
Einführung in die Ensemble-Techniken
Ensemble-Lernen ist eine Technik des maschinellen Lernens, bei der mehrere Basismodelle verwendet werden und deren Ausgabe zu einem optimierten Modell kombiniert wird. Diese Art von Algorithmus für maschinelles Lernen trägt zur Verbesserung der Gesamtleistung des Modells bei. Hier ist das am häufigsten verwendete Basismodell der Entscheidungsbaumklassifizierer. Ein Entscheidungsbaum funktioniert im Grunde genommen nach mehreren Regeln und liefert eine prädiktive Ausgabe, wobei die Regeln die Knoten sind und deren Entscheidungen ihre Kinder sind und die Blattknoten die endgültige Entscheidung darstellen. Wie im Beispiel eines Entscheidungsbaums gezeigt.
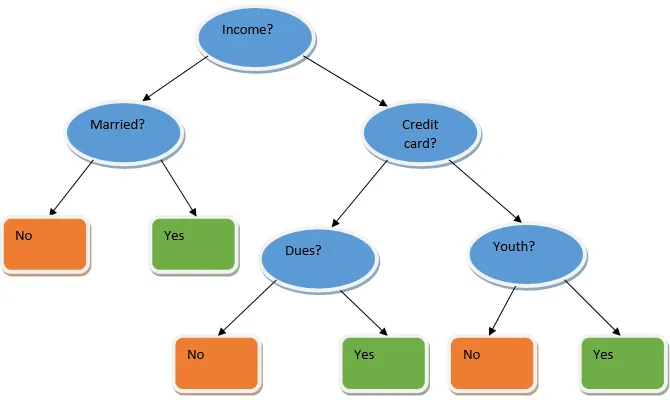
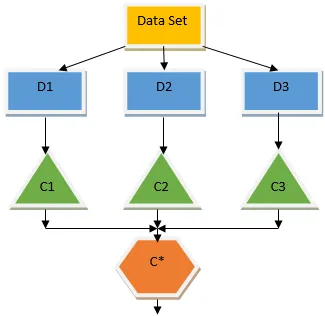
Der obige Entscheidungsbaum befasst sich im Wesentlichen mit der Frage, ob eine Person / ein Kunde einen Kredit erhalten kann oder nicht. Eine der Regeln für die Darlehensberechtigung lautet: Wenn (Einkommen = Ja && Verheiratet = Nein), dann Darlehen = Ja, dann funktioniert ein Entscheidungsbaumklassifizierer wie folgt. Wir werden diese Klassifikatoren als ein Modell mit mehreren Basen integrieren und ihre Ausgabe kombinieren, um ein optimales Vorhersagemodell zu erstellen. Abbildung 1.b zeigt das Gesamtbild eines Ensemble-Lernalgorithmus.
Arten von Ensemble-Techniken
Verschiedene Arten von Ensembles, aber unser Hauptaugenmerk liegt auf den beiden folgenden Arten:
- Absacken
- Erhöhen
Diese Methoden tragen dazu bei, die Varianz und Verzerrung in einem maschinellen Lernmodell zu verringern. Versuchen wir nun zu verstehen, was Voreingenommenheit und Varianz sind. Bias ist ein Fehler, der aufgrund falscher Annahmen in unserem Algorithmus auftritt. Eine hohe Abweichung zeigt an, dass unser Modell zu einfach / zu wenig ausgestattet ist. Varianz ist der Fehler, der durch die Empfindlichkeit des Modells gegenüber sehr kleinen Schwankungen im Datensatz verursacht wird. Eine hohe Varianz zeigt an, dass unser Modell sehr komplex ist. Ein ideales ML-Modell sollte ein ausgewogenes Verhältnis zwischen Verzerrung und Varianz aufweisen.
Bootstrap Aggregieren / Absacken
Bagging ist eine Ensemble-Technik, die hilft, die Varianz in unserem Modell zu verringern und somit eine Überanpassung zu vermeiden. Das Absacken ist ein Beispiel für den parallelen Lernalgorithmus. Das Absacken basiert auf zwei Prinzipien.
- Bootstrapping: Ausgehend vom Originaldatensatz werden beim Ersetzen unterschiedliche Stichprobenpopulationen berücksichtigt.
- Aggregieren: Die Ergebnisse aller Klassifikatoren werden gemittelt und es wird eine einzige Ausgabe bereitgestellt. Bei der Klassifizierung wird die Mehrheit der Stimmen verwendet, bei dem Regressionsproblem wird der Durchschnitt gebildet. Einer der berühmten Algorithmen für maschinelles Lernen, die das Konzept des Absackens verwenden, ist ein zufälliger Wald.
Zufälliger Wald
Im Zufallswald wird aus der aus der Population entnommenen Zufallsstichprobe mit Ersetzung und einer Teilmenge von Merkmalen aus der Menge aller Merkmale eine Entscheidungsbaumstruktur erstellt. Aus diesen Untergruppen von Merkmalen wird dasjenige Merkmal als Stamm für den Entscheidungsbaum ausgewählt, das die beste Aufteilung ergibt. Die Teilmenge der Features muss um jeden Preis zufällig ausgewählt werden, da sonst nur korrelierte Locken entstehen und die Varianz des Modells nicht verbessert wird.
