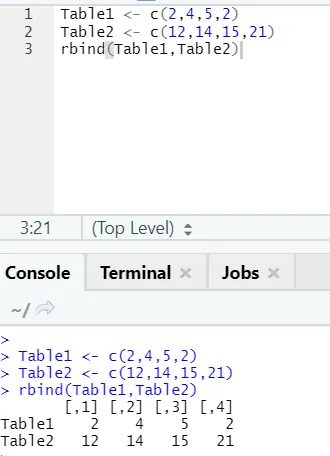
h) Rbind: Die Funktion rbind hilft, Vektoren mit der gleichen Anzahl von Spalten übereinander zu kämmen.
Beispiel
i) cbind: Kombiniert Vektoren mit der gleichen Anzahl von Zeilen nebeneinander.
Beispiel
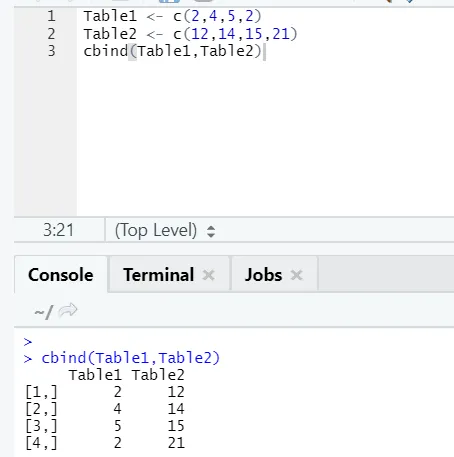
Falls die Anzahl der Zeilen nicht übereinstimmt, wird der folgende Fehler angezeigt:

Sowohl cbind als auch rbind helfen bei der Manipulation und Umgestaltung von Daten.
2) Mathematikfunktion -
R bietet eine Vielzahl von mathematischen Funktionen. Sehen wir uns einige davon genauer an:
a) Sqrt: Diese Funktion berechnet die Quadratwurzel einer Zahl oder eines numerischen Vektors.
R Code und Ausgabe:
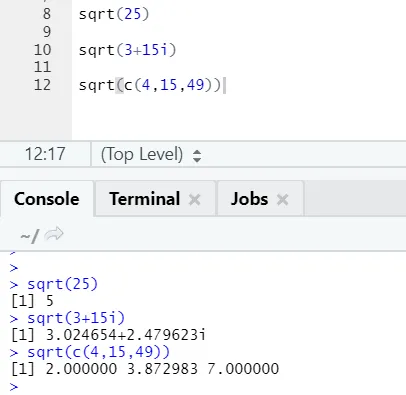
Man kann sehen, wie die Quadratwurzel einer Zahl, einer komplexen Zahl und einer Folge von numerischen Vektoren berechnet wurde.
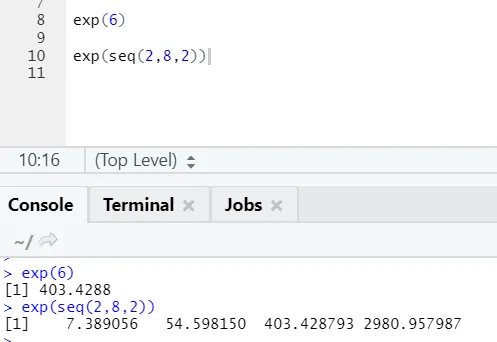
b) Exp: Diese Funktion berechnet den Exponentialwert einer Zahl oder eines numerischen Vektors.
R Code und Ausgabe:
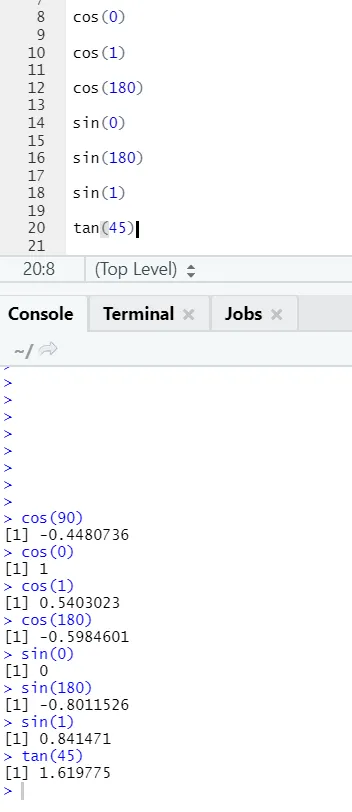
c) Cos, Sin, Tan: Dies sind Trigonometriefunktionen, die hier in R implementiert sind.
