

Einführung in AWS EMR
AWS EMR bietet viele Funktionen, die uns die Arbeit erleichtern. Einige der Technologien sind:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
Einer der wichtigsten von AWS EMR bereitgestellten Dienste, mit dem wir uns befassen werden, ist Amazon EMR.
Die im Allgemeinen als Elastic Map Reduce bezeichnete EMR bietet eine einfache und leicht zugängliche Möglichkeit, die Verarbeitung größerer Datenblöcke zu bewältigen. Stellen Sie sich ein Big-Data-Szenario vor, in dem wir über eine große Datenmenge verfügen und eine Reihe von Vorgängen ausführen, beispielsweise, dass ein Map-Reduce-Auftrag ausgeführt wird. Eines der Hauptprobleme der Bigdata-Anwendung ist die Optimierung des Programms Es fällt uns oft schwer, unser Programm so abzustimmen, dass alle zugewiesenen Ressourcen richtig verbraucht werden. Aufgrund dieses obigen Abstimmungsfaktors nimmt die für die Verarbeitung benötigte Zeit allmählich zu. Elastic Map Reduce the Service von Amazon ist ein Webdienst, der ein Framework bereitstellt, das alle für die Big Data-Verarbeitung erforderlichen Funktionen auf kostengünstige, schnelle und sichere Weise verwaltet. Von der Clustererstellung bis zur Datenverteilung über verschiedene Instanzen hinweg lassen sich all diese Dinge problemlos unter Amazon EMR verwalten. Die Dienste hier sind On-Demand-Dienste, dh, wir können die Nummern basierend auf den Daten steuern, die wir haben, wenn sie kosteneffizient und skalierbar sind.
Gründe für die Verwendung von AWS EMR
Warum also AMR verwenden, was es besser macht als andere? Wir stoßen häufig auf ein sehr grundlegendes Problem, bei dem wir keiner Anwendung alle im Cluster verfügbaren Ressourcen zuweisen können. AMAZON EMR kümmert sich um diese Probleme und ordnet die erforderlichen Ressourcen auf der Grundlage der Datenmenge und des Anwendungsbedarfs zu. Da wir in der Natur elastisch sind, können wir es auch entsprechend ändern. EMR bietet umfassende Anwendungsunterstützung, sei es Hadoop, Spark oder HBase, die die Datenverarbeitung vereinfacht. Es unterstützt verschiedene ETL-Operationen schnell und kostengünstig. Es kann auch für MLIB in Spark verwendet werden. Wir können verschiedene maschinelle Lernalgorithmen ausführen. Sei es Batch-Daten oder Echtzeit-Streaming von Daten EMR ist in der Lage, beide Arten von Daten zu organisieren und zu verarbeiten.
Arbeitsweise von AWS EMR
Sehen wir uns nun dieses Diagramm des Amazon EMR-Clusters an und versuchen zu verstehen, wie es tatsächlich funktioniert:
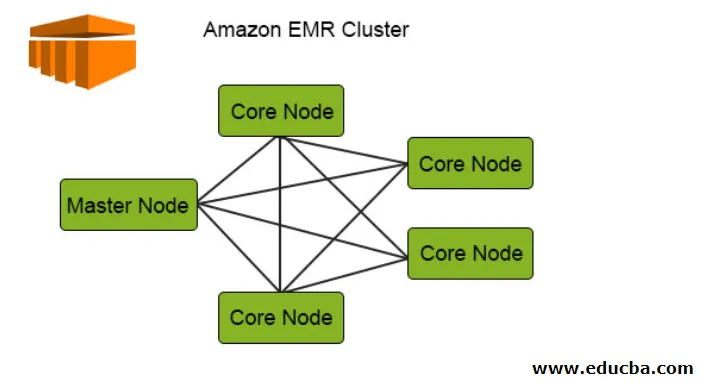
Das folgende Diagramm zeigt die Clusterverteilung innerhalb der EMR. Lassen Sie uns das im Detail überprüfen:
1. Die Cluster sind die zentrale Komponente in der Amazon EMR-Architektur. Sie sind eine Sammlung von EC2-Instanzen, die als Knoten bezeichnet werden. Jeder Knoten hat seine spezifischen Rollen innerhalb des Clusters, die als Knotentyp bezeichnet werden. Basierend auf seinen Rollen können wir sie in drei Typen einteilen:
- Hauptknoten
- Kernknoten
- Aufgabenknoten
2. Der Master-Knoten ist, wie der Name schon sagt, der Master, der für die Verwaltung des Clusters, die Ausführung der Komponenten und die Verteilung der Daten über die Knoten zur Verarbeitung verantwortlich ist. Es wird nur nachverfolgt, ob alles ordnungsgemäß verwaltet wird und einwandfrei funktioniert, und es wird im Fehlerfall fortgefahren.