Jetzt haben wir unser Modell mit den Stichproben aus der Grundgesamtheit erstellt. Die Frage ist, wie wir das Modell validieren können. Da wir die Muster mit Ersatz betrachten, werden nicht alle Muster berücksichtigt und ein Teil davon wird in keinem Beutel enthalten sein. Diese werden als Out-of-Bag-Muster bezeichnet. Wir können unser Modell mit diesen OOB-Mustern (Out-of-Bag-Mustern) validieren. Die wichtigen Parameter, die in einer zufälligen Gesamtstruktur berücksichtigt werden müssen, sind die Anzahl der Stichproben und die Anzahl der Bäume. Betrachten wir 'm' als die Teilmenge der Features und 'p' als die vollständige Menge der Features. Als Faustregel ist es immer ideal, eine Auswahl zu treffen
- m als und eine minimale Knotengröße als 1 für ein Klassifizierungsproblem.
- m als P / 3 und minimale Knotengröße 5 für ein Regressionsproblem.
M und p sollten als Abstimmungsparameter behandelt werden, wenn wir uns mit einem praktischen Problem befassen. Das Training kann beendet werden, sobald sich der OOB-Fehler stabilisiert hat. Ein Nachteil der zufälligen Gesamtstruktur besteht darin, dass dieser Algorithmus eine schlechte Leistung erbringt, wenn wir 100 Features in unserem Datensatz haben und nur ein paar Features wichtig sind.
Erhöhen
Boosting ist ein sequentieller Lernalgorithmus, der dazu beiträgt, die Verzerrung in unserem Modell und die Varianz in einigen Fällen von überwachtem Lernen zu verringern. Es hilft auch dabei, schwache Lernende in starke Lernende zu verwandeln. Boosting funktioniert nach dem Prinzip, dass die schwachen Lernenden nacheinander platziert werden und jedem Datenpunkt nach jeder Runde ein Gewicht zugewiesen wird. In der vorherigen Runde wird dem falsch klassifizierten Datenpunkt mehr Gewicht zugewiesen. Diese sequentiell gewichtete Methode zum Trainieren unseres Datensatzes ist der Hauptunterschied zu der beim Absacken.
Abb. 3a zeigt den allgemeinen Ansatz beim Boosten
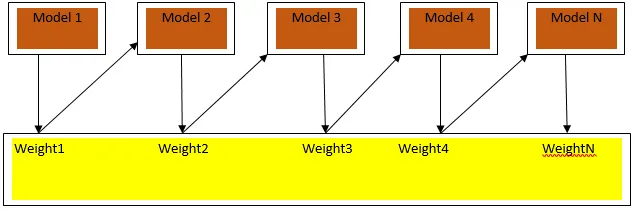
Die endgültigen Vorhersagen werden auf der Grundlage der gewichteten Mehrheit im Fall der Klassifizierung und der gewichteten Summe im Fall der Regression kombiniert. Der am weitesten verbreitete Boosting-Algorithmus ist das adaptive Boosting (Adaboost).
Adaptives Boosten
Der Adaboost-Algorithmus umfasst die folgenden Schritte:
- Für die angegebenen n Datenpunkte definieren wir die Zielklasse und initialisieren alle Gewichte auf 1 / n.
- Wir passen die Klassifikatoren an den Datensatz an und wählen die Klassifikation mit dem geringsten gewichteten Klassifikationsfehler
- Wir weisen dem Klassifikator Gewichte nach einer Faustregel zu, die auf der Genauigkeit basiert. Wenn die Genauigkeit mehr als 50% beträgt, ist das Gewicht positiv und umgekehrt.
- Wir aktualisieren die Gewichte der Klassifikatoren am Ende der Iteration. Wir aktualisieren mehr Gewicht für den falsch klassifizierten Punkt, sodass wir ihn in der nächsten Iteration richtig klassifizieren.
- Nach all der Iteration erhalten wir das endgültige Vorhersageergebnis basierend auf der Mehrheitsabstimmung / dem gewichteten Durchschnitt.
Adaboosting funktioniert effizient mit schwachen (weniger komplexen) Lernenden und mit Klassifikatoren mit hoher Verzerrung. Die Hauptvorteile von Adaboosting sind, dass es schnell ist, es keine ähnlichen Abstimmungsparameter wie beim Absacken gibt und wir keine Annahmen bei schwachen Lernenden treffen. Diese Technik liefert kein genaues Ergebnis, wenn
- Unsere Daten enthalten mehr Ausreißer.
- Der Datensatz ist nicht ausreichend.
- Die schwachen Lernenden sind sehr komplex.
Sie sind auch anfällig für Lärm. Die Entscheidungsbäume, die durch Boosten erzeugt werden, weisen eine begrenzte Tiefe und eine hohe Genauigkeit auf.
Fazit
Ensemble-Lerntechniken werden häufig zur Verbesserung der Modellgenauigkeit eingesetzt. wir müssen uns auf der Grundlage unseres Datensatzes für eine Technik entscheiden. In einigen Fällen, in denen die Interpretierbarkeit von Bedeutung ist, werden diese Techniken jedoch nicht bevorzugt, da wir die Interpretierbarkeit auf Kosten der Leistungsverbesserung verlieren. Diese haben eine enorme Bedeutung in der Gesundheitsbranche, wo eine kleine Leistungssteigerung sehr wertvoll ist.
Empfohlene Artikel
Dies ist eine Anleitung zu Ensemble-Techniken. Hier diskutieren wir die Einführung und zwei Haupttypen von Ensemble-Techniken. Sie können auch unsere anderen verwandten Artikel durchgehen, um mehr zu erfahren.
- Steganographie-Techniken
- Maschinelles Lernen
- Teambuilding-Techniken
- Datenwissenschaftliche Algorithmen
- Meist verwendete Techniken des Ensemble-Lernens