R Code und Ausgabe:
d) Abs: Diese Funktion gibt den absoluten positiven Wert einer Zahl zurück.
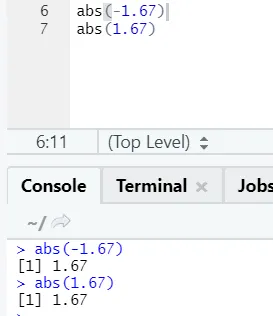
Wie Sie sehen, wird das Negative oder Positive einer Zahl in absoluter Form zurückgegeben. Lassen Sie es uns für eine komplexe Zahl sehen:
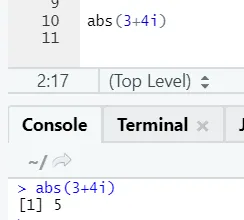
e) Log: Hier wird der Logarithmus einer Zahl ermittelt.
Hier ist das folgende Beispiel:
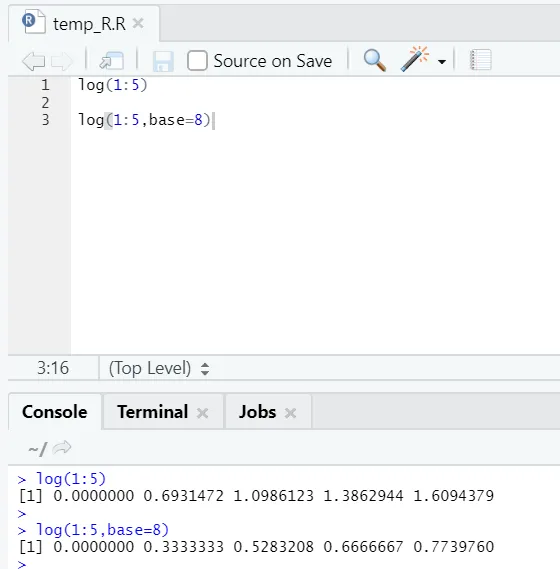
Hier hat man die Flexibilität, die Basis je nach Anforderung zu wechseln.
f) Cumsum: Dies ist eine mathematische Funktion, die kumulative Summen ergibt. Hier ist das Beispiel unten:
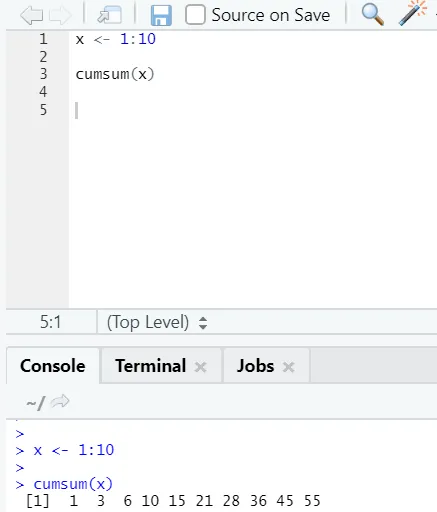
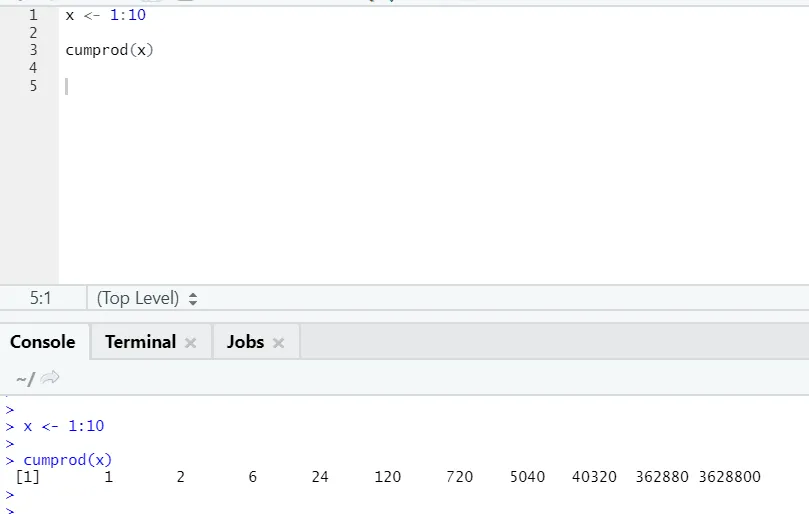
g) Cumprod: Wie die mathematische Funktion Cumsum haben wir cumprod, wo die kumulative Multiplikation stattfindet.