3. Der Kernknoten ist dafür verantwortlich, die Aufgabe auszuführen und die Daten in HDFS im Cluster zu speichern. Alle Verarbeitungsteile werden vom Kernknoten verarbeitet, und die Daten werden nach dieser Verarbeitung an den gewünschten HDFS-Speicherort gestellt.
4. Der Task-Knoten, der optional ist, hat nur den Auftrag, den Task auszuführen, in dem die Daten nicht in HDFS gespeichert werden.
5. Wann immer nach der Übergabe eines Auftrags haben wir verschiedene Methoden, um zu entscheiden, wie die Arbeiten abgeschlossen werden müssen. Von der Beendigung des Clusters nach Abschluss des Auftrags bis hin zu einem Cluster mit langer Laufzeit, in dem über die EMR-Konsole und die CLI Schritte übermittelt werden, sind wir alle berechtigt, dies zu tun.
6. Sie können den Job direkt auf dem EMR ausführen, indem Sie ihn mit dem Masterknoten über die verfügbaren Schnittstellen und Tools verbinden, mit denen Jobs direkt auf dem Cluster ausgeführt werden.
7. Wir können unsere Daten auch mit Hilfe von EMR in verschiedenen Schritten ausführen. Alles, was wir tun müssen, ist, einen oder mehrere geordnete Schritte im EMR-Cluster einzureichen. Die Daten werden als Datei gespeichert und nacheinander verarbeitet. Ausgehend vom Status "Ausstehend" bis zum Status "Abgeschlossen" können wir die Verarbeitungsschritte nachverfolgen und feststellen, dass die Fehler auch vom Status "Abgebrochen fehlgeschlagen" stammen. Alle diese Schritte können problemlos darauf zurückgeführt werden.
8. Sobald die gesamte Instanz beendet ist, ist der Status "Abgeschlossen" für den Cluster erreicht.
Architektur für AWS EMR
Die Architektur von EMR stellt sich vom Speicherteil bis zum Anwendungsteil vor.
- Die allererste Schicht enthält die Speicherschicht, die verschiedene Dateisysteme enthält, die in unserem Cluster verwendet werden. Sei es von HDFS über EMRFS bis hin zum lokalen Dateisystem. Diese werden alle für die Datenspeicherung über die gesamte Anwendung verwendet. Mithilfe dieser mit EMR gelieferten Technologien können die Zwischenergebnisse während der MapReduce-Verarbeitung zwischengespeichert werden.
- Die zweite Ebene enthält die Ressourcenverwaltung für den Cluster. Diese Ebene ist für die Ressourcenverwaltung für die Cluster und Knoten in der Anwendung verantwortlich. Dies ist im Grunde genommen das wichtigste Verwaltungsinstrument, um die Daten gleichmäßig über den Cluster zu verteilen und eine ordnungsgemäße Verwaltung zu gewährleisten. Das von EMR verwendete Standard-Ressourcenverwaltungstool ist YARN, das in Apache Hadoop 2.0 eingeführt wurde. Es verwaltet zentral die Ressourcen für mehrere Datenverarbeitungs-Frameworks. Es kümmert sich um alle Informationen, die für den ordnungsgemäßen Betrieb des Clusters erforderlich sind, von der Knotenintegrität bis zur Ressourcenverteilung mit Speicherverwaltung.
- Die dritte Ebene wird mit dem Datenverarbeitungs-Framework geliefert. Diese Ebene ist für die Analyse und Verarbeitung der Daten verantwortlich. Es gibt viele von EMR unterstützte Frameworks, die eine wichtige Rolle bei der parallelen und effizienten Datenverarbeitung spielen. Einige der unterstützten Frameworks, von denen wir wissen, dass sie APACHE HADOOP, SPARK, SPARK STREAMING usw. sind.