Bitte beachten Sie das folgende Beispiel:
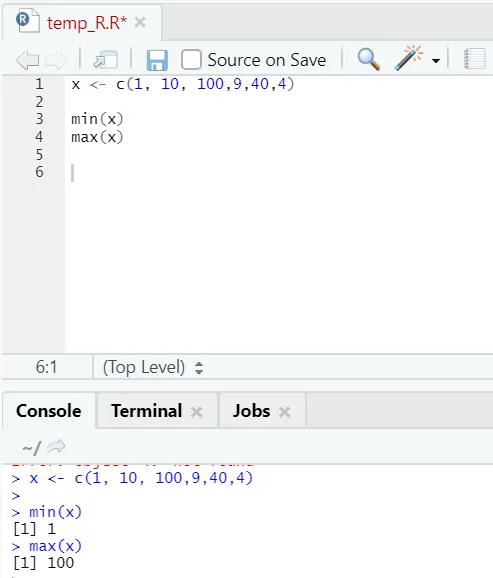
h) Max, Min: Dies hilft Ihnen, den Maximal- / Minimalwert in der Zahlenmenge zu finden. Siehe unten die dazugehörigen Beispiele:
i) Decke: Die Decke ist eine mathematische Funktion, die die kleinste ganze Zahl zurückgibt, die höher als angegeben ist.
Schauen wir uns ein Beispiel an:
Decke (2, 67)
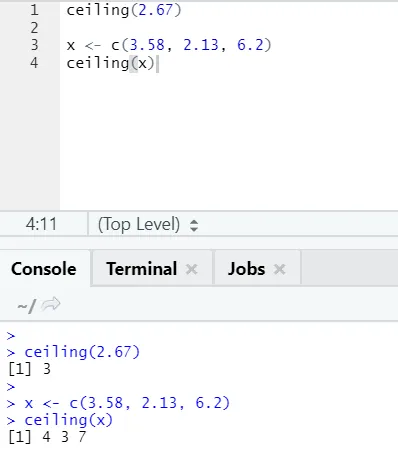
Wie Sie sehen, wird die Obergrenze sowohl über eine Zahl als auch über eine Liste angewendet, und die Ausgabe ist die kleinste der nächsthöheren Ganzzahlen.
j) Etage: Die Etage ist eine mathematische Funktion, die den kleinsten ganzzahligen Wert der angegebenen Zahl zurückgibt.
Das folgende Beispiel hilft Ihnen dabei, es besser zu verstehen:
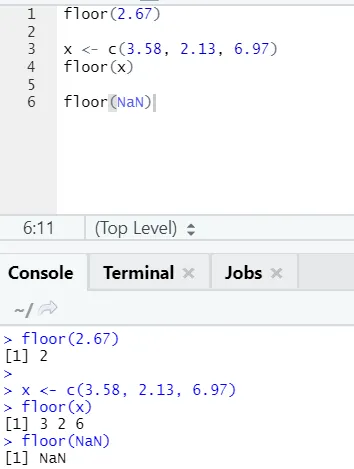
Dies gilt auch für negative Werte. Bitte werfen Sie einen Blick darauf:
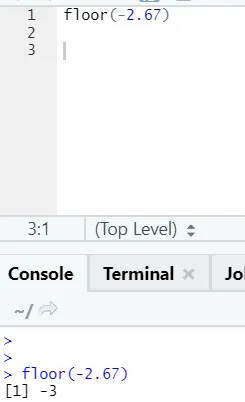
3) Statistische Funktionen -
Dies sind die Funktionen, die die zugehörige Wahrscheinlichkeitsverteilung beschreiben.
a) Median: Berechnet den Median aus der Zahlenfolge.
Syntax
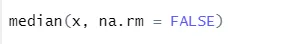
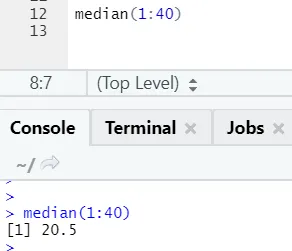
R Code und Ausgabe:
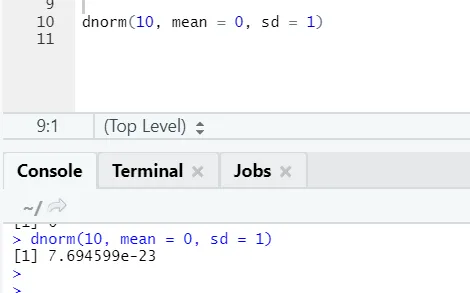
b) Dnorm: Dies bezieht sich auf die Normalverteilung. Die Funktion dnorm gibt den Wert der Wahrscheinlichkeitsdichtefunktion für die Normalverteilung mit Parametern für x, μ und σ zurück.
R Code und Ausgabe:
c) Cov: Die Covarianz gibt an, ob zwei Vektoren positiv, negativ oder überhaupt nicht miteinander verwandt sind.
R-Code
x_new = c(1., 5.5, 7.8, 4.2, -2.7, -5.5, 8.9)
y_new = c(0.1, 2.0, 0.8, -4.2, 2.7, -9.4, -1.9)
cov(x_new, y_new)
R Ausgang:
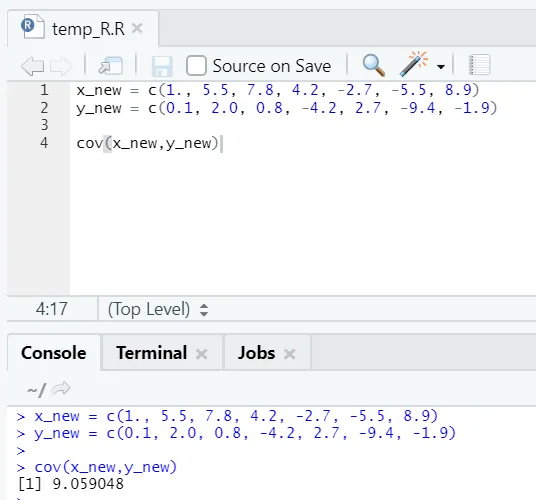
Wie Sie sehen, sind zwei Vektoren positiv miteinander verbunden, dh beide Vektoren bewegen sich in die gleiche Richtung. Wenn die Kovarianz negativ ist, bedeutet dies, dass x und y in umgekehrter Beziehung zueinander stehen und sich daher in die entgegengesetzte Richtung bewegen.
d) Cor: Dies ist eine Funktion, um die Korrelation zwischen Vektoren zu finden. Es gibt tatsächlich den Assoziationsfaktor zwischen den beiden Vektoren an, der als "Korrelationskoeffizient" bekannt ist. Durch die Korrelation wird ein Gradfaktor gegenüber der Kovarianz hinzugefügt. Wenn zwei Vektoren positiv korreliert sind, gibt die Korrelation auch an, inwieweit sie positiv verwandt sind.
Diese drei Arten von Methoden können verwendet werden, um eine Korrelation zwischen zwei Vektoren zu finden:
- Pearson Korrelation
- Kendall-Korrelation
- Spearman-Korrelation
Im einfachen R-Format sieht es so aus:
cor(x, y, method = c("pearson", "kendall", "spearman"))
Hier sind x und y Vektoren.