- Die vierte Schicht besteht aus der Anwendung und Programmen wie HIVE, PIG, Streaming Library und ML-Algorithmen, die für die Verarbeitung und Verwaltung großer Datenmengen hilfreich sind.
Vorteile von AWS EMR
Lassen Sie uns nun einige Vorteile der Verwendung von EMR prüfen:
- Hohe Geschwindigkeit: Da alle Ressourcen ordnungsgemäß genutzt werden, ist die Verarbeitungszeit für die Abfrage vergleichsweise schneller als bei den anderen Datenverarbeitungstools.
- Massendatenverarbeitung: Größer als die Datenmenge EMR bietet die Möglichkeit, große Datenmengen in ausreichender Zeit zu verarbeiten.
- Minimaler Datenverlust: Da Daten über den Cluster verteilt und parallel über das Netzwerk verarbeitet werden, besteht eine minimale Wahrscheinlichkeit für Datenverlust, und die Genauigkeitsrate für die verarbeiteten Daten ist besser.
- Kostengünstig: Kostengünstig ist es billiger als jede andere Alternative, die es im Vergleich zur Industrie stark macht. Da die Preise niedriger sind, können wir über große Datenmengen verfügen und diese innerhalb des Budgets verarbeiten.
- AWS Integrated: Es ist in alle Dienste von AWS integriert, wodurch eine einfache Verfügbarkeit unter einem Dach gewährleistet wird, sodass Sicherheit, Speicherung und Vernetzung alles an einem Ort integriert sind.
- Sicherheit: Es gibt eine erstaunliche Sicherheitsgruppe zur Steuerung des eingehenden und ausgehenden Datenverkehrs. Durch die Verwendung von IAM-Rollen wird die Sicherheit erhöht, da verschiedene Berechtigungen für die Datensicherheit bereitgestellt werden.
- Überwachung und Bereitstellung: Wir verfügen über geeignete Überwachungstools für alle Anwendungen, die über EMR-Cluster ausgeführt werden. Dies macht sie transparent und erleichtert die Analyse. Außerdem ist eine Funktion zur automatischen Bereitstellung enthalten, mit der die Anwendung automatisch konfiguriert und bereitgestellt wird.
EMR ist eine bessere Wahl für andere Cluster-Berechnungsmethoden.
AWS EMR-Preise
EMR wird mit einer erstaunlichen Preisliste geliefert, die Entwickler oder den Markt anzieht. Da es mit einer On-Demand-Preisfunktion ausgestattet ist, können wir es auf einer Basis von etwas mehr als einer Stunde und mit einer Anzahl von Knoten in unserem Cluster verwenden. Wir können für jede Sekunde, die wir verwenden, eine Rate pro Sekunde zahlen, wobei mindestens eine Minute erforderlich ist. Wir können unsere Instanzen auch als Reserved Instances oder Spot Instances auswählen, wobei der Spot sehr kostensparend ist.
Wir können die Gesamtrechnung über einen einfachen Monatsrechner unter folgendem Link berechnen: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
Weitere Informationen zu den genauen Preisangaben finden Sie in der Dokumentation von Amazon: -
https://aws.amazon.com/emr/pricing/
Fazit
Im obigen Artikel haben wir gesehen, wie EMR für die faire Verarbeitung von Big Data verwendet werden kann, wobei alle Ressourcen konventionell genutzt werden.
EMR löst unser grundlegendes Problem der Datenverarbeitung und verkürzt die Verarbeitungszeit erheblich, da es kostengünstig und einfach zu handhaben ist.
Empfohlener Artikel
Dies war ein Leitfaden für AWS EMR. Hier diskutieren wir eine Einführung in AWS EMR in Bezug auf die Arbeitsweise und die Architektur sowie die Vorteile. Sie können auch unsere anderen Artikelvorschläge durchgehen, um mehr zu erfahren -
- AWS-Alternativen
- AWS-Befehle
- AWS-Dienste
- Fragen zu AWS-Vorstellungsgesprächen
- AWS Storage Services
- Top 7 Wettbewerber von AWS
- Liste der Amazon Web Services-Funktionen