Sehen wir uns das praktische Beispiel für die Korrelation eines eingebauten Datasets an.
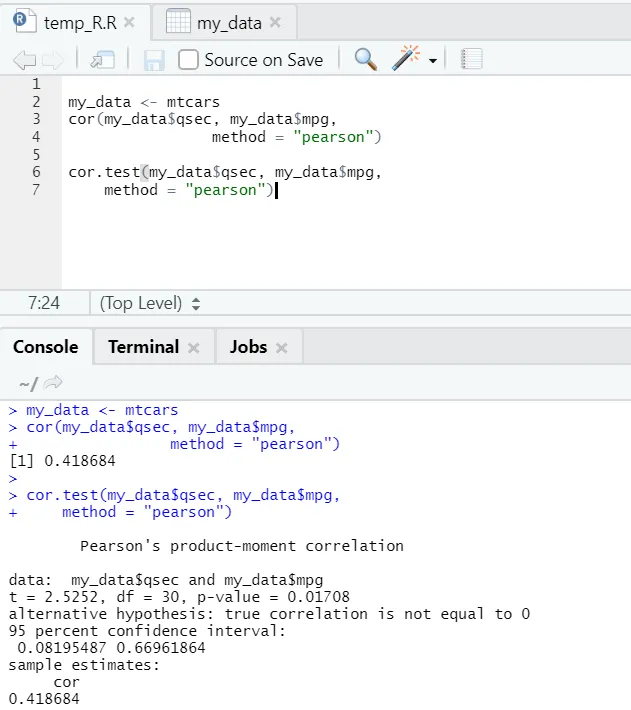
Hier sehen Sie also, dass die Funktion "cor ()" den Korrelationskoeffizienten 0, 41 zwischen "qsec" und "mpg" angibt. Es wurde jedoch auch eine weitere Funktion vorgestellt, nämlich "cor.test ()", die nicht nur den Korrelationskoeffizienten, sondern auch den zugehörigen p-Wert und t-Wert angibt. Die Interpretation wird mit der Funktion cor.test wesentlich einfacher.
Ähnlich kann mit den beiden anderen Korrelationsmethoden verfahren werden:
R-Code für die Pearson-Methode:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " pearson ")
cor.test(my_data$qsec, my_data$mpg, method = " pearson")
R-Code für Kendall-Methode:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " kendall")
cor.test(my_data$qsec, my_data$mpg, method = " kendall")
R-Code für die Spearman-Methode:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = "spearman")
cor.test(my_data$qsec, my_data$mpg, method = "spearman")
Der Korrelationskoeffizient liegt zwischen -1 und 1.
Wenn der Korrelationskoeffizient negativ ist, bedeutet dies, dass x zunimmt und y abnimmt.
Wenn der Korrelationskoeffizient Null ist, bedeutet dies, dass keine Zuordnung zwischen x und y besteht.
Wenn der Korrelationskoeffizient positiv ist, bedeutet dies, dass, wenn x zunimmt, auch y dazu neigt, anzusteigen.
e) T-Test: Der T-Test zeigt an, ob zwei Datensätze von derselben (angenommenen) Normalverteilung stammen oder nicht.
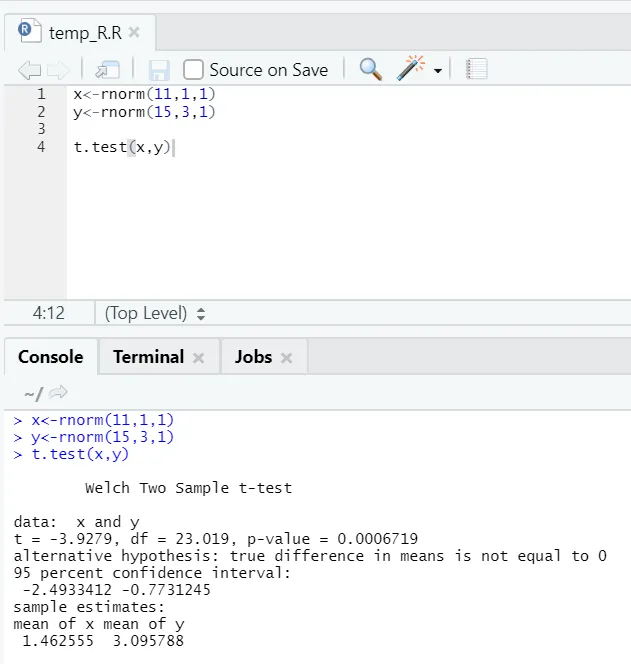
Hier sollten Sie die Nullhypothese ablehnen, dass die beiden Mittelwerte gleich sind, da der p-Wert kleiner als 0, 05 ist.
Diese gezeigte Instanz ist vom Typ: ungepaarte Datensätze mit ungleichen Abweichungen. Ebenso kann mit dem gepaarten Datensatz versucht werden.
f) Einfache lineare Regression: Dies zeigt die Beziehung zwischen dem Prädiktor / der unabhängigen und der antwort- / abhängigen Variablen.
Ein einfaches praktisches Beispiel könnte sein, das Gewicht einer Person vorherzusagen, wenn die Größe bekannt ist.
R-Syntax
lm(formula, data)
Hier zeigt die Formel die Beziehung zwischen Ausgabe, dh y, und Eingabevariable, dhx. Daten stellen den Datensatz dar, auf den die Formel angewendet werden muss.
Schauen wir uns ein praktisches Beispiel an, bei dem die Grundfläche die Eingangsgröße und die Miete die Ausgangsgröße ist.
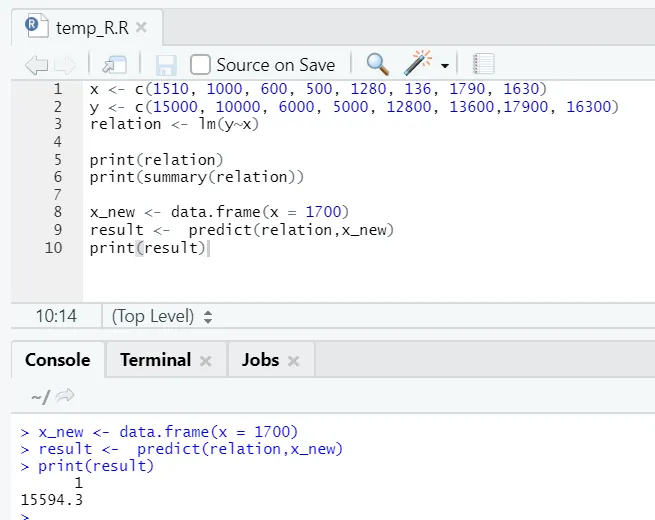
x <- c (1510, 1000, 600, 500, 1280, 136, 1790, 1630)
y <- c (15000, 10000, 6000, 5000, 12800, 13600, 17900, 16300)
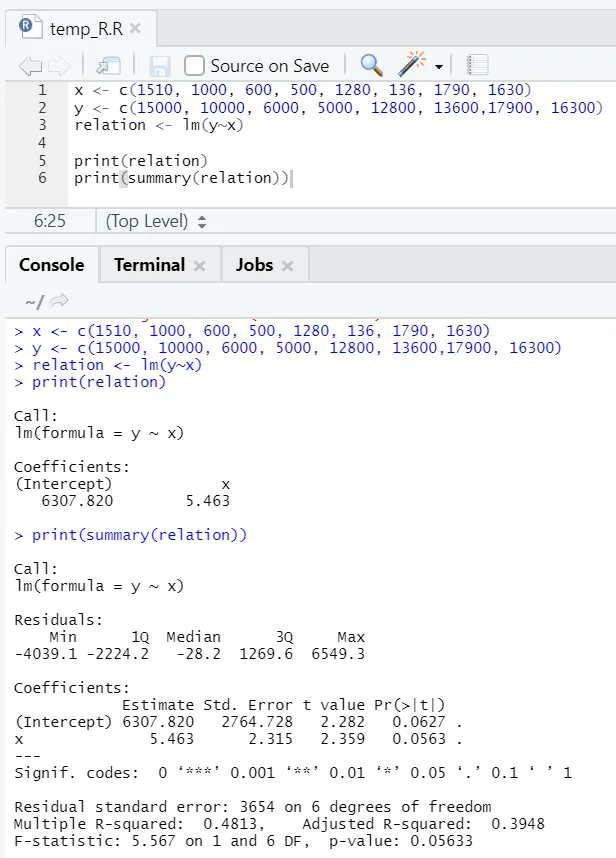
Hier beträgt der P-Wert nicht weniger als 5%. Daher kann die Nullhypothese nicht zurückgewiesen werden. Es ist wenig aussagekräftig, den Zusammenhang zwischen Grundfläche und Miete zu belegen.
Hier beträgt der R-Quadrat-Wert 0, 4813. Dies bedeutet, dass nur 48% der Varianz in der Ausgangsvariablen durch die Eingangsvariable erklärt werden können.
Angenommen, wir müssen jetzt einen Wert für die Grundfläche auf der Grundlage des oben angepassten Modells vorhersagen.
R-Code
x_new <- data.frame(x = 1700)
result <- predict(relation, x_new)
print(result)
R Ausgang:
Nach der Ausführung des obigen R-Codes sieht die Ausgabe folgendermaßen aus:
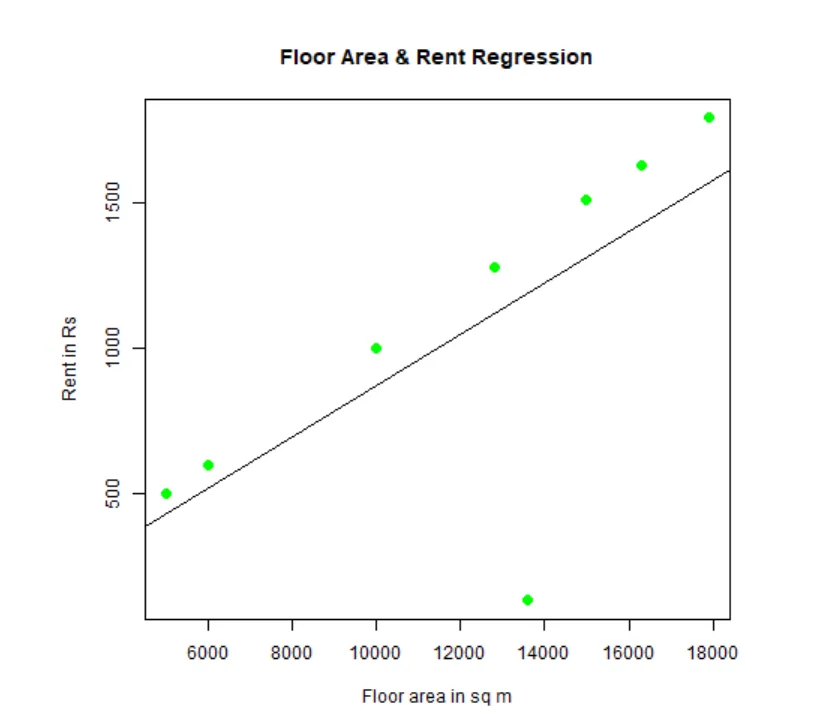
Man kann Regression anpassen und visualisieren. Hier ist der R-Code dafür:
# Geben Sie der PNG-Diagrammdatei einen Namen.
png(file = "LinearRegressionSample.png.webp")
# Zeichnen Sie das Diagramm.
plot(y, x, col = "green", main = "Floor Area & Rent Regression",
abline(lm(x~y)), cex = 1.3, pch = 16, xlab = "Floor area in sq m", ylab = "Rent in Rs")
# Speicher die Datei.
dev.off()
Dieses Diagramm "LinearRegressionSample.png.webp" wird in Ihrem aktuellen Arbeitsverzeichnis erstellt.
g) Chi-Quadrat-Test
Dies ist eine statistische Funktion in R. Dieser Test behält seine Bedeutung, um zu beweisen, ob die Korrelation zwischen zwei kategorialen Variablen besteht.
Dieser Test funktioniert auch wie alle anderen statistischen Tests, die auf dem p-Wert basieren. Man kann die Nullhypothese akzeptieren oder ablehnen.
R-Syntax
chisq.test(data), /code>
Sehen wir uns ein praktisches Beispiel an.
R-Code
# Laden Sie die Bibliothek.
library(datasets)
data(iris)
# Erstellen Sie einen Datenrahmen aus dem Hauptdatensatz.
iris.data <- data.frame(iris$Sepal.Length, iris$Sepal.Width)
# Erstellen Sie eine Tabelle mit den benötigten Variablen.
iris.data = table(iris$Sepal.Length, iris$Sepal.Width)
print(iris.data)
# Führen Sie den Chi-Square-Test durch.
print(chisq.test(iris.data))
R Ausgang:
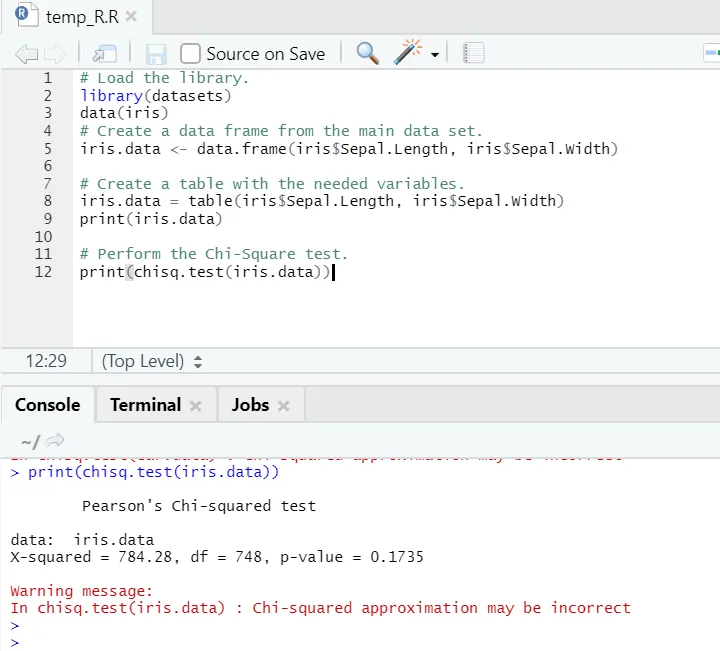
Wie man sieht, wurde der Chi-Quadrat-Test anhand eines Iris-Datensatzes durchgeführt, wobei die beiden Variablen „Sepal. Länge “und„ Sepal.Breite “.
Der p-Wert beträgt nicht weniger als 0, 05, daher besteht keine Korrelation zwischen diesen beiden Variablen. Oder wir können sagen, dass diese beiden Variablen nicht voneinander abhängig sind.
Fazit
Funktionen in R sind einfach, leicht zu montieren, leicht zu erfassen und dennoch sehr leistungsfähig. Wir haben eine Vielzahl von Funktionen gesehen, die als Teil der Grundlagen in R verwendet werden. Sobald man sich mit diesen oben diskutierten Funktionen vertraut gemacht hat, kann man andere Arten von Funktionen untersuchen. Funktionen helfen Ihnen dabei, Ihren Code einfach und übersichtlich auszuführen. Funktionen können eingebaut oder benutzerdefiniert sein, alles hängt von den Anforderungen bei der Lösung eines Problems ab. Funktionen geben einem Programm eine gute Form.
Empfohlene Artikel
Dies ist eine Anleitung zu Funktionen in R. Hier wird erläutert, wie Funktionen in R und verschiedene Arten von Funktionen in R mit Syntax und Beispielen geschrieben werden. Sie können auch den folgenden Artikel lesen, um mehr zu erfahren -
- R String-Funktionen
- SQL-String-Funktionen
- T-SQL-Zeichenfolgenfunktionen
- PostgreSQL-String-Funktionen